ソーク研究所の科学者が Google Cloud と SkyPilot を使用して脳研究を拡大
Google Cloud Japan Team
※この投稿は米国時間 2024 年 2 月 6 日に、Google Cloud blog に投稿されたものの抄訳です。
はじめに
クラウドとその大量の最新プロセッサとスケーラブルなストレージ システムは、今日の生物医学研究組織にとって欠かせないものとなっており、研究者はそれらを使用して膨大な量のデータを生成、解析しています。しかし、研究とはその性質上、線形なプロセスではありません。そのため、クラウド リソースは変化する需要に応じて迅速にスケールアップ / スケールダウンできる柔軟性を備えていなければなりません。さらに、研究は常に資金が限られているため、有益な成果を得るには費用効率と時間効率が極めて重要になります。
昨年、世界をリードする民間非営利研究機関であるソーク研究所は、Google Cloud を使用したあるパイロット プログラムにおいて、コンピューティング費用の 20% の削減と安定性およびスケーラビリティを達成し、マウスの脳全体を分子レベルでマッピングすることに初めて成功しました。
このプログラムは、まずは Spot VM(低コストでの動的な計算)、Cloud Storage(バルクデータ解析とアーカイブ)、Filestore(低レイテンシのデータ解析)などの Google Cloud サービスを利用して開始されました。しかし、研究者が求めていたのは、ワークフロー全体を簡素化し、どのクラウド リージョンでもクラウド サービスを簡単に利用できる手段でした。世の中にはさまざまなオープンソース ツールや非オープンソース ツールがありますが、エンドツーエンドのソリューションを構築する作業は複雑であり、複数のツールをつなぎ合わせる必要があります。Google Cloud チームの協力を得て、私たちはカリフォルニア大学バークレー校が開発した SkyPilot という新興のオープンソース プロジェクトの存在を知りました。これはクラウド ワークフローの簡素化と費用削減にうってつけで、本プログラムにおけるシングルセル マウス全脳解析のバックボーンになりました。
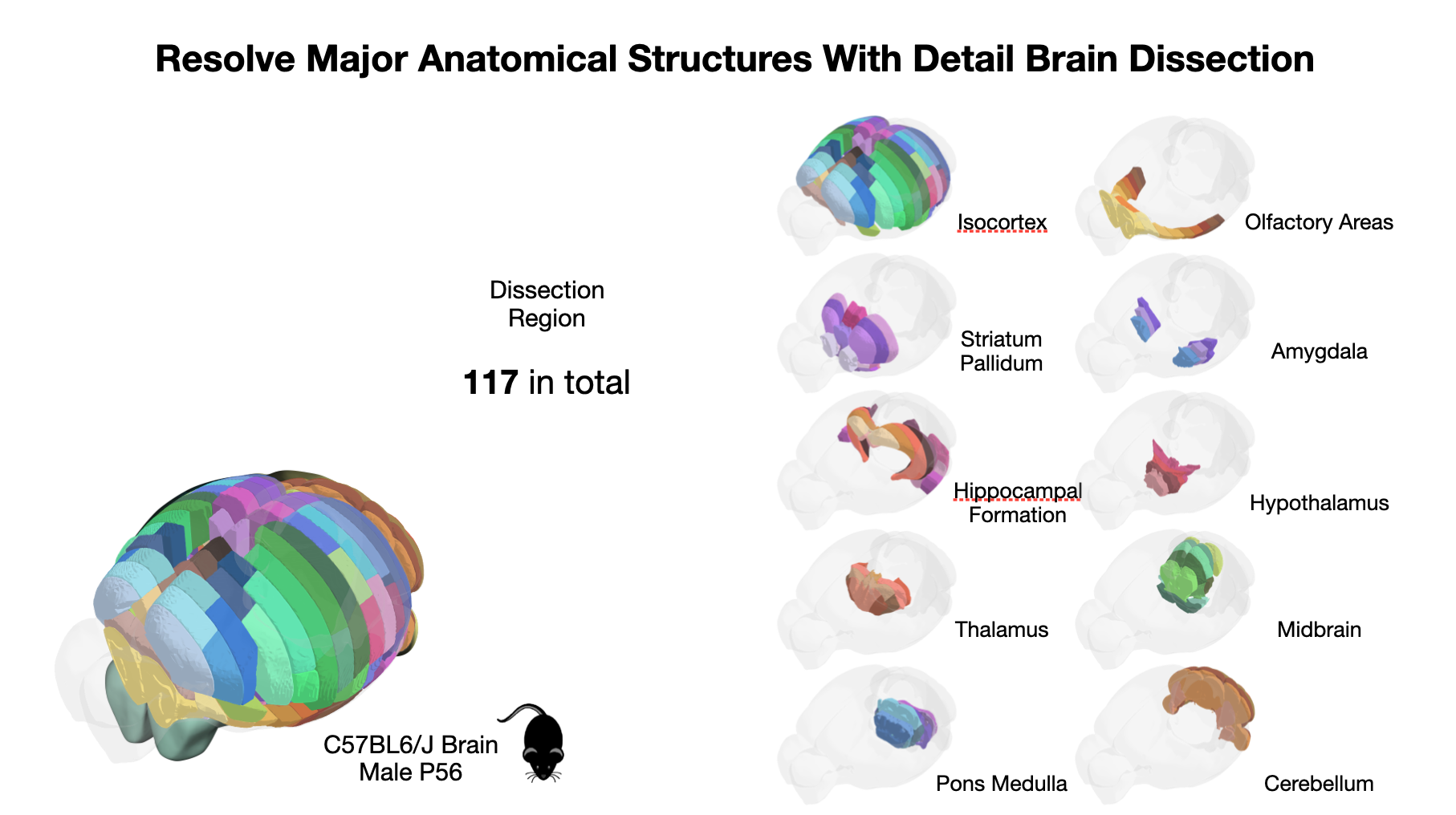
大規模なコンピュータ解析(細胞シーケンシング データのマッピングやダウンストリーム解析などのタスクを含む)の焦点となる主要なマウス脳領域の 3D 構造
「[Google Cloud] は弾力性が高く、複雑な生物学データの処理と解析をこれまでにない規模で行うことができました。」ソーク研究所のゲノム解析ラボの所長、Joe Ecker 教授はこのように語ります。「SkyPilot のシンプルさと効果によって効率はさらに向上し、すべての計算タスクの費用を削減できました。これは、複雑な生物系の理解の前進と研究成果の加速に大きく貢献しました。」
クラウドでの哺乳類の脳
脳は、人類の知る限り最も複雑な構造の一つであり、数十億の細胞が数兆個のシナプスで接続されています。当研究所は、マウスとヒトの脳細胞の分子多様性を細胞レベルの分解能で理解することを目指しています。これを達成するためのバイオインフォマティクス タスクには、相当な計算リソースが必要となります。
