How Wayfair is reaching MLOps excellence with Vertex AI
Christian Rehm
Senior Machine Learning Engineer, Wayfair
Editor’s note: In part one of this blog, Wayfair shared how it supports each of its 30 million active customers using machine learning (ML). Wayfair’s Vinay Narayana, Head of ML Engineering, Bas Geerdink, Lead ML Engineer, and Christian Rehm, Senior Machine Learning Engineer, take us on a deeper dive into the ways Wayfair’s data scientists are using Vertex AI to improve model productionization, serving, and operational readiness velocity. The authors would like to thank Hasan Khan, Principal Architect, Google for contributions to this blog.
When Google announced its Vertex AI platform in 2021, the timing coincided perfectly with our search for a comprehensive and reliable AI Platform. Although we’d been working on our migration to Google Cloud over the previous couple of years, we knew that our work wouldn’t be complete once we were in the cloud. We’d simply be ready to take one more step in our workload modernization efforts, and move away from deploying and serving our ML models using legacy infrastructure components that struggle with stability and operational overhead. This has been a crucial part of our journey towards MLOps excellence, in which Vertex AI has proved to be of great support.
Carving the path towards MLOps excellence
Our MLOps vision at Wayfair is to deliver tools that support the collaboration between our internal teams, and enable data scientists to access reliable data while automating data processing, model training, evaluation and validation. Data scientists need autonomy to productionize their models for batch or online serving, and to continuously monitor their data and models in production. Our aim with Vertex AI is to empower data scientists to productionize models and easily monitor and evolve them without depending on engineers. Vertex AI gives us the infrastructure to do this with tools for training, validating, and deploying ML models and pipelines.
Previously, our lack of a comprehensive AI platform resulted in every data science team having to build their own unique model productionization processes on legacy infrastructure components. We also lacked a centralized feature store, which could benefit all ML projects at Wayfair. With this in mind, we chose to focus our initial adoption of the Vertex AI platform on its Feature Store component.
An initial POC confirmed that data scientists can easily get features from the Feature Store for training models, and that it makes it very easy to serve the models for batch or online inference with a single line of code. The Feature Store also automatically manages performance for batch and online requests. These results encouraged us to evaluate the adoption of Vertex AI Pipelines next, as the existing tech for workflow orchestration at Wayfair slowed us down greatly. As it turns out, both of these services are fundamental to several models we build and serve at Wayfair today.
Empowering data scientists to focus on building world-class ML models
Since adopting Vertex AI Feature Store and AI Pipelines, we’ve added a couple of capabilities at Wayfair to significantly improve our user experience and lower the bar to entry for data scientists to leverage Vertex AI and all it has to offer:
1. Building a CI/CD and scheduling pipeline
Working with the Google team, we built an efficient CI/CD and scheduling pipeline based on the common tools and best practices at Wayfair and Google. This enables us to release Vertex AI Pipelines to our test and production environments, leveraging cloud-native services.
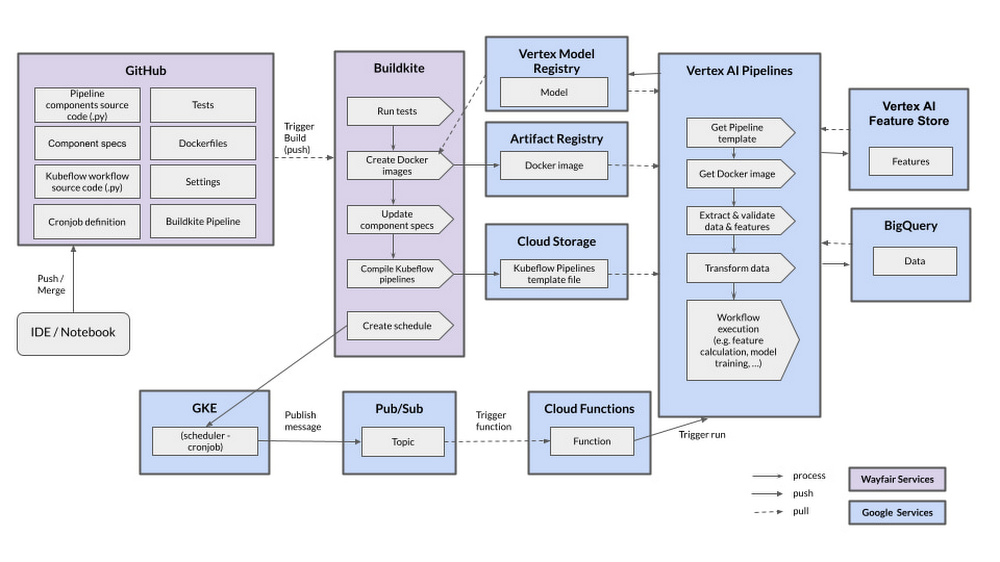
Keeping in mind that all our code is managed in GitHub Enterprise, we have dedicated repositories for Vertex AI Pipelines where the Kubeflow code and definitions of the Docker images are stored. If a change is pushed to a branch, a build starts in the Buildkite tool automatically. The build contains several steps, including unit and integration tests, code linting, documentation generation and automated deployment. The most important artifacts that are released at the end of the build are the Docker image and the compiled Kubeflow template. The Docker image is released to the Google Cloud Artifact Registry and we store the Kubeflow template in a dedicated Google Cloud Storage Bucket, fully versioned and secured. This way, all the components we need to run a Vertex AI Pipeline are available once we run a pipeline (manually or scheduled).
