最適化された Intel MPI によって Google Cloud の HPC パフォーマンスが向上
Mansoor Alicherry
HPC Software Engineer, Cloud ML Compute Services, Google Cloud
Todd Rimmer
Director of Software Architecture, Intel NEX Cloud Connectivity Group
※この投稿は米国時間 2024 年 8 月 14 日に、Google Cloud blog に投稿されたものの抄訳です。
ハイ パフォーマンス コンピューティング(HPC)は、さまざまな業界におけるイノベーションの推進において中心的な役割を果たしています。シミュレーションを通じて、製品設計サイクルの加速、製品の安全性の向上、タイムリーな気象予測の提供、AI 基盤モデルのトレーニングの遂行、分野を超えた科学的発見の促進など、さまざまなことを実現しています。HPC なら、緊密にオーケストレーションされ Message Passing Interface(MPI)を介して通信を行う多数のコンピューティング要素、サーバー、仮想マシンにより、こうした計算負荷の高い問題に対処できます。このブログ投稿では、Intel® MPI ライブラリを使用することで、Google Cloud 上の HPC のパフォーマンスがどのように改善されたかについてご紹介します。
Google Cloud は、HPC ワークロードにとって理想的な H3 コンピューティング最適化 VM など、要求の厳しいワークロードに対応する幅広い VM ファミリーを提供しています。これらの VM は、高度なネットワーク オフロードなどの機能を実現する Google の Titanium テクノロジーを採用しており、Intel のソフトウェア ツールによる最適化を通じて、コンピューティング、ネットワーキング、ストレージにおける最新のイノベーションを一つのプラットフォームに集約しています。H3、C3、C3D、A3 などの第 3 世代 VM では、Intel Infrastructure Processing Unit(IPU)E2000 によって CPU から専用デバイスにネットワーキングをオフロードすることで、安全性を確保しながら低レイテンシの 200G イーサネットを実現しています。さらに、Intel MPI ライブラリによる Titanium の統合型サポートにより、分子動力学、計算地球科学、気象予測、フロントエンドとバックエンドの電子設計自動化(EDA)、コンピュータ支援エンジニアリング(CAE)、数値流体力学(CFD)などの HPC ワークロードにネットワーク オフロードのメリットがもたらされます。Intel MPI ライブラリの最新バージョンは、Google Cloud の HPC VM イメージに組み込まれています。
第 3 世代 VM と Titanium 向けに最適化された MPI ライブラリ
Intel MPI ライブラリは、MPI API 標準を実装するマルチファブリック メッセージ パッシング ライブラリです。これは、オープンソースの MPICH プロジェクトに基づく商用グレードの MPI 実装で、OpenFabrics インターフェース(OFI、別名: libfabric)を使用してファブリック固有の詳細な通信情報を取り扱います。さまざまな libfabric プロバイダが用意されており、それぞれがファブリックとプロトコルのさまざまな組み合わせに最適化されています。
Intel MPI ライブラリのバージョン 2021.11 では、特に PSM3 プロバイダが改善されており、Intel IPU E2000 を含む Google Cloud 環境向けの PSM3 プロバイダと OFI/TCP プロバイダのチューニングが提供されています。また、第 4 世代 Intel Xeon スケーラブル プロセッサで利用可能な多数のコアと高度な機能を活用しているほか、新しい Linux OS ディストリビューションと新しいバージョンのアプリケーション / ライブラリに対応しています。こうした改善により、Titanium を搭載した第 3 世代 VM のパフォーマンスが向上し、アプリケーション機能も充実するに至っています。
HPC アプリケーションのパフォーマンスの向上