そのプロセスは、ウェットラボで数百万の細胞のデータを収集することから始まります。これらの細胞を Google Cloud で解析するため、テラバイト規模のデータを Cloud Storage にアップロードしました。Cloud Storage は大規模かつ低コストのストレージ システムで、復元力が非常に高く、ユーザー側でメンテナンスする必要はありません。
データを解析するため、主要なワークロードを次の 2 つのフェーズに分けました。
- 生の細胞データを解析しやすい形式にマッピングして前処理するバッチジョブ
- 細胞をさらに解析して可視化するための、JupyterLab によるインタラクティブな開発
妥当な時間内に完了させるため、バッチジョブは複数のマシンで実行する必要があります。なぜ多くのジョブを多数のマシンで並列に実行しなければならないかを理解するため、遺伝子マッピングについて見てみましょう。私たちが使用している現在のマッピング パイプラインは、1 つの細胞の処理に約 1 vCPU 時間を要します。マウス全脳データセットに含まれる細胞の数が約 50 万個とすると、たった 1 ラウンドのマッピングが完了するまでに、ハイエンドの 96-vCPU AMD マシン(n2d-standard-96)1 台で 217 日かかります。Google Cloud は弾力性が高く、ほぼ無限の CPU リソースまで計算をスケールアウトできるため、処理がスピードアップします。実際、32 台の 96-vCPU ノードを使用し、細胞処理をノード間で均等に分散させて驚異的並列処理を行うことにより、計算時間は 32 分の 1 に短縮されました。各細胞の解析にかかる時間は比較的短いため、Spot VM は処理費用をさらに削減するのに理想的です。
データのマッピングと前処理が完了した後、データをさらに可視化して解析するために、科学者たちがインタラクティブな開発を行いました。各研究者は、事前定義されたクラウド イメージを使用してそれぞれ独自の JupyterLab VM をオンデマンドで起動しました。これらの VM は、環境を自動的にセットアップして構成し、前処理済みの細胞データを含む Cloud Storage バケットを GCSFuse でマウントしてから、JupyterLab ソフトウェアを起動するように設定されています。GCSFuse のおかげで、Jupyter Notebook で実行するコードから、Cloud Storage バケット内のデータをあたかもローカル ファイル システム上に存在するかのように直接扱うことができます。I/O のレイテンシをできるだけ短くし、研究者間の整合性を高める必要がある場合は、軽量なコードとノートブックを保存するために Filestore も利用しました。
クラウドでの脳研究を容易にする Sky Computing
Google Cloud で提供されている機能は強力です。しかしその一方で、生物情報科学者は、科学的研究により多くの時間を費やせるように、クラウドの操作ができるだけ簡単であること、クラウドのエキスパートにならなくてもクラウドの機能を利用できることを望んでいます。
