保険会社が暴風雨のデータを動的料金設定に使用する方法
Google Cloud Japan Team
※この投稿は米国時間 2021 年 5 月 17 日に、Google Cloud blog に投稿されたものの抄訳です。
驚くべきことに、2020 年に米国で発生した自然災害による経済的損失は総額 1,190 億ドルに上り、その経済的損失の 75%(894 億ドル)は暴風雨や低気圧によって引き起こされました。保険業界では、データがすべてです。保険会社はデータに基づいて、保険引受、保険率、保険料、記入用紙、マーケティング、さらには保険請求処理を調整しています。良質のデータを使用できれば、リスク評価の精度が高まり、それによって業績が向上します。これを可能にするために、保険業界では予測分析の導入が進んでいます。予測分析とは、データ、統計アルゴリズム、機械学習(ML)、機械学習の手法を利用して、過去のデータに基づいて将来の結果を予測することです。保険会社はまた、外部データソースを自社の既存のデータと統合して、保険請求者や損害についてより詳しい分析情報を生成しています。Google Cloud 一般公開データセットは、保険会社がこのようなデータの「マッシュアップ」を行ううえで役立つ BigQuery を通じて、需要が高い一般公開データセットを 100 以上提供しています。
保険会社にとって非常に有用なデータセットの一つが、米国海洋大気庁(NOAA)の Severe Storm Event Details です。Google Cloud 一般公開データセット プログラムと NOAA の Public Data Program の一部であるこの暴風雨のデータには、州別、国別、事象の種類別の、嵐に関するさまざまなレポートが含まれており、このデータは 1950 年から現在まで定期的に更新されています。Google Cloud 一般公開データセット プログラム内の、類似する NOAA のデータセットには、Significant Earthquake Database、Global Hurricane Tracks、Global Historical Tsunami Database もあります。
この投稿では、保険会社向けの優れた分析情報を取得するために、一般的なデータ サイエンス ツールとして Python ノートブックと BigQuery を使用して、嵐の事象データを保険料に適用する方法を探ります。
暴風雨のデータセットを使用して結果を予測する
財産保険会社の場合、一般的な保険料決定要因には、家屋の条件、査定人、近隣データ、取り替え費用が挙げられます。しかし、地域的なハリケーン、鉄砲水、雷雨といった自然災害などのマクロフォースも、被保険者のリスク プロファイルに大きな影響を与えます。保険会社は、財産や農作物などに対する過去の損害について気象事象の重大度を分析することで、動的な保険料の決定に悪天候データを活用できます。
ただし、関連するリスクを考慮して、保険料を正確に設定することが重要です。現在、保険会社はさまざまな要因を考慮に入れて、洗練された統計モデルを実行していますが、このような要因の多くは時間とともに変化する可能性があります。結局のところ、正確なデータがなくては、精度の低い予測によって、ビジネスに大規模な損失が発生する恐れがあります。
Severe Storm Event Details データベースには、嵐の事象の場所、方位角(天球座標で使用する角度測定)、距離、影響、重大度(財産や農作物に対する損害費用など)に関する情報が含まれています。文書化されている内容は以下のとおりです。
死亡、けが、財産への大きな損害、商業活動の中断を引き起こす勢力がある嵐およびその他の重大な気象事象の発生。
メディアの注意を引く、まれな異常気象事象(フロリダ州南部やサンディエゴ沿岸部での微量の降雪など)。
その他の重大な気象事象(記録的な気温の上昇または低下、別の事象に関連して発生した降雨など)。
損害評価やその他の分析に時間をかけられるよう、特定の事象に関するデータは 120 日以内にデータセットに追加されます。
