How Vertex AI empowered our Supply Chain Science team at Wayfair
Eldar Erkinbek Uulu
Senior Data Scientist, Wayfair
Ilia Ivanov
Senior Data Scientist, Wayfair
For the past few years, Wayfair has been migrating from its on-premises data centers to Google Cloud. As part of this transition, we explored Vertex AI as an end-to-end ML platform and adopted several of its components, including Vertex AI Pipelines, Training and Feature Store as our preferred solution for new ML solutions going forward. Building on top of that work, our team decided to migrate our existing use cases to Vertex AI to fully benefit from the Google Cloud ecosystem and solve some issues that arose while using our legacy tooling. We detailed the engineering and MLOps aspects of that transition in this previous blog post.
Below we share our perspective as data scientists describing our transition to Vertex AI. We’ll do that through an example — our delivery-time prediction use case.
Optimizing data collection with Vertex AI
Every data science solution starts with data. In the case of delivery-time prediction, we merge data from multiple sources: transactional data, delivery scans, information about suppliers and carriers which fulfill the orders and so forth. This routine is computationally expensive to execute every time we need training data, so we collect and aggregate the core data daily. Before migrating to Vertex AI, this data collection was handled with multiple pipelines overseen by different teams, which introduced unnecessary complexity and reduced development velocity. We moved and consolidated these distinct pipelines as a single serverless Vertex AI Pipeline that is developed and maintained exclusively by our data science team.

The first key benefit we experienced after moving to the new setup was having everything in a single repository, with unified versioning for everything inside, including all of our pipelines and the model code. The single repository tremendously improved traceability and debugging as we can now track changes at a glance. For example, we can easily check which model code was used in the training pipeline run, and we can then check the data collection pipeline to inspect the code that generated the data used for training. This is possible thanks to additional tooling that we built on top of Vertex AI and described in our previous blog.
Another change that made our lives easier is the serverless nature of Vertex AI. Because Google takes care of everything related to infrastructure and pipeline management, we reduced our dependency on the internal infrastructure teams that previously maintained a central Airflow server for our pipelines. Moreover, our pipelines run much faster and more reliably than before, as they get resources on demand and are not bottlenecked by other jobs running at the same time.
Reduced dependency on other teams leads to the final key benefit of our Vertex AI transition: We now own the entire data collection workflow necessary for our model development. Vertex AI Pipelines make it easy to create or modify pipelines in just a few lines of code and they are well integrated with other Google products like BigQuery or Cloud Storage. What this means is that we, as data scientists, are now empowered to develop and productionize new features autonomously, drastically speeding up new model iterations.
Offline experimentation at light speed
Now that dataflow is sorted, we can finally do some machine learning. Most of our ML happens in the development environment, where we use historical data for model development. You can see the typical experimentation pipeline below:
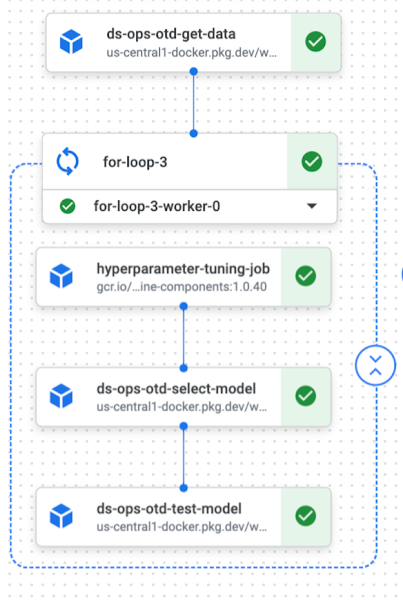
Supply chain is a dynamic creature. To test a hypothesis offline, we need to emulate model training and inference over a long period of time to reliably assess the model quality. The process requires a significant amount of parallelization. For one thing, we utilize parallel for-loops and concurrent pipeline runs extensively, exploiting the serverless nature of Vertex AI Pipelines.
Next, parallelism helps us search for optimal hyperparameters. When splitting data into training, validation, and test sets, we first solve the hyperparameter optimization problem using a dedicated Vertex AI Pipelines component from the Google Cloud Pipeline Components library. The main job searches for the best combination of model hyperparameters by spawning workers that execute the training and validation script on different combinations. Apart from the speed gained, this component also offers a Bayesian optimization algorithm that improves the quality of the search. Vertex AI Pipelines and the Hyperparameter Tuning Job make our work much more efficient, and the setup allows us to iterate rapidly doing extensive offline experimentation as fast as possible.
Once we’ve selected our hyperparameters, we run the final evaluation on the test dataset. We calculate a number of metrics to assess the model from multiple angles; this is the main output of an experiment. To store and navigate experiment results, we use Vertex AI Experiments whose simple interface allows us to log parameters and metrics from our pipelines. Then, we can either use the UI to analyze the results or pull those into a Jupyter Notebook, either locally or using Vertex AI Workbench.

Another convenience provided by Vertex AI is the seamless transition from a development environment to production. In our project, we retrain the live model weekly using the same components as described before. The only new part in the production pipeline is the model deployment step, where we make the model consumable by the live service. There, the model lifecycle is concluded. The process of model upgrade, as well as pipeline upgrade, is managed by a CI/CD system that you can learn more about in our last blog post. The tooling makes the release process streamlined and robust, allowing us to focus on data science problems and experimentation.
Build ML models faster
In summary, our Supply Chain Science team was able to iterate on model development more efficiently and autonomously by migrating to Vertex AI. The gains allow us to focus on improving Wayfair’s customer experience by running extensive offline experiments blazingly fast and easily releasing new ML models. In particular, delivery-time prediction really benefited from the new tooling — you can learn more about the model and its impact in our recent report.
It’s been a great experience partnering with the Vertex AI team and we recommend other data science groups try their platform. Among all the Vertex AI products, our team is particularly invested in Pipelines, Hyperparameter Tuning, and Experiments. Other teams at Wayfair have made use of even more capabilities provided by Vertex AI, so stay tuned to learn more about other use cases and how this state-of-the-art tooling powers data science.