カリフォルニア大学バークレー校の Sky Computing プロジェクトの目標は、「クラウドでワークロードをどのように実行するか」に伴う面倒な詳細を抽象化することです。これにより、研究者はワークロードそのもの(科学的発見など)に集中できます。本プログラムでは、オープンソース Sky Computing プロジェクトの SkyPilot を利用することで、AI およびデータ サイエンス脳解析ワークフローのエンドツーエンドのデプロイ全体が簡単になりました。Sky Computing は、Google Cloud の「オープン クラウドとなり、オープンソース技術を強力に支援する」という使命とうまく合致しています。そのため、そのユースケースならこの新たなエコシステムによって確実にサポートされるという確信を持つことができました。
SkyPilot の 1 つ目の利点は、低レベルのプロビジョニング、スケジューリング、管理の複雑さのほとんどが自動化されることです。計算リソースの確実なプロビジョニング(失敗またはシャットダウンした場合は自動的に再試行される)、VM の構成、ゾーンやリージョンを越えた繰り返し可能なデプロイ、確実なジョブ スケジューリングなどのタスクはすべて、Sky Computing フレームワークによって自動的に処理されます。これらの中核機能は使いやすい YAML / CLI インターフェースで公開されているため、生産性が向上します。
2 つ目の利点は、完全に再現可能なデータ解析環境を Google Cloud にデプロイできることです。本プログラムでは、バッチ パイプラインとノートブックの両方について、ワークロードに関する以下の 4 つのプロパティを SkyPilot YAML ファイルで指定しました。
- リソース - 必要な計算リソース(ハードウェア、リージョンなど)
- データ - 細胞データを含む Google Cloud Storage バケット。これらのバケットは、GCSFuse を使用して、デプロイされたすべてのコンピューティング インスタンスに自動的にマウントされます。
- セットアップ - 必要なソフトウェア(バイオインフォマティクス パッケージなど)をインストールするための構成コマンド
- 実行 - ワークロードを起動するためのコマンド。私たちのニーズからすると、これには通常、JupyterLab インスタンスの起動と Snakemake(バッチ パイプラインに適した人気のバイオインフォマティクス パイプライン パッケージ)の実行のどちらかが含まれます。
これら 4 つの部分を示す YAML ファイルの例を以下に示します。

シンプルな YAML テンプレートを使用して、完全に再現可能なデータ サイエンス環境を起動できます。この 1 つの YAML ファイルに、リソース、データのセットアップ、環境のセットアップ、実行するワークロード コマンドを記述します。これにより、ノートブックとバッチジョブの両方について一貫した環境が生成されます。
この 1 つの YAML ファイルに、ノートブックまたはバッチジョブを起動する方法を記述します。これで、簡単に再現可能な「job-and-environment-as-code」の仕様ができあがります。
3 つ目の利点は、いくつかの YAML フラグを変更するだけで、各ジョブで使用するコンピューティング インスタンスの数を増減できることです。ここでは、Compute Engine の柔軟なコンピューティングの種類と弾力性が役立ちます。単一のマシンをスケールアップするには、小さな VM(例: n2d-standard-16)を大きな VM(例: n2d-highmem-96)に切り替えます。これにはフラグを 1 つ変更するだけで済みます。バッチ マッピング パイプラインをスケールアウトすれば、Compute Engine 上で数千の Snakemake ジョブを簡単に実行できます。
