Colossus: Rapid Storage の高パフォーマンスを実現する秘密の要素

Denis Serenyi
Distinguished Software Engineer, Storage
Vivek Saraswat
Group Product Manager, Storage
Try Gemini 3.1 Pro
Our most intelligent model available yet for complex tasks on Gemini Enterprise and Vertex AI
Try now※この投稿は米国時間 2025 年 4 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
Google Cloud Storage は、そのシンプルさとスケール性で人気の高いオブジェクト ストレージ サービスです。その大きな要素の一つは、データの読み書きに使用できるステートレス REST プロトコルです。しかし、AI の台頭と、データ集約型ワークロードの実行を検討するお客様の増加に伴い、レイテンシが高いこととファイル指向セマンティクスがないことが、オブジェクト ストレージの使用を妨げる 2 つの大きな要因となっています。この問題に対処するため、Google は Google Cloud に Rapid Storage をリリースし、ステートフルな gRPC ベースのストリーミング プロトコルを追加しました。これにより、オブジェクトにデータを簡単に追加する機能が提供され、オブジェクト ストレージの高い総スループットとスケーラビリティを維持しながら、ミリ秒未満の読み取り / 書き込みレイテンシを実現します。この投稿では、このアプローチを採用した理由とその方法、そしてこれによって実現可能な新しいタイプのワークロードについて、アーキテクチャの観点から説明します。
このアプローチでは、Colossus が鍵となります。Colossus は、Google のほぼすべてのプロダクトの基盤となる、Google の内部ゾーン クラスタレベルのファイル システムです。最近のブログ投稿で説明したように、Colossus は、低レイテンシと大規模なスケーリングを実現する高度な SSD 配置手法により、Google の極めて要求の厳しいパフォーマンス重視のプロダクトをサポートしています。
Colossus のパフォーマンスを支えるもう一つの重要な要素は、そのステートフル プロトコルです。Rapid Storage は、Colossus のステートフル プロトコルの機能を Google Cloud のお客様に直接提供します。
Colossus クライアントは、ファイルの作成または読み取りを行う際に、まずファイルを開いてハンドルを取得します。ハンドルには、ファイルのデータが保存されているディスクなど、ファイルの保存方法に関するすべての情報が含まれます。クライアントは、読み取りまたは書き込みの実行時にこのハンドルを使用して、最適化された RDMA のようなネットワーク プロトコルを介してディスクに直接アクセスできます。これについては、以前に公開された Snap ネットワーキング システムに関する論文で概説しています。