Siemens の SimcenterTM STAR-CCM+TMソフトウェアなどのアプリケーションを使用することで、並列コンピューティングによって最適解が得られるまでの時間が短縮します。たとえば、コンピューティング リソースを 2 倍にすると同一の問題が半分の時間で解決されるとすれば、並列スケーリングの効率性は 100% となり、半分のリソースで実行した場合と比較してスピードが 2 倍になります。実際には、十分な並列処理がなされていない、ノード間通信にオーバーヘッドがあるなどさまざまな理由により、コンピューティング リソースを 2 倍に増やしてもスピードが 2 倍にならないこともあります。ただし、通信ライブラリの改善により、後者の問題は直接的に改善されます。
新しい Intel MPI ライブラリのパフォーマンスの向上を実証するべく、Google と Intel は H3 インスタンスでいくつかの標準ベンチマークを設定して Simcenter STAR-CCM+ をテストしました。以下の図には、最大 32 台の VM(2,816 コア)分の 5 つの標準ベンチマークが示されています。ご覧のとおり、テストの対象となったシナリオ全体で優れたスピードアップが達成されています。最小のベンチマーク(LeMans_Poly_17M)のみが 16 ノードを超えるとスケーリングが停止していますが、これは問題のサイズが小さいためであり、通信ライブラリのパフォーマンスでは対処されません。一部のベンチマーク(LeMans_100M_Coupled と AeroSuvSteadyCoupled106M)では、VM の台数に応じて急激なスケーリングの上昇が見られます。おそらくは利用可能なキャッシュの増加によるものでしょう。
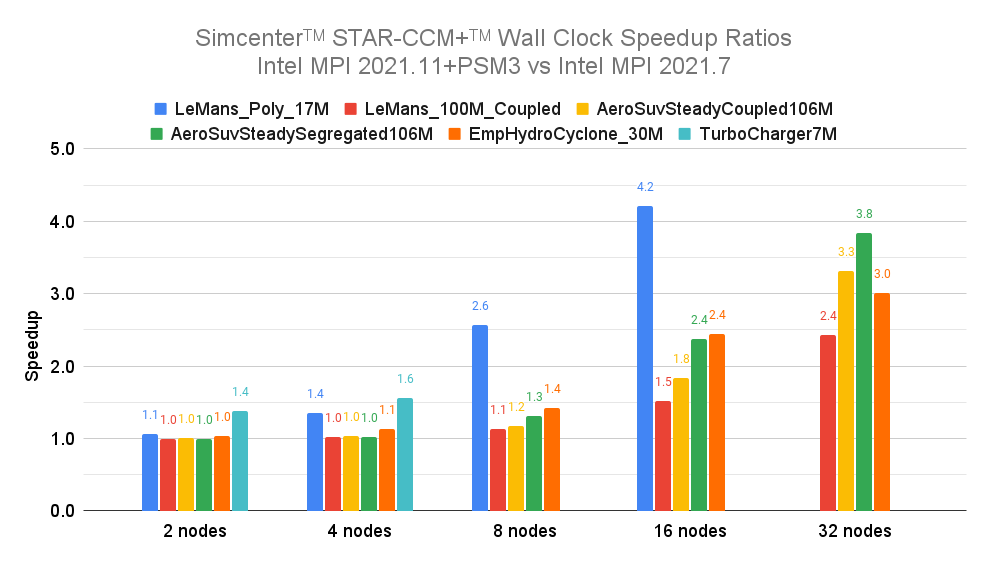
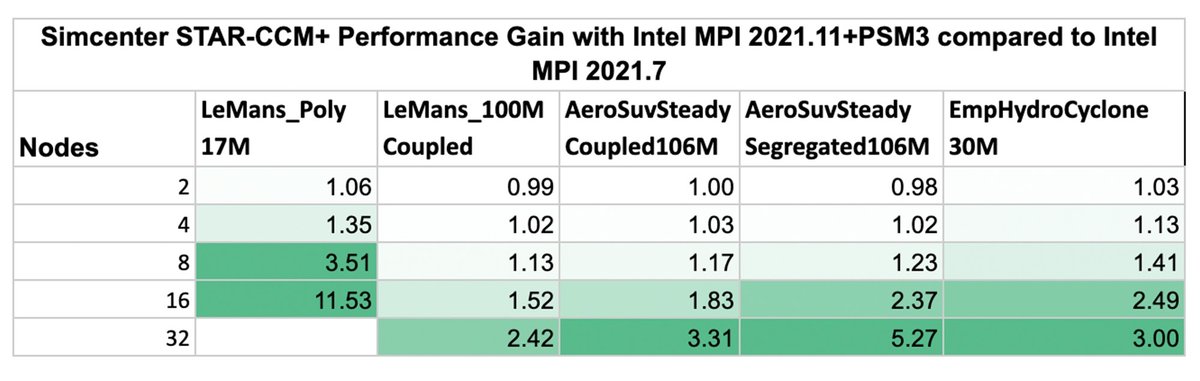
Intel MPI バージョン 2021.11 が Intel MPI バージョン 2021.7 に比べてどの程度改善されているかを示すために、一つひとつの実行について両者の実行時間の比率を求めました。このスピードアップ比率は、古いバージョンの並列実行時間を新しいバージョンの並列実行時間で割ることによって算出されます。算出したスピードアップ比率を以下の表にまとめました。
以下の表からは、最適化された Intel MPI バージョン 2021.11 の方が、ほぼすべてのベンチマークとノード数において、より高い並列スケーラビリティと絶対的なパフォーマンスを実現していることがわかります。この効率性の向上(すなわち、最適解が得られるまでの時間の短縮とコストの削減)は、VM がわずか 2 台のときに早くも実現されており(最大 1.06 倍の改善)、VM の台数が増えるに従って劇的に高まっています(32 台の VM で 2.42 倍から 5.27 倍)。最小のベンチマーク(LeMans_Poly_17M)では、VM が 16 台のときに 11.53 倍という驚異的な改善が見られており、これは、古いバージョンとは異なり、新しい MPI バージョンでは最大 16 台の VM まで適切にスケーリングできることを示しています。
以上の結果は、最適化された Intel MPI ライブラリによって Google Cloud における Simcenter STAR-CCM+ のスケーラビリティが向上し、最適解が得られるまでの時間が短縮され、エンドユーザーがクラウド リソースをより効率的に使用できるようになることを示しています。
各ベンチマークは、Intel MPI バージョン 2021.7 とその TCP プロバイダ、および Intel MPI バージョン 2021.11 と PSM3 libfabric プロバイダを使用して実行されました。Simcenter STAR-CCM+ バージョン 2306(18.06.006)は、Google Cloud の H3 インスタンスでテストしました。ノードあたり 88 個の MPI プロセスと 200 Gbps のネットワークキングを使用し、CentOS Linux リリース 7.9.2009 を実行しました。
お客様とパートナー様の声
「Intel は、Google と連携して Google Cloud Platform と H3 VM に対応する優れたソフトウェアとハードウェアを提供できることを嬉しく思っています。Google と Intel の協力により、数値流体力学と HPC ワークロードのパフォーマンスと効率性が新たな水準へと引き上げられることでしょう。」 - Intel、ソフトウェアおよび先進技術グループ担当バイス プレジデント兼デベロッパー ソフトウェア エンジニアリング担当ゼネラル マネージャー Sanjiv Shah 氏
商標
Siemens に関連する商標の一覧は、こちらでご覧いただけます。その他の商標は、それぞれの所有者に帰属します。



