Help for slow Hadoop/Spark jobs on Google Cloud: 10 questions to ask about your Hadoop and Spark cluster performance
Dennis Huo
Software Engineer, Google Cloud
Christopher Crosbie
Group Product Manager
A single, pointed question faces many first time Hadoop-in-the-cloud users: Is this the performance I should expect? Customers sometimes deploy a proof-of-concept or move their first data set over to Cloud Storage, and then kick off their Hadoop and Spark jobs only to find performance far below their expectations. Almost always, it’s possible to quickly and efficiently restore the performance to your deployment.
Here at Google Cloud, we have spent countless hours troubleshooting Hadoop and Spark performance concerns. Most often, we are able to root-cause the issue down to a handful of basic cloud architecture missteps that you can resolve relatively quickly. In today’s post, we will share the top ten questions that we use to diagnose Hadoop and Spark performance concerns. Answering these ten questions can help you improve your Hadoop and Spark job performance on Google Cloud Platform.
We will break our set of questions into two areas. The first set of questions apply to any distribution of Hadoop, including Cloud Dataproc, Google’s fast and simple, fully-managed cloud service for running Apache Spark and Apache Hadoop clusters. The second set of performance implications would only apply to non-managed Hadoop distributions running on Google Compute Engine.
Hadoop and Spark Performance questions for all cluster architectures (Dataproc included)
Question 1: Where is your data, and where is your cluster?
Our first question really comes in two parts, but knowing your data locality can have a major impact on your performance. You want to be sure that your data’s region and your cluster’s zone are physically close in distance.
When using Cloud Dataproc, you can omit the zone and have Cloud Dataproc’s Auto Zone feature select a zone for you in the region you choose. While this handy feature can optimize on where to put your cluster, it does not know how to anticipate the location of the data your cluster will be accessing. Make sure that the Cloud Storage bucket is in the same regional location as your Dataproc region.
Question 2: Is your network traffic being funneled?
Be sure that you do not have any network rules or routes that funnel Cloud Storage traffic through a small number of VPN gateways before it reaches your cluster. There are large network pipes between Cloud Storage and Compute Engine. You don’t want to throttle your bandwidth by sending traffic into a bottleneck in your GCP networking configuration
Question 3: How many input files and Hadoop partitions are you trying to deal with?
Make sure you are not dealing with more than around 10,000 input files. If you find yourself in this situation, try to combine or “union” the data into larger file sizes.
If this file volume reduction means that now you are working with larger datasets (more than ~50k Hadoop partitions), you should consider adjusting the setting fs.gs.block.size to a larger value accordingly.
`fs.gs.block.size` is a configuration parameter that helps jobs perform splits. When used in conjunction with Cloud Storage data, it becomes a "fake" value since Cloud Storage does not expose actual block sizes. The default value of 64MB is solely for helping Hadoop decide how to perform splits. Therefore, if the files are larger than 512MB, you may find that you can achieve better performance by manually increasing this value up to 1GB or even 2GB.
Question 4: Is the size of your persistent disk limiting your throughput?
Often times, when getting started with Google Cloud, you may have just a small table that you want to benchmark. This is generally a good approach, as long as you do not choose a persistent disk that is sized to such a small quantity of data; it will most likely limit your performance. Standard persistent disks scale linearly with volume size. The table below shows an abbreviation of this scaled performance, while the full table can be found here.
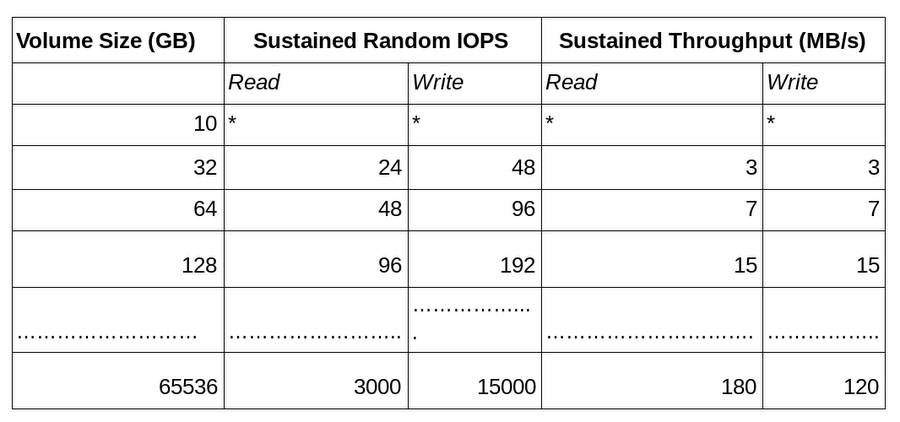
Question 5: Did you allocate enough virtual machines (VMs) to your cluster?