BigQuery とノートブックを使用してビジネスの分析情報を取得する
Google Cloud の BigQuery では、複数の方法でこのデータに簡単にアクセスできます。たとえば、BigQuery 内で直接クエリを実行し、SQL を使用して分析を行うことができます。
データ サイエンティストやアナリストのコミュニティで人気のある別の方法としては、ノートブック環境内から BigQuery にアクセスして Python コードと SQL テキストを組み入れてから、アドホック テストを行う方法があります。この方法では、Pandas などのメモリ内で複雑な変換を行わなくても、BigQuery の強力なコンピューティングを利用して、大量のデータに対してクエリを実行し、そのデータを処理できます。
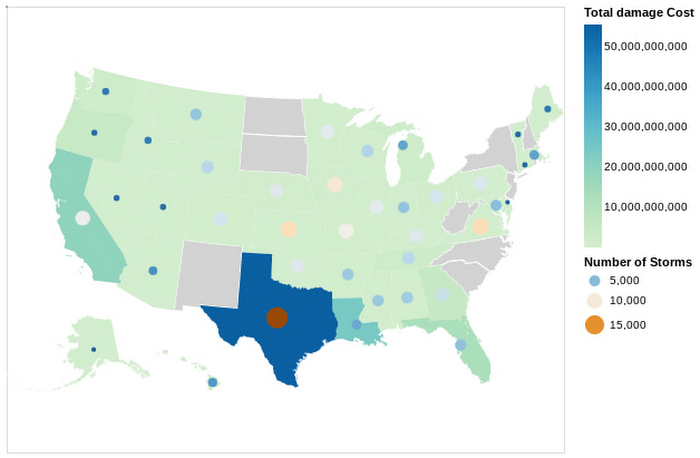
この Python ノートブックでは、暴風雨のデータを使用して、過去の損害で測定された気象事象の重大度に基づき、さまざまな郵便番号の地域のリスク プロファイルを生成する方法を示しています。暴風雨のデータセットに対してクエリが実行され、より小さなデータセットがノートブックで取得されます。その後、Python を使用して、そのデータセットが探索され、可視化されます。郵便番号の地域のリスク プロファイルは以下のとおりです。
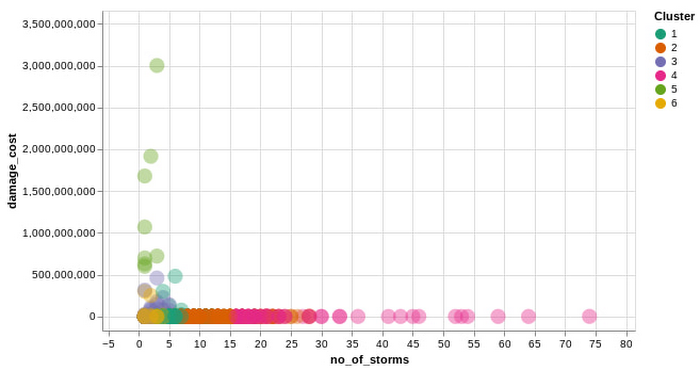
保険会社向けのもう一つの Google Cloud リソースは BigQuery ML です。これにより、保険会社は標準の SQL クエリを使用して、自社のデータに基づく機械学習モデルを作成し、実行することができます。このノートブックでは、K 平均法クラスタリング アルゴリズムにより、BigQuery ML を使用して、暴風雨の影響が最も大きい 5 つの州における、さまざまな郵便番号の地域クラスタを生成しています。これらのクラスタは、さまざまなレベルの嵐の影響を表し、さまざまなリスクグループを示します。
アナリストは、このサンプル ノートブックをリファレンス ガイドとして利用することで、一般公開データセットを簡単に取り込み、活用して、分析を強化し、ビジネスの分析情報の取得プロセスを合理化できます。一般公開データセットとともに BigQuery およびその他のソリューションを使用すれば、このデータにアクセスして使用する方法を自分で見つける必要がなく、分析情報を簡単に取得できるため、自社のビジネス ソリューションに集中できる時間が増えます。
ビッグデータで良い影響を生み出す
Google Cloud の幅広いエコシステムは、金融サービスに携わるデータ サイエンス チームに、成長に役立つ詳細な分析情報を取得するための柔軟なツールを提供しており、Google Cloud の一般公開データセットは、そのエコシステム内のリソースの一つにすぎません。Google では、地球に関する情報を整理し、テクノロジーを通じて利用可能にして、人々がともにプラスの影響を与えることができるようにするために、環境、社会、ガバナンス(ESG)に対する取り組みを行っており、この暴風雨のデータセットは、その取り組みの一環です。
この一般公開データセットに関する Google Cloud と NOAA のコラボレーションの詳細については、Google Cloud 金融サービス サミットの 5 月 27 日の Dynamic Pricing in Insurance: Leveraging Datasets To Predict Risk and Price(動的な保険料設定: リスクと料金の予測にデータセットを活用)セッションにご参加ください。また、最近のブログや、BigQuery と BigQuery ML の詳細もご確認いただけます。
-Google Cloud データ スペシャリスト Sireesha Pulipati
-グローバル保険およびリスク管理ソリューション担当マネージング ディレクター Henna Karna



