Introducing Feast: an open source feature store for machine learning
Tim Sell
Strategic Cloud Engineer
Willem Pienaar
Data Science Platform Lead at GO-JEK
To operate machine learning systems at scale, teams need to have access to a wealth of feature data to both train their models, as well as to serve them in production. GO-JEK and Google Cloud are pleased to announce the release of Feast, an open source feature store that allows teams to manage, store, and discover features for use in machine learning projects.
Developed jointly by GO-JEK and Google Cloud, Feast aims to solve a set of common challenges facing machine learning engineering teams by becoming an open, extensible, unified platform for feature storage. It gives teams the ability to define and publish features to this unified store, which in turn facilitates discovery and feature reuse across machine learning projects.
“Feast is an essential component in building end-to-end machine learning systems at GO-JEK,” says Peter Richens, Senior Data Scientist at GO-JEK, “we are very excited to release it to the open source community. We worked closely with Google Cloud in the design and development of the product, and this has yielded a robust system for the management of machine learning features, all the way from idea to production.”
For production deployments, machine learning teams need a diverse set of systems working together. Kubeflow is a project dedicated to making these systems simple, portable and scalable and aims to deploy best-of-breed open-source systems for ML to diverse infrastructures. We are currently in the process of integrating Feast with Kubeflow to address the feature storage needs inherent in the machine learning lifecycle.
The motivation
Feature data are signals about a domain entity, e.g: for GO-JEK, we can have a driver entity and a feature of the daily count of trips completed. Other interesting features might be the distance between the driver and a destination, or the time of day. A combination of multiple features are used as inputs for a machine learning model.
In large teams and environments, how features are maintained and served can diverge significantly across projects and this introduces infrastructure complexity, and can result in duplicated work.
Typical challenges:
- Features not being reused: Features representing the same business concepts are being redeveloped many times, when existing work from other teams could have been reused.
- Feature definitions vary: Teams define features differently and there is no easy access to the documentation of a feature.
- Hard to serve up to date features: Combining streaming and batch derived features, and making them available for serving, requires expertise that not all teams have. Ingesting and serving features derived from streaming data often requires specialised infrastrastructure. As such, teams are deterred from making use of real time data.
- Inconsistency between training and serving: Training requires access to historical data, whereas models that serve predictions need the latest values. Inconsistencies arise when data is siloed into many independent systems requiring separate tooling.
Our solution
Feast solves these challenges by providing a centralized platform on which to standardize the definition, storage and access of features for training and serving. It acts as a bridge between data engineering and machine learning.
Feast handles the ingestion of feature data from both batch and streaming sources. It also manages both warehouse and serving databases for historical and the latest data. Using a Python SDK, users are able to generate training datasets from the feature warehouse. Once their model is deployed, they can use a client library to access feature data from the Feast Serving API.
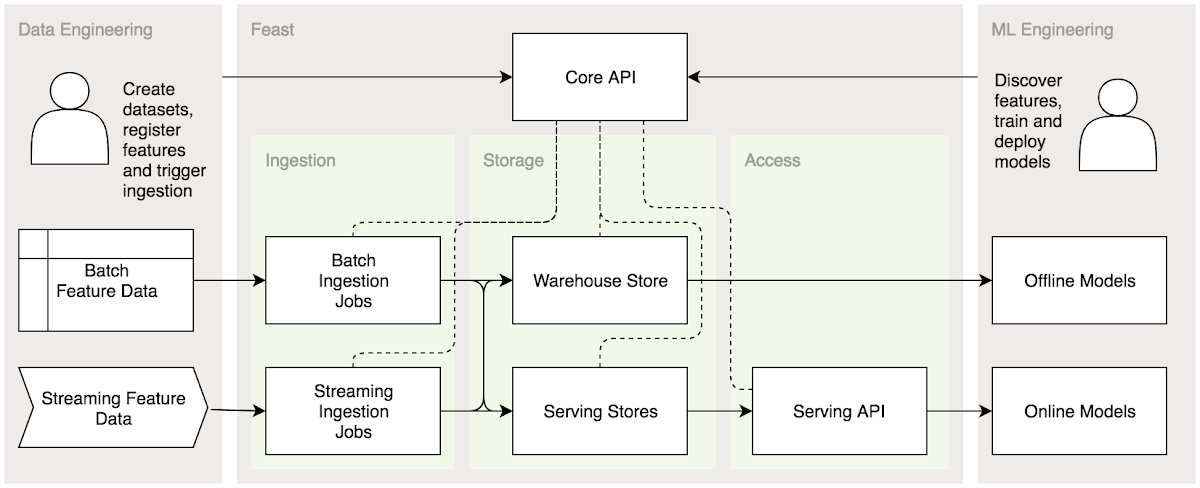
Feast provides the following:
- Discoverability and reuse of features: A centralized feature store allows organizations to build up a foundation of features that can be reused across projects. Teams are then able to utilize features developed by other teams, and as more features are added to the store it becomes easier and cheaper to build models.
- Access to features for training: Feast allows users to easily access historical feature data. This allows users to produce datasets of features for use in training models. ML practitioners can then focus more on modelling and less on feature engineering.
- Access to features in serving: Feature data is also available to models in production through a feature serving API. The serving API has been designed to provide low latency access to the latest feature values.
- Consistency between training and serving: Feast provides consistency by managing and unifying the ingestion of data from batch and streaming sources, using Apache Beam, into both the feature warehouse and feature serving stores. Users can query features in the warehouse and the serving API using the same set of feature identifiers.
- Standardization of features: Teams are able to capture documentation, metadata and metrics about features. This allows teams to communicate clearly about features, test features data, and determine if a feature is useful for a particular model.
Kubeflow
There is a growing ecosystem of tools that attempt to productionize machine learning. A key open source ML platform in this space is Kubeflow, which has focused on improving packaging, training, serving, orchestration, and evaluation of models. Companies that have built successful internal ML platforms have identified that standardizing feature definitions, storage, and access, was critical to that success.
For this reason, Feast aims to be both deployable on Kubeflow and to integrate seamlessly with other Kubeflow components. This includes a Python SDK for use with Kubeflow's Jupyter notebooks, as well as Kubeflow Pipelines.
There is a Kubeflow GitHub issue here that allows for discussion of future Feast integration.
How you can contribute
Feast provides a consistent way to access features that can be passed into serving models, and to access features in batch for training. We hope that Feast can act as a bridge between your data engineering and machine learning teams, and we would love to hear your feedback via our GitHub project. For additional ways to contribute:
- Find the Feast project on GitHub repository here
- Join the Kubeflow community and find us on Slack
Let the Feast begin!