To schedule pipelines, we developed a dedicated Cloud Function that has the permissions to run the pipeline. This Function listens to a Pub/Sub topic where we can publish messages with a defined schema that indicates which pipeline to run with which parameters. These messages are published from a simple cron job that runs according to a set schedule on Google Kubernetes Engine. This way, we have a decoupled and secure environment for scheduling pipelines, using fully-supported and managed infrastructure.
2. Abstracting Vertex AI services with a shared library
We abstracted the relevant Vertex AI services currently in use with a thin shared Python library to support the teams that develop new software or migrate to Vertex AI. This library, called `wf-vertex`, contains helper methods, examples, and documentation for working with Vertex AI, as well as guidelines for Vertex AI Feature Store, Pipelines, and Artifact Registry.
One example is the `run_pipeline` method, which publishes a message with the correct schema to the Pub/Sub topic so that a Vertex AI pipeline is executed. When scheduling a pipeline, the developer only needs to call this method without having to worry about security or infrastructure configuration:
Most notable is the establishment of a documented best practice for enabling hyperparameter tuning in Vertex AI Pipelines, which speeds up hyperparameter tuning times for our data scientists from two weeks to under one hour.
Because it is not yet possible to combine the outputs of parallel steps (components) in Kubeflow, we designed a mechanism to enable this. It entails defining parameters at runtime and executing the resulting steps in parallel via the Kubeflow parallel-for operator. Finally, we created a step to combine the results of these parallel steps and interpret the results. In turn, this mechanism allows us to select the best model in terms of accuracy from a set of candidates that are trained in parallel: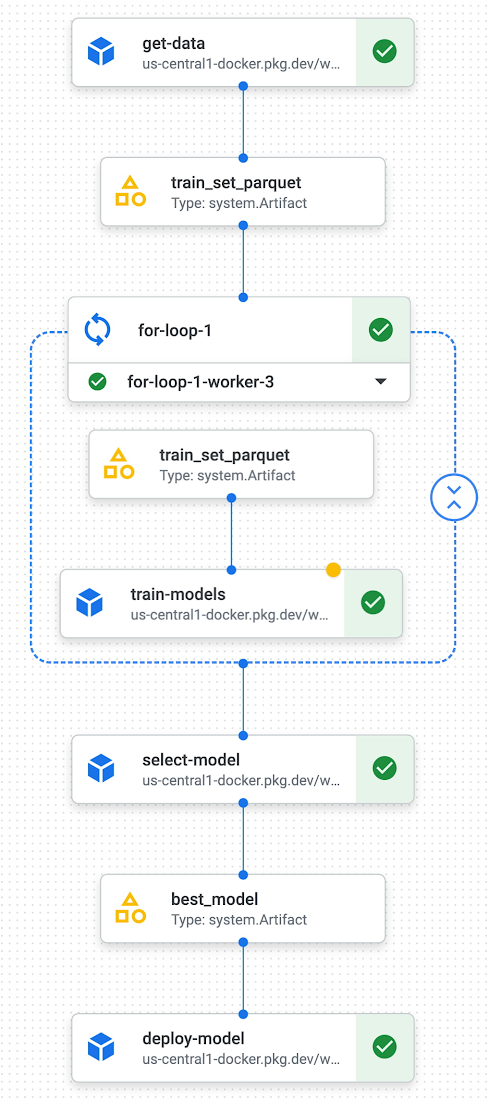
Our CI/CD, scheduling pipelines, and shared library have reduced the effort of model productionization from more than three months to about four weeks. As we continue to build the shared library, and as our team members continue to gain expertise in using Vertex AI, we expect to further reduce this time to two weeks by the end of 2022.
Looking forward to more MLOps capabilities
Looking ahead, our goal is to fully leverage all the Vertex AI features to continue modernizing our MLOps stack to a point where data scientists are fully autonomous from engineers for any of their model productionization efforts. Next on our radar are Vertex AI Model Registry and Vertex ML Metadata alongside making more use of AutoML capabilities. We’re experimenting with Vertex AI for AutoML models and endpoints to benefit some use cases at Wayfair next to the custom models that we’re currently serving in production.
We’re confident that our MLOps transformation will introduce several capabilities to our team, including: automated data and model monitoring steps to the pipeline, as well as metadata management, and architectural patterns in support of real-time models requiring access to Wayfair’s network. We also look forward to performing continuous training of models by fully automating the ML pipeline that allows us to achieve continuous integration, delivery, and deployment of model prediction services.
We’ll continue to collaborate and invest in building a robust Wayfair-focused Vertex AI shared library. The aim is to eventually migrate 100% of our batch models to Vertex AI. Great things to look forward to on our journey towards MLOps excellence.




