What’s new with Google Cloud’s AI Hypercomputer architecture

Mark Lohmeyer
VP & GM, Compute and AI Infrastructure
Advancements in AI are unlocking use-cases previously thought impossible. Larger and more complex AI models are enabling powerful capabilities across a full range of applications involving text, code, images, videos, voice, music, and more. As a result, leveraging AI has become an innovation imperative for businesses and organizations around the world, with the potential to boost human potential and productivity.
However, the AI workloads powering these exciting use-cases place incredible demands on the underlying compute, networking, and storage infrastructure. And that’s only one aspect of the architecture: customers also face the challenge of integrating open-source software, frameworks, and data platforms, while optimizing for resource consumption to harness the power of AI cost-effectively. Historically, this has required manually combining component-level enhancements, which can lead to inefficiencies and bottlenecks.
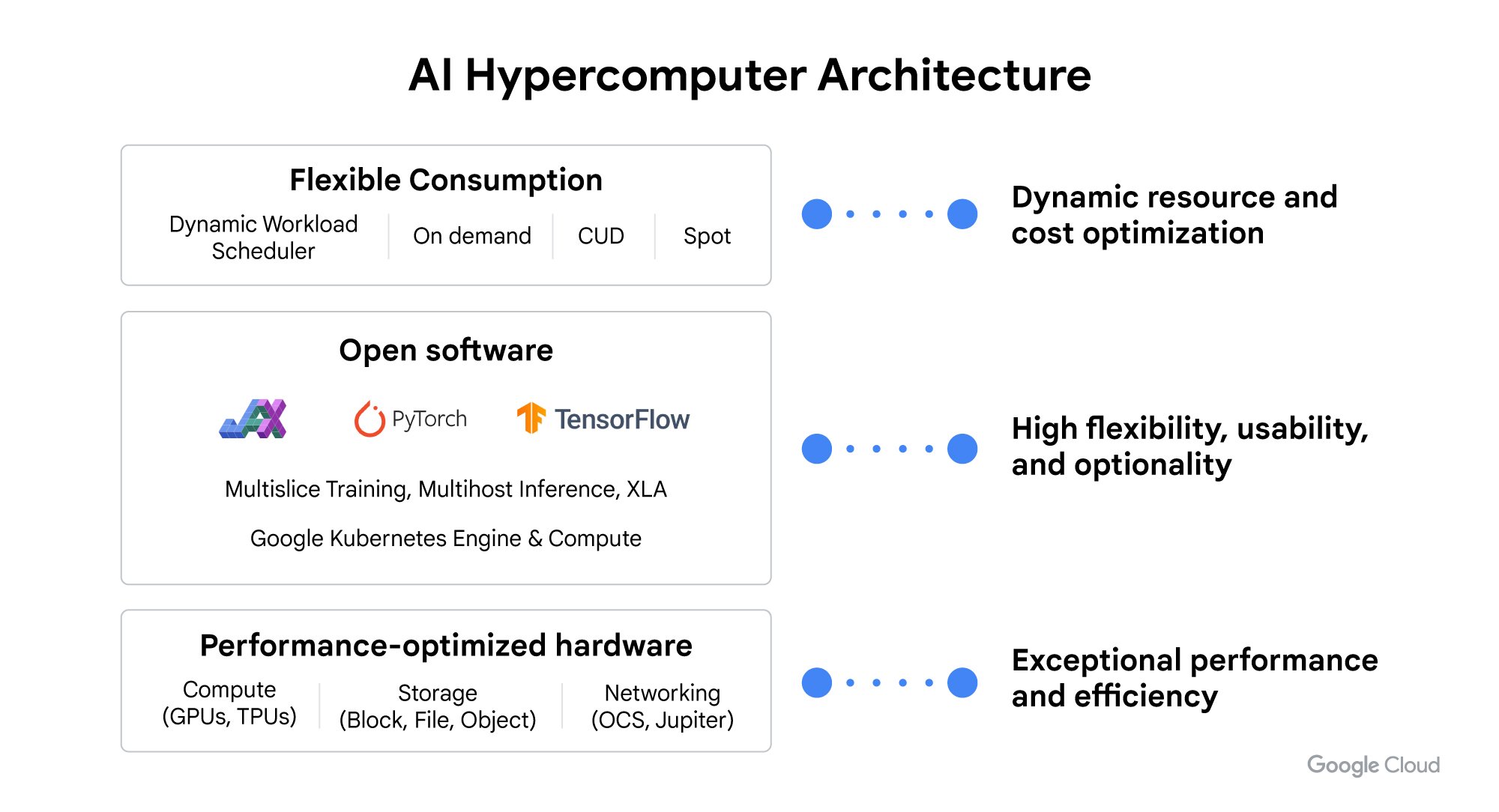
That’s why today we’re pleased to announce significant enhancements at every layer of our AI Hypercomputer architecture. This systems-level approach combines performance-optimized hardware, open software and frameworks, and flexible consumption models to enable developers and businesses to be more productive, because the overall system runs with higher performance and effectiveness, and the models generated are served more efficiently.