ハンドルは、超低レイテンシの永続的な追加をサポートするためにも使用できます。これは、要求の厳しいデータベースやストリーミング分析アプリケーションで非常に有益です。たとえば、Spanner と Bigtable はどちらもログファイルにトランザクションを書き込みますが、ログファイルは永続的なストレージを必要とし、データベース変更のクリティカル パス上にあります。同様に、BigQuery はテーブルへのストリーミングをサポートし、大規模に並列化されたバッチジョブは最近取り込まれたデータに対して計算を実行します。これらのアプリケーションは Colossus ファイルを追加モードで開き、アプリケーションで実行されている Colossus クライアントはハンドルを使用して、データベースの変更とテーブルデータをネットワーク経由で直接ディスクに書き込みます。Colossus は、データの永続性を保証するため、データを複数のディスクに複製します。書き込みは並列に行われ、クォーラム手法を使用してストラグラーを待機することによるレイテンシを回避します。
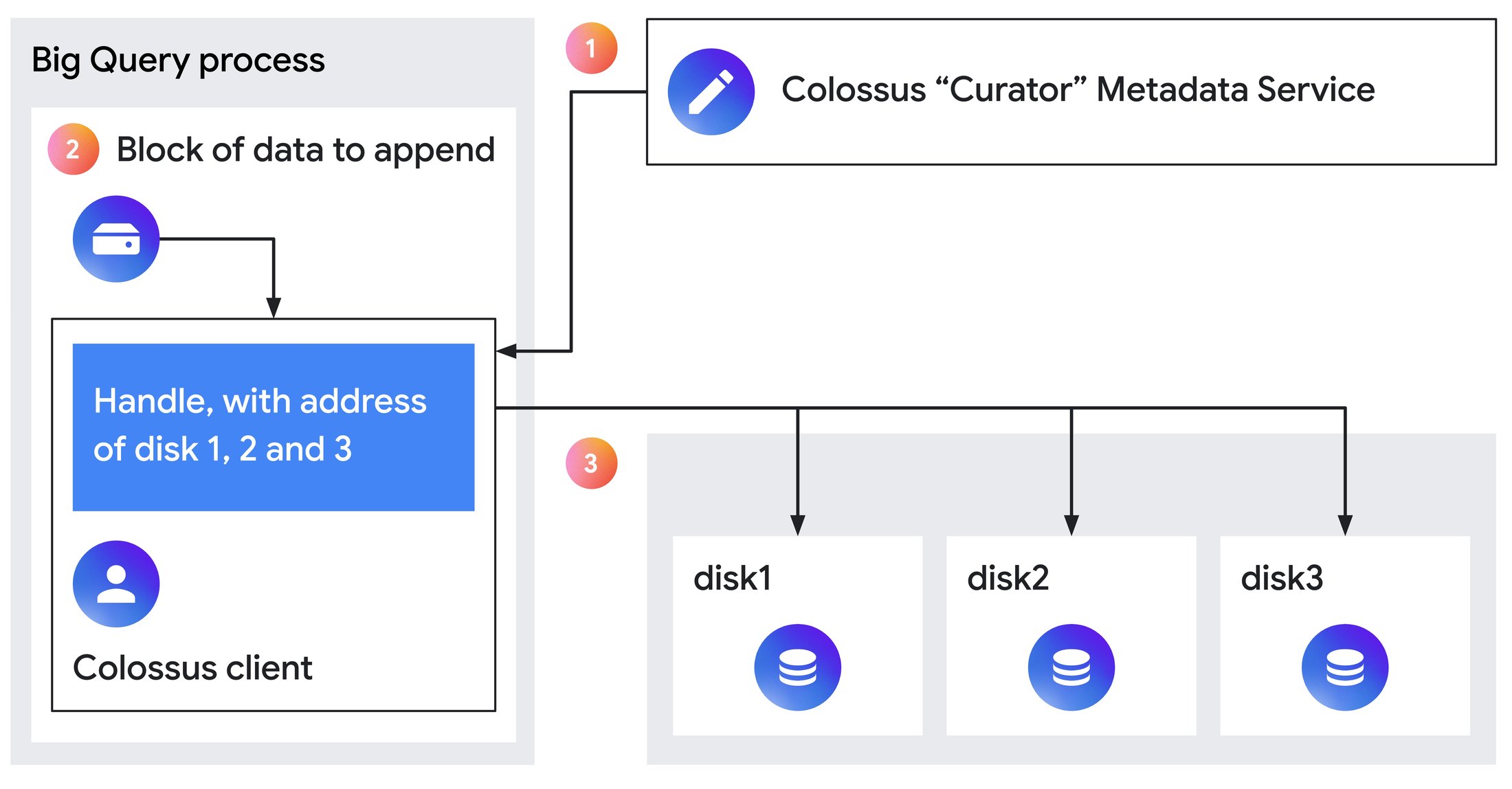
図 1: Colossus でファイルにデータを追加する手順。
上の図は、ファイルにデータを追加する手順を示しています。
-
アプリケーションがファイルを追加モードで開きます。Colossus Curator がハンドルを生成し、それをインプロセスで実行されている Colossus クライアントに送信します。クライアントはハンドルをキャッシュに保存します。
-
アプリケーションが、Colossus クライアントに対して、任意のサイズのログエントリへの書き込み呼び出しを発行します。
-
Colossus クライアントは、ハンドル内にあるディスク アドレスを使用して、ログエントリをすべてのディスクに並列に書き込みます。
Rapid Storage は Colossus のステートフル プロトコルに基づいて構築されており、基盤となるトランスポートとして gRPC ベースのストリーミングを利用しています。Rapid Storage オブジェクトに対して低レイテンシの読み取りと書き込みを実行する際、Cloud Storage クライアントはストリームを確立し、Cloud Storage の REST プロトコルで使用されるのと同じリクエスト パラメータ(バケットやオブジェクト名など)を供給します。さらに、ユーザー認証やメタデータ アクセスなどの時間のかかる Cloud Storage 操作はすべて、ストリーミングの作成時に先行ロードされて実行されるため、その後の読み取りと書き込みの操作は、Colossus に対して追加のオーバーヘッドなしで直接実行され、追加可能な書き込みと範囲が限定された繰り返し読み取りをミリ秒未満のレイテンシで実行することが可能となります。
