Pub/Sub Group Kafka Connector now GA: a drop-in solution for data movement
Samarth Singal
Software Engineer
Tianzi Cai
Developer Relations Engineer
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialWe’re excited to announce that the Pub/Sub Group Kafka Connector is now Generally Available with active support from the Google Cloud Pub/Sub team. The Connector (packaged in a single jar file) is fully open source under an Apache 2.0 license and hosted on our GitHub repository. The packaged binaries are available on GitHub and Maven Central.
The source and sink connectors packaged in the Connector jar allow you to connect your existing Apache Kafka deployment to Pub/Sub or Pub/Sub Lite in just a few steps.
Simplifying data movement
As you migrate to the cloud, it can be challenging to keep systems deployed on Google Cloud in sync with those running on-premises. Using the sink connector, you can easily relay data from an on-prem Kafka cluster to Pub/Sub or Pub/Sub Lite, allowing different Google Cloud services as well as your own applications hosted on Google Cloud to consume data at scale. For instance, you can stream Pub/Sub data straight to BigQuery, enabling analytics teams to perform their workloads on BigQuery tables.
If you have existing analytics tied to your on-prem Kafka cluster, you can easily bring any data you need from microservices deployed on Google Cloud or your favorite Google Cloud services using the source connector. This way you can have a unified view across your on-prem and Google Cloud data sources.
The Pub/Sub Group Kafka Connector is implemented using Kafka Connect, a framework for developing and deploying solutions that reliably stream data between Kafka and other systems. Using Kafka Connect opens up the rich ecosystem of connectors for use with Pub/Sub or Pub/Sub Lite. Search your favorite source or destination system on Confluent Hub.
Flexibility and scale
You can configure exactly how you want messages from Kafka to be converted to Pub/Sub messages and vice versa with the available configuration options. You can also choose your desired Kafka serialization format by specifying which key/value converters to use. For use cases where message order is important, the sink connectors transmit the Kafka record key as the Pub/Sub message `ordering_key`, allowing you to use Pub/Sub ordered delivery and ensuring compatibility with Pub/Sub Lite order guarantees. To keep the message order when sending data to Kafka using the source connector, you can set the Kafka record key as a desired field.
The Connector can also take advantage of Pub/Sub’s and Pub/Sub Lite’s high-throughput messaging capabilities and scale up or down dynamically as stream throughput requires. This is achieved by running the Kafka Connect cluster in distributed mode. In distributed mode, Kafka Connect runs multiple worker processes on separate servers, each of which can host source or sink connector tasks. Configuring the `tasks.max` setting to greater than 1 allows Kafka Connect to enable parallelism and shard relay work for a given Kafka topic across multiple tasks. As message throughput increases, Kafka Connect spawns more tasks, increasing concurrency and thereby increasing total throughput.
A better approach
Compared to existing ways of transmitting data between Kafka and Google Cloud, the connectors are a step-change.