In fact, just last month, Forrester Research recognized Google as a Leader in The Forrester Wave™: AI Infrastructure Solutions1, Q1 2024, with the highest scores of any vendor evaluated in both the Current Offering and Strategy categories in this report.
The announcements we’re making today span every layer of the AI Hypercomputer architecture:
-
Performance-optimized hardware enhancements including the general availability of Cloud TPU v5p, and A3 Mega VMs powered by NVIDIA H100 Tensor Core GPUs, with higher performance for large-scale training with enhanced networking capabilities
-
Storage portfolio optimizations for AI workloads including Hyperdisk ML, a new block storage service optimized for AI inference/serving workloads, and new caching capabilities in Cloud Storage FUSE and Parallelstore, which improve training and inferencing throughput and latency
-
Open software advancements including the introduction of JetStream — a throughput- and memory-optimized inference engine for large language models (LLMs) that offers higher performance per dollar on open models like Gemma 7B, and JAX and PyTorch/XLA releases that improve performance on both Cloud TPUs and NVIDIA GPUs
-
New flexible consumption options with Dynamic Workload Scheduler, including calendar mode for start time assurance, and flex start mode for optimized economics
Learn more about AI Hypercomputer with a rare look inside one of our data centers:

Advances in performance-optimized hardware
Cloud TPU v5p GA
We’re thrilled to announce the general availability of Cloud TPU v5p, our most powerful and scalable TPU to date. TPU v5p is a next-generation accelerator that is purpose-built to train some of the largest and most demanding generative AI models. A single TPU v5p pod contains 8,960 chips that run in unison — over 2x the chips in a TPU v4 pod. Beyond the larger scale, TPU v5p also delivers over 2x higher FLOPS and 3x more high-bandwidth memory on a per chip basis. It also delivers near-linear improvement in throughput as customers use larger slices, achieving 11.97X throughput for a 12x increase in slice size (from 512 to 6144 chips).
Comprehensive GKE support for TPU v5p
To enable training and serving the largest AI models on GKE across large-scale TPU clusters, today we’re also announcing the general availability of both Google Kubernetes Engine (GKE) support for Cloud TPU v5p and TPU multi-host serving on GKE. TPU multi-host serving on GKE allows customers to manage a group of model servers deployed over multiple hosts as a single logical unit, so they can be managed and monitored centrally.
“By leveraging Google Cloud’s TPU v5p on Google Kubernetes Engine (GKE), Lightricks has achieved a remarkable 2.5X speed-up in training our text-to-image and text-to-video models compared to TPU v4. GKE ensures that we are able to smoothly leverage TPU v5p for the specific training jobs that need the performance boost.” - Yoav HaCohen, PhD, Core Generative AI Research Team Lead, Lightricks
Expanded NVIDIA H100 GPU capabilities with A3 Mega GA and Confidential Compute
We’re also expanding our NVIDIA GPU capabilities with additions to the A3 VM family, which now includes A3 Mega. A3 Mega, powered by NVIDIA H100 GPUs, will be generally available next month and offers double the GPU-to-GPU networking bandwidth of A3. Confidential Computing will also be coming to the A3 VM family, in preview later this year. Enabling confidential VMs on the A3 machine series protects the confidentiality and integrity of sensitive data and AI workloads and mitigates threats from unauthorized access. Enabling Confidential Computing on the A3 VM family encrypts the data transfers between the Intel TDX-enabled CPU and NVIDIA H100 GPU via protected PCIe, and requires no code changes.
Bringing NVIDIA Blackwell GPUs to Google Cloud
We also recently announced that we will be bringing NVIDIA’s newest Blackwell platform to our AI Hypercomputer architecture in two configurations. Google Cloud customers will have access to VMs powered by both the NVIDIA HGX B200 and GB200 NVL72 GPUs. The new VMs with HGX B200 GPU is designed for the most demanding AI, data analytics, and HPC workloads, while the upcoming VMs powered by the liquid-cooled GB200 NVL72 GPU will enable a new era of computing with real-time LLM inference and massive-scale training performance for trillion-parameter scale models.
Customers leveraging both Google Cloud TPU and GPU-based services
Character.AI is a powerful, direct-to-consumer AI computing platform where users can easily create and interact with a variety of characters. Character.AI is using Google Cloud’s AI Hypercomputer architecture across GPU- and TPU-based infrastructure to meet the needs of its rapidly growing community.