この Colossus アーキテクチャにより、Rapid Storage は 1 つのバケットで 1 秒あたり 2,000 万件のリクエストをサポートできます。これは、さまざまな AI / ML アプリケーションで非常に有用な規模です。たとえば、モデルの事前トレーニングでは、データの準備が完了すると、ランダム化されたデータ サンプルのセットが GPU または TPU にフィードされます。これらは通常、それぞれ数億から数十億のトークンを含む大きなファイルです。ただし、トレーニングが進むにつれて、異なるランダム サンプルが異なる順序で読み取られるなどの要因により、データが順次に読み取られることはほとんどありません。Rapid Storage のステートフル プロトコルを使用すると、トレーニングの実行の開始時にストリームが確立されてから、ミリ秒未満の速度で範囲が限定された読み取りが並列に大規模に実行されます。これにより、ストレージのレイテンシによってアクセラレータがブロックされるのを回避します。
追加の場合も同様に、Rapid Storage は Colossus のステートフル プロトコルを利用して、ミリ秒未満のレイテンシで永続的な書き込みを実現し、オブジェクトのサイズ制限まで 1 つのオブジェクトへの追加を無制限にサポートします。ステートフル追加プロトコルの主要な課題は、クライアントまたはサーバーがハングまたはクラッシュした場合にどのように処理するかです。Rapid Storage では、ストリームを作成するときに、クライアントが Cloud Storage からハンドルを受け取ります。ストリームが中断された場合でも、このハンドルを使用して新しいストリームを再確立することで、クライアントはオブジェクトに対して読み取りや追加を継続できます。これにより、このフローが合理化され、レイテンシによる影響を最小限に抑えられます。クライアントに問題があり、アプリケーションが新しいクライアントからオブジェクトへの追加を継続しようとする場合、複雑になります。これを簡略化するために、Rapid Storage では、一度に 1 つの gRPC ストリームのみがオブジェクトに書き込めるようにしています。新しいストリームがオブジェクトのオーナー権限を引き継ぎ、以前のストリームによるトランザクションをロックアウトします。最後に、各追加操作には書き込み先のオフセットが含まれるため、ネットワーク パーティションやリプレイが発生しても、データの正確性が常に維持されます。
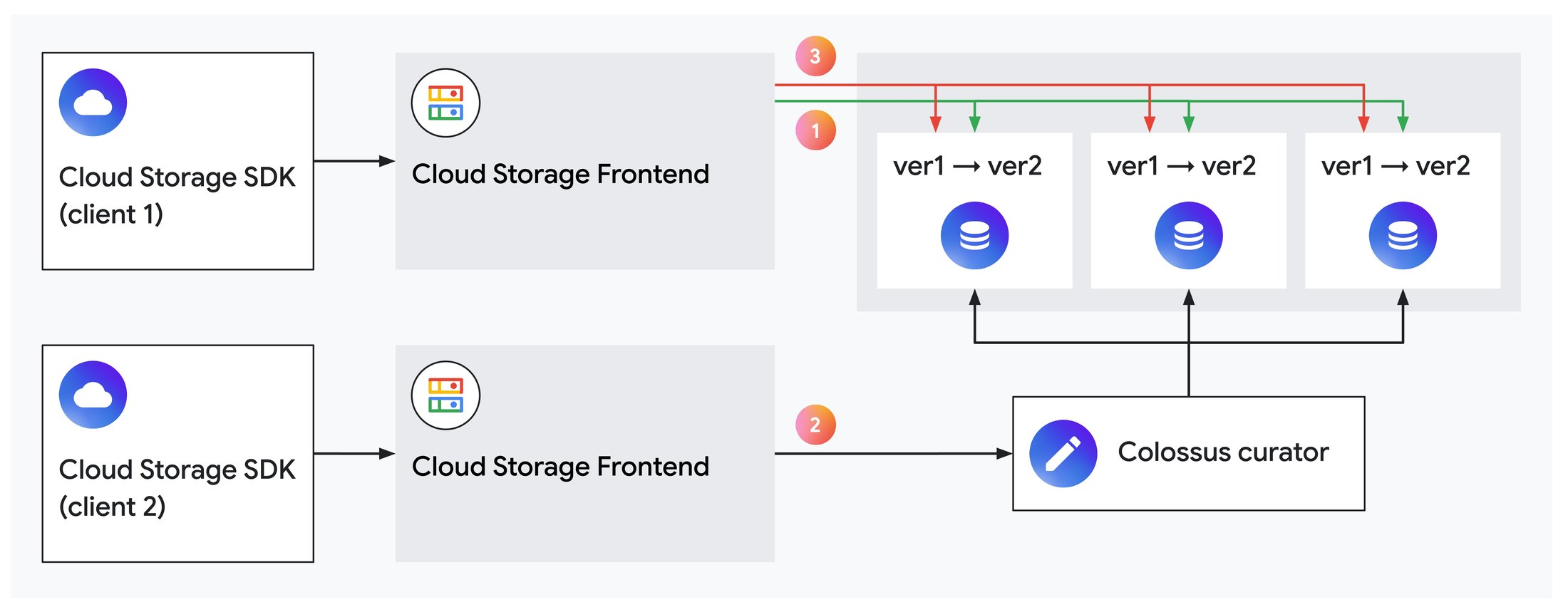
図 2: 新しいクライアントがオブジェクトのオーナー権限を引き継ぐ。
上の図では、新しいクライアントがオブジェクトのオーナー権限を取得し、以前のオーナーをロックアウトしています。
-
まず、クライアント 1 が 3 つのディスクに保存されているオブジェクトにデータを追加します。
-
アプリケーションがクライアント 2 にフェイルオーバーし、クライアント 2 がこのオブジェクトを追加モードで開きます。Colossus Curator が、各オブジェクト データのレプリカのバージョン番号を増加させ、クライアント 1 によるトランザクションをロックアウトします。
