GKE plus Filestore - Improve training times for AI/ML workloads by up to 37%
Saikat Roychowdhury
Senior Software Engineer
Akshay Ram
Senior Product Manager
Problem statement and use case
Training AI/ML workloads requires a lot of data, which is often stored in large numbers of small files — think training driverless cars training numerous image data or performing protein analysis, where the training set often consists of numerous small files, sized 100K to 2MB each. When selecting tools for these use-cases, users often turn to Google’s Cloud Storage, which provides low latency and high throughput with reasonable price and performance, and optionally use FUSE as a file interface for portability. However, when the dataset is composed of small files, latency becomes an issue; a training workload can have tens-of-thousands of small file batches per epoch, as well as multiple worker nodes accessing Cloud Storage.
To accelerate load times, users need storage that provides low latency and high throughput. Using Filestore as an “accelerator” can help. Filestore provides fast-access file storage with all the benefits of multiple read/write access and a native POSIX interface. You can still leverage Cloud Storage as your primary storage source, and use Filestore to provide cost-effective, low-latency data access for your worker nodes.
In this blog post, we focus on the important role that Filestore can play in training AI/ML workloads, helping you make informed choices to accelerate your workload performance. Read on to learn how to use this solution according to personas and responsibilities:
Usage details
The following screenshots highlight how to use GKE and Filestore for your AI/ML applications. You can find the full source code in this repository.
Persona 1: Kubernetes Platform admin staging Filestore for use by data scientists
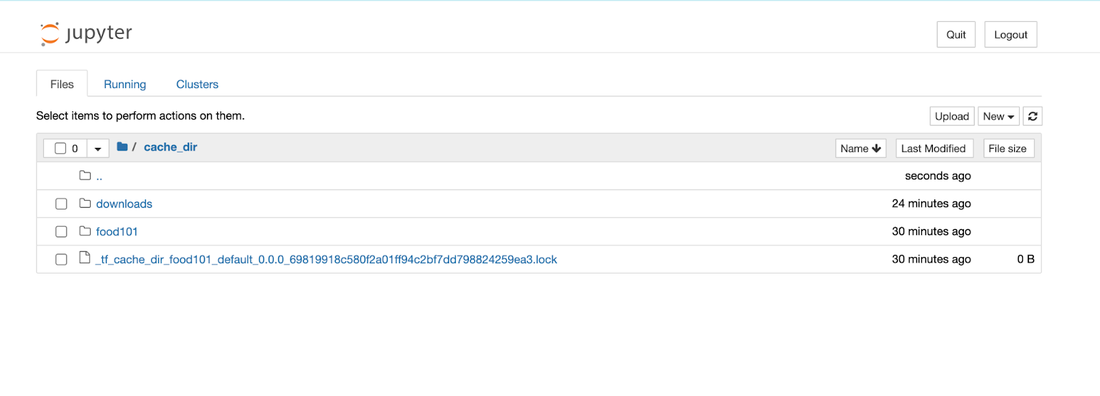
The Kubernetes platform admin is responsible for creating infrastructure for data science teams to consume. In this case, the platform admin sets up Filestore using a Kubernetes persistent volume and makes it accessible to data scientists via a Jupyter Notebook setup, or if working with multiple users, via JupyterHub. The data scientist can then simply access the notebook and write code.
For this specific example, we used the off-the-shelf premium-rwx GKE StorageClass, which dynamically provisions a Filestore Basic SSD instance under the hood. The Jupyter pod specification uses the GKE Filestore CSI driver to provision a PersistentVolumeClaim (PVC) which mounts a Filestore share to the Pod. The mounted volume path (which serves as a cache directory for data and models) is exposed as an environment variable to the data scientist (notebook user).
Screenshot 1: Tensorflow deployment with a Filestore volume

Screenshot 2: Filestore Persistent volume claim

Persona 2: Data scientist accessing data from the Jupyter Notebook
A data scientist simply wants to focus on running experiments. In this example, we train Google’s Vision Transformer Model (ViT) and load a food101 dataset from Hugging Face, which is primarily composed of 100k images totalling 5 GiB. We use Hugging Face’s cache feature, which automatically caches the data on the filesystem after first read. The file path needs to be shared with your data science teams as an environment variable. By passing the Filestore path as an environment variable, the data is cached on Filestore. Since the data is cached and not fetched from Cloud Storage, we run two epochs of training on a a2-highgpu-1g machine and compare training times directly from Cloud Storage (baseline), and observe a 37% improvement in training times!