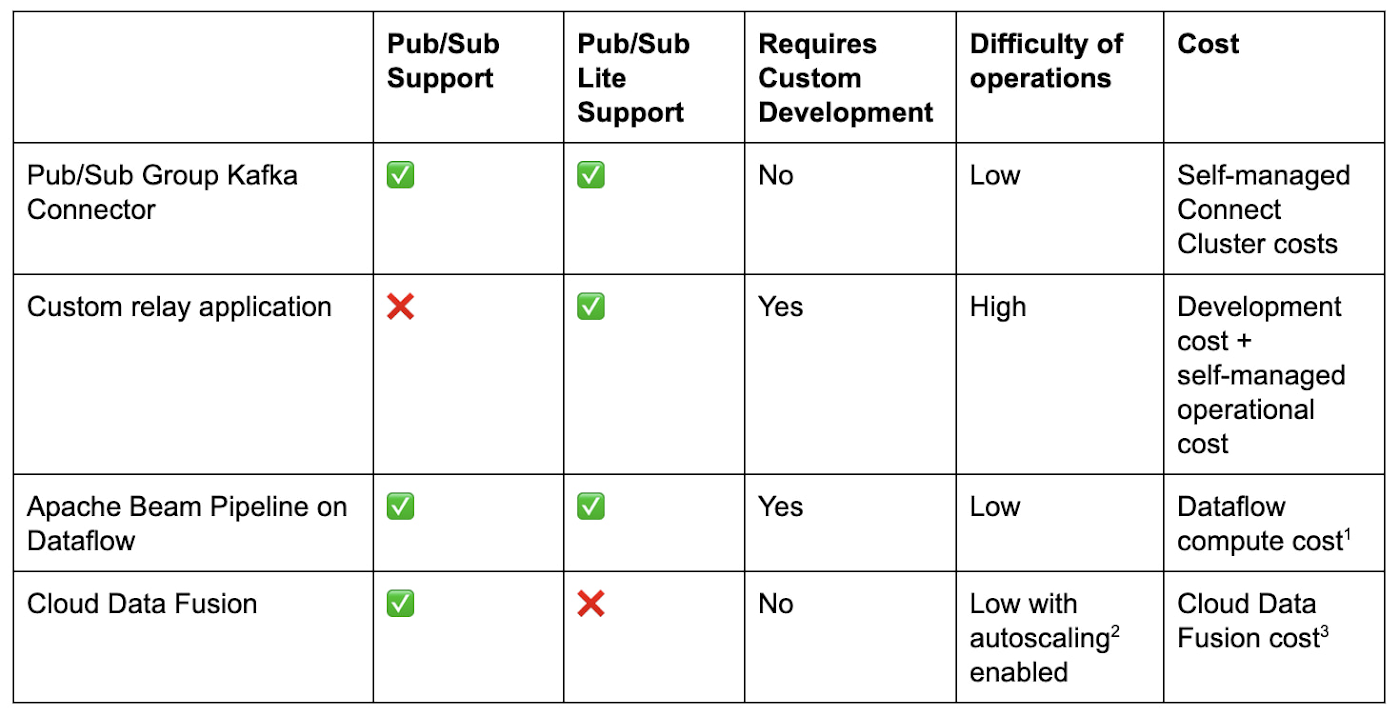
To connect Kafka to Pub/Sub or Pub/Sub Lite, one option is to write a custom relay application to read data from the source and write to the destination system. For developers with Kafka experience who want to connect to Pub/Sub Lite, we provide a Kafka Shim Client that can make the task of consuming from and producing to a Pub/Sub Lite topic easier using the familiar Kafka API. This approach has a couple of downsides. It can take significant effort to develop and can be challenging for high-throughput use-cases since there is no out-of-the-box horizontal scaling. You’ll also need to learn to operate this custom solution from scratch and add any monitoring to ensure data is relayed smoothly. Instead there are easier options to build or deploy using existing frameworks.
Pub/Sub, Pub/Sub Lite, and Kafka all have respective I/O connectors with Apache Beam. You can write a Beam pipeline using KafkaIO to move data between a cluster Pub/Sub or Pub/Sub Lite and then run it on an execution engine like Dataflow. This requires some familiarity with the Beam programming model, writing code to create the pipeline and possibly expanding your architecture to a supported runner like Dataflow. Using the Beam programming model with Dataflow gives you the flexibility to perform transformations on streams connecting your Kafka cluster to Pub/Sub or to create complex topologies like fan-out to multiple topics. For simple data movement especially when using an existing Connect cluster, however, the connectors offer a simpler experience requiring no development and low-operational overhead.
No code is required to set up a data integration pipeline in Cloud Data Fusion between Kafka and Pub/Sub, thanks to plugins that support all three products. Like a Beam pipeline that must execute somewhere, a Data Fusion pipeline needs to execute on a Cloud Dataproc cluster. It is a valid option most suitable for Cloud-native data practitioners who prefer drag-and-drop option in a GUI and who do not manage Kafka clusters directly. If you do manage Kafka clusters already, you may prefer a native solution, i.e., deploying the connector directly into a Kafka Connect cluster between your sources/sinks and your Kafka cluster, for more direct control.
To give the Pub/Sub connector a try, head over to the how-to guide.
1. Dataflow compute cost. 2. autoscaling. 3. Cloud Data Fusion cost