-
クライアント 1 がオブジェクトにデータを追加しようとしても、そのオーナー権限は古いバージョン番号に関連付けられているため、追加できません。
Rapid Storage をアプリケーションにできる限り簡単に統合できるようにするため、Google は SDK も更新して、gRPC ストリーミング ベースの追加をサポートし、シンプルなアプリケーション指向の API を公開できるようにしました。ハンドルを使用してデータを書き込むことは、ファイル システムの世界では馴染みのあるコンセプトです。そこで Google は、Rapid Storage を Cloud Storage FUSE に統合し、低レイテンシのファイル指向ワークロードのために、クライアントが Cloud Storage バケットにファイルのようにアクセスできるようにしました。また、Rapid Storage では、ゾーンバケット タイプの一部として階層型名前空間をネイティブに有効化しており、パフォーマンスと整合性を強化し、フォルダ指向の API を提供しています。
まとめると、Rapid Storage は、ブロック型ストレージのミリ秒未満のレイテンシ、並列ファイル システムのスループット、オブジェクト ストレージのスケーラビリティと使いやすさを兼ね備えています。これらを実現するため、Colossus が主要な役割を果たしています。プレビュー期間中にお客様が試した興味深いワークロードをいくつかご紹介します。
-
AI / ML のデータ準備、トレーニング、チェックポインティング
-
分散データベース アーキテクチャの最適化
-
バッチ分析とストリーミング分析処理
-
動画のライブ ストリーミングとコード変換
-
ロギングとモニタリング
Rapid Storage の試用にご興味がある場合は、こちらからご登録いただくか、Google Cloud の担当者までお問い合わせください。
詳しくは、Google Cloud Next のブレイクアウト セッション「What’s new with Google Cloud’s Storage(Google Cloud のストレージに関する最新情報)」(BRK2-025)、「AI Hypercomputer: Mastering your Storage Infrastructure(AI Hypercomputer: ストレージ インフラストラクチャをマスターする)」(BRK2-020)、「Under the Iceberg: Simple, unified Cloud Storage for analytics data lakes(水面下の氷山: 分析データレイク向けのシンプルで統合された Cloud Storage)」(BRK2-026)にご参加ください。
-ストレージ担当上級ソフトウェア エンジニア、Denis Serenyi
-ストレージ担当グループ プロダクト マネージャー、Vivek Saraswat