Screenshot 3: Loading dataset from Hugging face and enabling caching
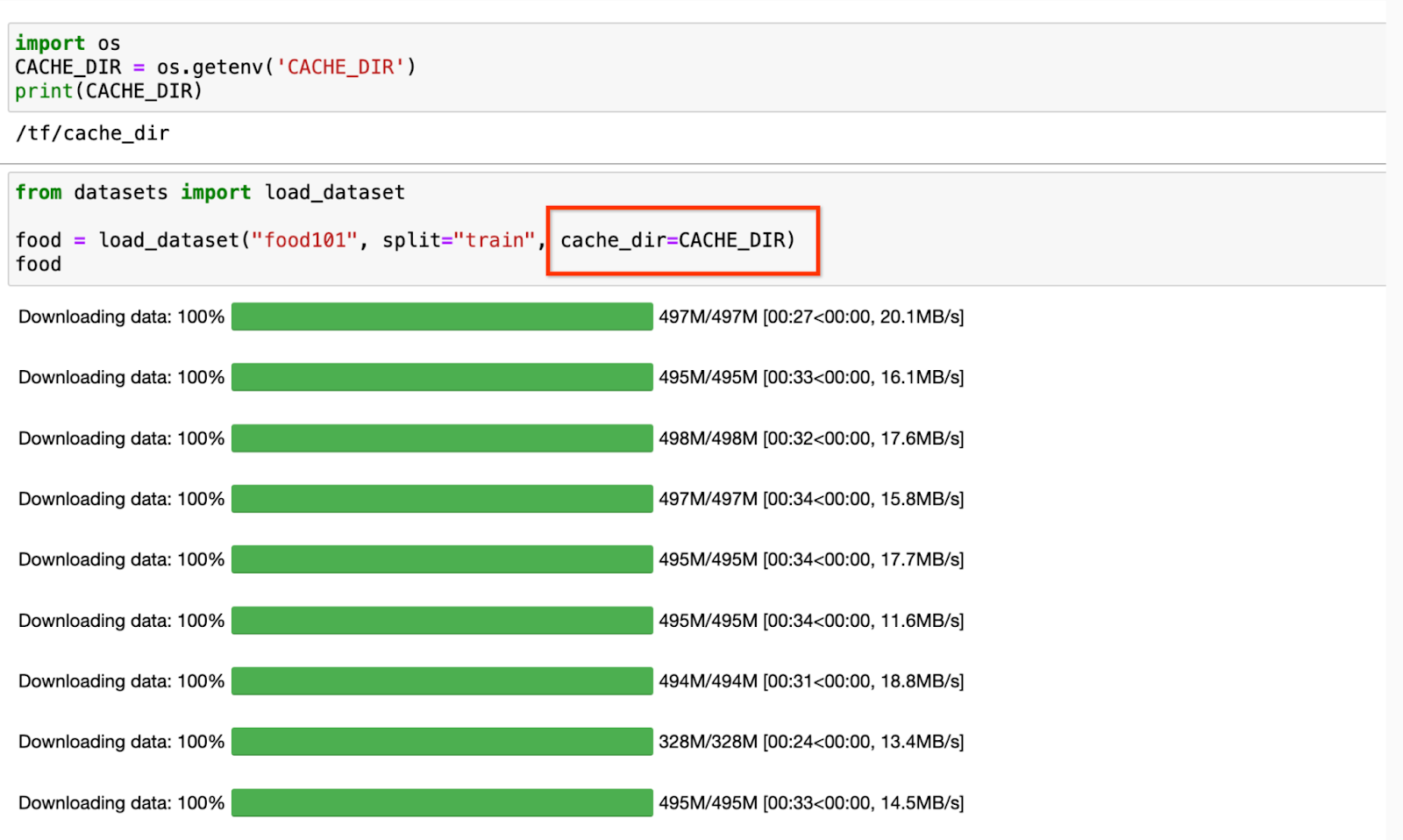
Screenshot 4: Jupyter notebook file explorer with mounted filestore directory
Screenshot 5,6,7: Download model, start training and measure training time
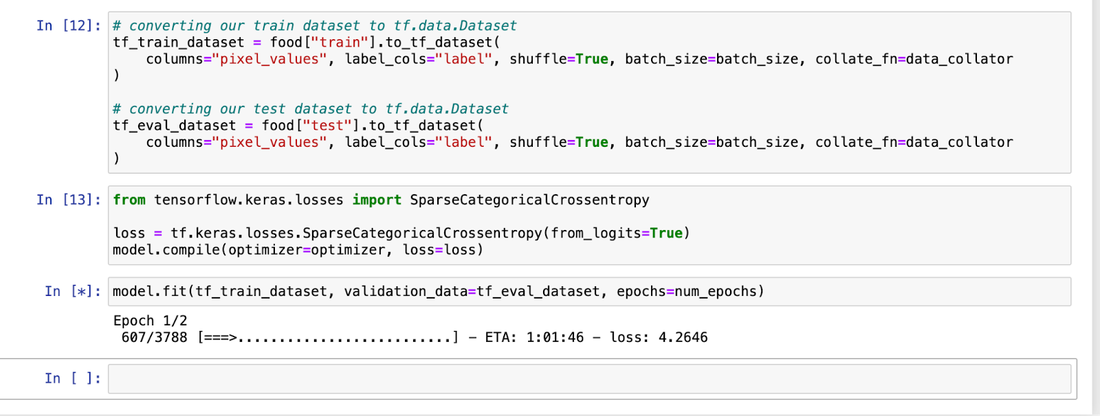
Table 1. Training results
|
Storage option |
Training Time (Secs) |
Improvement |
|
Cloud Storage |
4837 |
|
|
Filestore Basic SSD (Filestore Zonal High Band preferred) |
3006 |
37% |
Usage considerations
In this blog, we’ve highlighted the benefits of using Filestore as an accelerator in front of Cloud Storage, especially when your dataset is composed of numerous small files. You will be billed for Filestore Instances but the costs of storage may be well worth it when you can accelerate your training times (and GPU resource consumption). When files are larger sizes data directly from Cloud Storage may be a better fit. Choose the best architecture based on your use case.