最後に、ジョブ費用を抑えるために Compute Engine Spot インスタンスを使用する場合、Sky を使用すると比較的管理に手間がかかりません。Spot VM は通常のインスタンスよりも料金が 60%~91% 安いため、大規模な驚異的並列ジョブには不可欠なツールです。さらに、料金の変更は多くても月 1 回なので、費用を予測できます。当研究所のジョブで使用する大型の VM インスタンスの場合、Spot の料金はオンデマンド料金の約 6 分の 1 です(この節約額は無視できません)。ただし、単純に Spot インスタンスを使用するだけでは、プリエンプションや容量不足エラーに自分で対処しなければならず、これが面倒です。
幸いなことに、SkyPilot はコンピューティング費用削減のために Spot VM の使用も大幅に簡素化します。1 つのコマンドでスポットジョブを管理することができ、プリエンプトされたときにユーザーが介入しなくても自動的にジョブが再開されます。軽量なコントローラ VM が、実際のジョブを実行するためのスポット クラスタを 1 つ以上起動します。このコントローラがプリエンプションをモニタリングし、必要に応じて VM を再起動します。ジョブは定期的にチェックポイントを Cloud Storage に書き込み、再起動した VM はこれを読み取ってプリエンプトされた VM が終了したところからジョブを再開します。あるリージョンで十分な Spot VM が定期的に使えなくなる事態に備えて、SkyPilot はいくつかのリージョンの一つでスポット クラスタを復元するよう構成されています。これらすべてが相まって、私たちは低コスト コンピューティングを基本的に無制限に利用することができました。
この SkyPilot によるスポット管理アーキテクチャを次の図に示します。
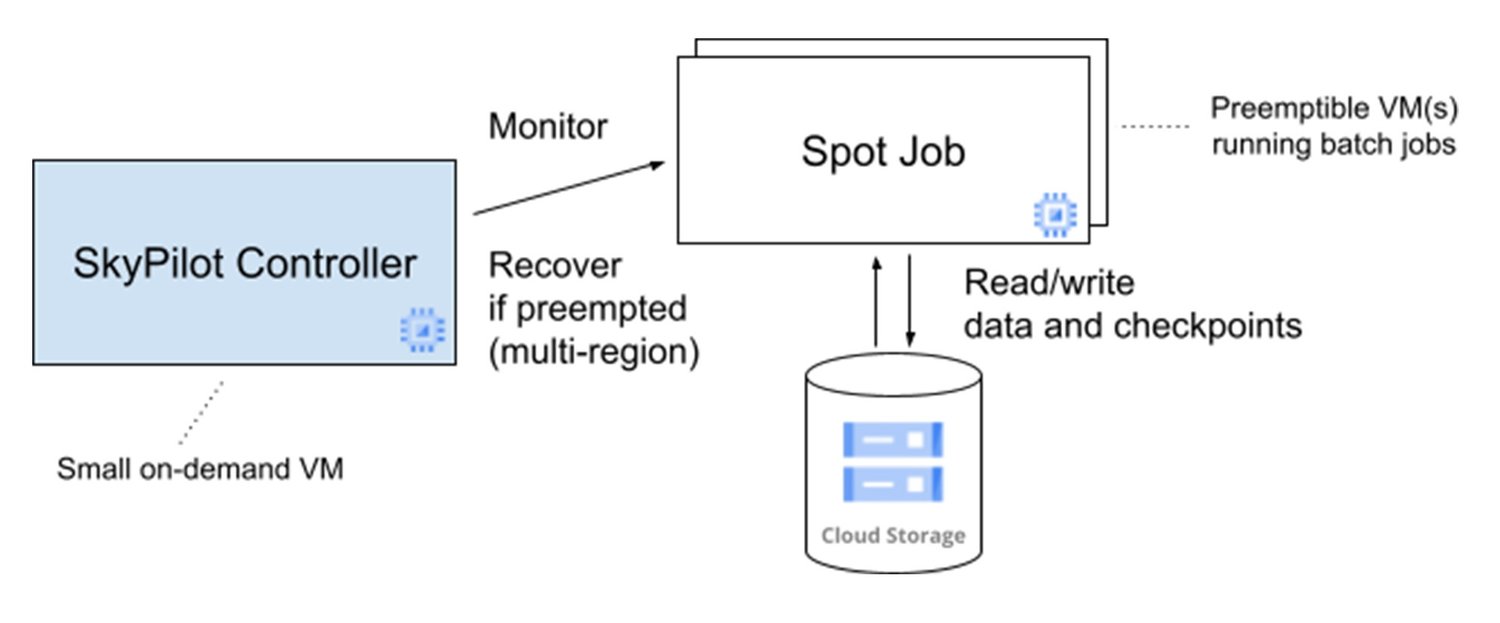
SkyPilot のマネージド スポット機能のおかげで、一貫して約 5.7 分の 1 の費用節約を達成できました(Spot VM による節約からコントローラの料金を差し引いた金額)。これだけ費用効率が高いと、Google Cloud で相当な量の計算を行うことができます。
要するに、オープンソースの Sky Computing 技術と Google Cloud を組み合わせると、クラウド機能の利用がはるかに簡単になります。私たちは実際にこの組み合わせを使用して、Google Cloud で複数の大規模な研究を高い生産性と費用効率で実現しています。
「バークレー校で開発した SkyPilot は、ユーザーがクラウドでより多くのジョブを少ない労力と高い効率で実行できるようにすることを狙いとしています。2023 年に SkyPilot がパブリック クラウドで起動した VM の数は 125,000 を超えます。オープン クラウドのアプローチをとる Google Cloud が Sky Computing エコシステムに参加してくれたのは喜ばしい限りです。この統合により、ソーク研究所の科学者はバイオインフォマティクスに専念し、より短時間でより多くの計算を実行できました。」 - カリフォルニア大学バークレー校、Sky Computing ラボ、博士研究員、Zongheng Yang 氏