“Character.AI is using Google Cloud's Tensor Processor Units (TPUs) and A3 VMs running on NVIDIA H100 Tensor Core GPUs to train and infer LLMs faster and more efficiently. The optionality of GPUs and TPUs running on the powerful AI-first infrastructure makes Google Cloud our obvious choice as we scale to deliver new features and capabilities to millions of users. It’s exciting to see the innovation of next-generation accelerators in the overall AI landscape, including Google Cloud TPU v5e and A3 VMs with H100 GPUs. We expect both of these platforms to offer more than 2X more cost-efficient performance than their respective previous generations.” - Noam Shazeer, CEO, Character AI
Storage optimized for AI/ML workloads
To improve AI training, fine-tuning, and inference performance, we've added a number of enhancements to our storage products, including caching, which keeps the data closer to your compute instances, so you can train much faster. Each of these improvements also maximizes GPU and TPU utilization, leading to higher energy efficiency and cost optimization.
Cloud Storage FUSE (generally available) is a file-based interface for Google Cloud Storage that harnesses Cloud Storage capabilities for more complex AI/ML apps by providing file access to our high-performance, low-cost cloud storage solutions. Today we announced that new caching capabilities are generally available. Cloud Storge FUSE caching improves training throughput by 2.9X and improves serving performance for one of our own foundation models by 2.2X.
Parallelstore now also includes caching (in preview). Parallelstore is a high-performance parallel filesystem optimized for AI/ML and HPC workloads. New caching capabilities enable up to 3.9X faster training times and up to 3.7X higher training throughput, compared to native ML framework data loaders.
Filestore (generally available) is optimized for AI/ML models that require low latency, file-based data access. The network file system-based approach allows all GPUs and TPUs within a cluster to simultaneously access the same data, which improves training times by up to 56%, optimizing the performance of your AI workloads and boosting your most demanding AI projects.
We’re also pleased to introduce Hyperdisk ML in preview, our next-generation block storage service optimized for AI inference/serving workloads. Hyperdisk ML accelerates model load times up to 12X compared to common alternatives, and offers cost efficiency through read-only, multi-attach, and thin provisioning. It enables up to 2,500 instances to access the same volume and delivers up to 1.2 TiB/s of aggregate throughput per volume — over 100X greater performance than Microsoft Azure Ultra SSD and Amazon EBS io2 BlockExpress.
Advancements in our open software
Starting from frameworks and spanning the full software stack, we’re introducing open-source enhancements that enable customers to improve time-to-value for AI workloads by simplifying the developer experience while improving performance and cost efficiency.
JAX and high-performance reference implementations
We’re pleased to introduce MaxDiffusion, a new high-performance and scalable reference implementation for diffusion models. We’re also introducing new LLM models in MaxText, including Gemma, GPT3, LLAMA2 and Mistral across both Cloud TPUs and NVIDIA GPUs. Customers can jump-start their AI model development with these open-source implementations and then customize them further based on their needs.
MaxText and MaxDiffusion models are built on JAX, a cutting-edge framework for high-performance numerical computing and large-scale machine learning. JAX in turn is integrated with the OpenXLA compiler, which optimizes numerical functions and delivers excellent performance at scale, allowing model builders to focus on the math and let the software drive the most effective implementation. We’ve heavily optimized JAX and OpenXLA performance on Cloud TPU and also partnered closely with NVIDIA to optimize OpenXLA performance on large Cloud GPU clusters.
Advancing PyTorch support
As part of our commitment to PyTorch, support for PyTorch/XLA 2.3 will follow the upstream release later this month. PyTorch/XLA enables tens of thousands of PyTorch developers to get the best performance from XLA devices such as TPUs and GPUs, without having to learn a new framework. The new release brings features such as single program, multiple data (SPMD) auto-sharding, and asynchronous distributed checkpointing, making running a distributed training job much easier and more scalable.
And for PyTorch users in the Hugging Face community, we worked with Hugging Face to launch Optimum-TPU, a performance-optimized package that will help developers easily train and serve Hugging Face models on TPUs.
Jetstream: New LLM inference engine
We’re introducing Jetstream, an open-source, throughput- and memory-optimized LLM inference engine for XLA devices, starting with TPUs, that offers up to 3x higher inferences per dollar on Gemma 7B and other open models. As customers bring their AI workloads to production, there’s an increasing demand for a cost-efficient inference stack that delivers high performance. JetStream supports models trained with both JAX and PyTorch/XLA, and includes optimizations for popular open models such as Llama 2 and Gemma.
Open community models in collaboration with NVIDIA
Additionally, as part of the NVIDIA and Google collaboration with open community models, Google models will be available as NVIDIA NIM inference microservices to provide developers with an open, flexible platform to train and deploy using their preferred tools and frameworks.