A question that often comes up when migrating from on-premises hardware to Google Cloud is how to accurately size the number of virtual machines needed. Understanding your workloads is key to identifying a cluster size. Running prototypes and benchmarking with real data and real jobs is crucial to informing the actual VM allocation decision. Luckily, the ephemeral nature of the cloud makes it easy to “right-size” clusters for the specific task at hand instead of trying to purchase hardware up front. Thus, you can easily resize your cluster as needed. Employing job-scoped clusters is a common strategy for Dataproc clusters.
Even though we know that clusters can easily scale up or down, it can still be useful to have some back-of-the-napkin calculations as we approach our cluster sizes. For an example calculation, let’s say that we are migrating from 50 physical nodes, each with 12 physical cores and 2 hyperthreads per core.
It’s important to understand that on Compute Engine, each virtual CPU (vCPU) is implemented as a single hardware hyper-thread on one of the available CPU platforms. In our example of 50 nodes each with 12 physical cores, you would need to provision 1,200 vCPUs. On Compute Engine, you have two options for configuring these 1,200 vCPUs:
Option 1: 300 4-vCPU VMs (300 n1-standard-4)
Option 2: 150 8-vCPU VMs (150 n1-standard-8)
When considering which option to choose, it's also important to factor in the storage implications associated with the choice. There are limits to the total amount of persistent disk that you can add to each VM. Most instance types have a 64TB limit. In our example, we should consider if this is enough or if we would prefer to have more VMs and thus, increase our storage size. Since customers typically move the vast majority of their long-term data storage from HDFS into Cloud Storage when they migrate to the cloud, usually the persistent drive limits are more than sufficient. However, you might still want to consider your specific workloads. Some storage requirements worth investigating include:
HBase data, including replication
Un-replicated temporary shuffle spills
Intra-pipeline datasets produced in the middle of Hive queries, Pig scripts, Mahout jobs, or in other scenarios
Hadoop and Spark performance checklist for non-Dataproc clusters
Question 6: Are you using Hadoop version 2.7.0 or later?
In versions of Hadoop that fall between versions 2.0 and 2.7.x, the `FileOutputCommitter` function is much slower on Cloud Storage than HDFS. starting in Hadoop 2.7, a patch addresses this issue.
Note: this is not applicable to Dataproc customers since the fix has been applied to this service. Hadoop 1.X customers should also not face this issue.
Question 7: Are private IPs used for intra-cluster communication?
To communicate between instances on the same Virtual Private Cloud (VPC) network, you can use an instance's internal IP addresses. Make sure your cluster is configured to do all intra-cluster communication over the GCE instances’ internal IPs. Note that you should not use the external IP addresses, which are designed for explicitly for Internet communication. In addition to taking a slower network path, the external IPs also become expensive: private network communications are free, but using external IPs may trigger Internet egress rates.
Question 8: Is YARN packing leaving containers empty?
All of YARN’s schedulers will try to honor locality requests, but on a busy cluster, the requested node may be handling other requests and not respond promptly. The yarn.scheduler.capacity.node-locality-delay setting specifies the number of scheduling opportunities that YARN is willing to miss before giving up on the locality request and moving on to a different node. In Hadoop versions prior to 2.8.0, the default value for this setting was 40. Since Cloud Storage makes data appear to always reside on “localhost”, the YARN scheduler node locality delay will underutilize the nodes that are using Cloud Storage. To remedy this, simply set
You’ll want to be sure to reboot after setting this flag. This setting becomes the default starting in Hadoop 2.8.0, but if you find that your same cluster appears to be frequently underutilized with Cloud Storage but well-utilized with HDFS, you may benefit from experimenting with these YARN schedule properties.
Question 9: Are you using Java 8? If so, did you disable GCM in java.security?
Java 8 users may experience a 3x slowdown compared to Java 7 due to a very slow implementation of the cypher mode Galois/Counter Mode (GCM), an authenticated encryption mode that contains “additional data” used to compute an “authenticated tag”.
Starting in Java 8, the default GCM algorithms do not use the same hardware acceleration routines as previous versions of Java. So, if performance is a concern, you may want to disable it by setting:
Note: In the setting provided, SSLv3 is also disabled. This is the JDK default due to the POODLE vulnerability and not for Hadoop performance reasons.
Question 10: Are you on the latest version of the Cloud Storage Connector?
The Cloud Storage connector, open source utility that lets you run Hadoop or Spark jobs directly on data in Cloud Storage is updated with performance improvements on an ongoing basis. To make sure you are taking advantage of the latest performance improvements and bug fixes, try to stay as close as you can to the latest release.
Conclusion
We hope that this top ten list has provided architectural guidance for setting up efficient and performant Hadoop and Spark clusters on GCP. We also hope that the checklists provide basic elements to investigate your configuration if and when your job performance does not match your expectations. For more complex scenarios, Google Cloud is here to support. You can always get help with Google Cloud Dataproc when the performance tuning assistance you need goes beyond these basics.