ソーク研究所の Ecker ラボが Google Cloud で SkyPilot をどのように使用しているかについては、こちらの記事をご覧ください。
クラウドでの脳研究の未来
今後 5 年のうちに、Human Brain Project で蓄積されたデータの量はかつてないほど膨大になり、増え続けるデータ量の管理という差し迫った問題に直面すると予想されます。36K のシングルセル メチロームと 300K のシングルセル空間トランスクリプトームで構成されるデータがかなりの速度で生成されており、1 週間に増えるデータは 50 TB という途方もない量にのぼります(それに加えて、これらの細胞の処理に 108K vCPU 時間が費やされています)。研究者が簡単にデータにアクセスしてデータの操作や管理ができる環境を維持したまま、このデータの増加をシンプルかつ費用対効果の高い方法で管理することは、解決の難しい大きな課題です。データ転送コンポーネントの一部については、別の Sky Computing プロジェクトである Skyplane によって、オンプレミスと Cloud Storage 間のデータ転送が簡単かつ高速化されると見込まれています。
また、コンピューティングとストレージのニーズが増大する中で Spot VM への継続的なアクセスを確保するために、SkyPilot でより多くのゾーンやリージョンにジョブを分散させるにはどうすればよいかについて詳しく調べる必要があります。ネットワーク下り(外向き)の費用をできるだけ抑えながらコンピューティングとデータを同じ場所に配置しようとする場合、リージョンの数が増えると新たなデータ マネジメントの問題が生じます。
最後に、オンプレミスと Google Cloud の間でジョブとデータの実行や移行をシームレスに行えるハイブリッド ソリューションを構築するための良い方法を見つける必要があります。ローカル リソースとクラウドを組み合わせることで、適切なタイミングで適切なリソースを提供する柔軟なソリューションを実現できます。今後有望な道の一つは、オンプレミスで Kubernetes を、Google Cloud で Google Kubernetes Engine を利用し、さらに SkyPilot に新たに実装される Kubernetes 機能を使用して、オンプレミスとクラウドの垣根を越えてリソースを管理することです。これは興味深い道のりになるでしょう。
この記事の執筆にあたって貴重な貢献をいただいた、ハーバード大学特別研究員の Hanqing Liu 氏、ソーク研究所 Ecker ラボの Anna Bartlett 氏と Wei Tian 氏、カリフォルニア大学バークレー校 Sky Computing チームの全メンバー、Google の Ben Choi 氏と Derek Oliver 氏に深く感謝します。
-ソーク研究所 Ecker ラボ、大学院生、Qiurui Zeng 氏
-Google Cloud Office of the CTO テクニカル ディレクター、Dean Hildebrand