New Dynamic Workload Scheduler modes
Dynamic Workload Scheduler is a resource management and job scheduling service that’s designed for AI workloads. Dynamic Workload Scheduler improves access to AI computing capacity and helps you optimize your spend for AI workloads by scheduling all the accelerators needed simultaneously, and for a guaranteed duration. Dynamic Workload Scheduler offers two modes: flex start mode (in preview) for enhanced obtainability with optimized economics, and calendar mode (in preview) for predictable job start times and durations.
Flex start jobs are cued to run as soon as possible, based on resource availability, making it easier to obtain TPU and GPU resources for jobs that have a flexible start time. Flex start mode is now integrated across Compute Engine Managed Instance Groups, Batch, and Vertex AI Custom Training, in addition to Google Kubernetes Engine (GKE). With flex start, you can now run thousands of AI/ML jobs with increased obtainability across the various TPU and GPU types offered in Google Cloud.
Calendar mode offers short-term reserved access to AI-optimized computing capacity. You can reserve collocated GPUs for up to 14 days, which can be purchased up to 8 weeks in advance. This new mode extends Compute Engine future reservation capabilities. Your reservations are confirmed, based on availability, and the capacity is delivered to your project on your requested start date. You can then simply create VMs targeting the capacity block for the entire duration of the reservation.
“Dynamic Workload Scheduler improved on-demand GPU obtainability by 80%, accelerating experiment iteration for our researchers. Leveraging the built-in Kueue and GKE integration, we were able to take advantage of new GPU capacity in Dynamic Workload Scheduler quickly and save months of development work.” - Alex Hays, Software Engineer, Two Sigma
AI anywhere with Google Distributed Cloud
The acceleration of AI adoption by enterprises has highlighted the need for flexible deployment options to process or securely analyze data closer to where it is generated. Google Distributed Cloud (GDC) brings the power of Google's cloud services wherever you need them — in your own data center or at the edge. Today we introduced several enhancements to GDC, including a generative AI search package solution powered by Gemma, an expanded ecosystem of partner solutions, new compliance certifications and more. Learn more about how to use GDC to run AI anywhere.
Our growing momentum with Google AI infrastructure
At Next this week we’re launching incredible AI innovation across everything from AI platforms and models to AI assistance with Gemini for Google Cloud — all underpinned by a foundation of AI-optimized infrastructure. All of this innovation is driving incredible momentum for our customers. In fact, nearly 90% of generative AI unicorns and more than 60% of funded gen AI startups are Google Cloud customers.
“Runway’s text-to-video platform is powered by AI Hypercomputer. At the base, A3 VMs, powered by NVIDIA H100 GPUs gave our training a significant performance boost over A2 VMs, enabling large-scale training and inference for our Gen-2 model. Using GKE to orchestrate our training jobs enables us to scale to thousands of H100s in a single fabric to meet our customers’ growing demand.” - Anastasis Germanidis, CTO and Co-Founder, Runway
"By moving to Google Cloud and leveraging the AI Hypercomputer architecture with G2 VMs powered by NVIDIA L4 GPUs and Triton Inference Server, we saw a significant boost in our model inference performance while lowering our hosting costs by 15% using novel techniques enabled by the flexibility that Google Cloud offers.” -Ashwin Kannan, Sr. Staff Machine Learning Engineer, Palo Alto Networks
"Writer's platform is powered by Google Cloud A3 and G2 VMs powered by NVIDIA H100 and L4 GPUs. With GKE we're able to efficiently train and inference over 17 large language models (LLMs) that scale up to over 70B parameters. We leverage Nvidia NeMo Framework to build our industrial strength models which generate 990,000 words a second with over a trillion API calls per month. We're delivering the highest quality inferencing models that exceed those from companies with larger teams and bigger budgets and all of that is possible with the Google and Nvidia partnership.” - Waseem Alshikh Cofounder and CTO, Writer
Learn more about AI Hypercomputer at the Next sessions below, and ask your sales representative about how you can apply these capabilities within your own organization.
- SPTL205 - Workload-optimized and AI-powered Infrastructure
- ARC108 - Take large scale AI from research to production with Google Cloud's AI Hypercomputer
- IHLT303 - How Lightricks is powering generative image models with Cloud TPUs and AI Hypercomputer
1. Forrester Research, The Forrester Wave™: AI Infrastructure Solutions, Q1 2024, Mike Gualtieri, Sudha Maheshwari, Sarah Morana, Jen Barton, March 17, 2024
The Forrester Wave™ is copyrighted by Forrester Research, Inc. Forrester and Forrester Wave™ are trademarks of Forrester Research, Inc. The Forrester Save is a graphical representation of Forrester’s call on a market and is plotted using a detailed spreadsheet with exposed scores, weightings, and comments. Forrester does not endorse any vendor, product, or service depicted in the Forrester Wave™. Information is based on the best available resources. Opinions reflect judgment at the time and are subject to change.