Datastream を使用して機械学習と分析用のデータを統合
Google Cloud Japan Team
※この投稿は米国時間 2021 年 5 月 26 日に、Google Cloud blog に投稿されたものの抄訳です。
機械学習モデルのアーキテクチャはより洗練され、効果的になってきています。しかしその大前提として、モデルをトレーニングするための高品質な最新データを使用できる必要があることに変わりはなく、AI を活用したアプリケーションの構築における潜在的な障害となっています。ML モデリングに必要な特徴量エンジニアリングと変換を行うために、データをオンプレミスまたはクラウドのデータベースからリアルタイムの統合ビューに転送するには、バッチジョブと高価なメンテナンスが必要なため、面倒な作業になる可能性があります。
Datastream とは
Datastream はこのような課題に対処できる、使いやすいサーバーレスの変更データ キャプチャ(CDC)およびレプリケーション サービスです。さまざまなソースでのデータ変更を低レイテンシで取り込めるようにすることで、予測モデルを日、時間、さらには分単位で動的に更新する必要がある機械学習アプリケーションを強化します。Datastream は、オンプレミスやクラウドでホストされているソースのデータを統合し、低レイテンシでアクセスできるようにします。
ストリームは Oracle データベースと MySQL データベースから作成できます。その他のソースにも近日中に対応する予定です。ストリームは、挿入、更新、削除など、ソース内のデータに対するあらゆる変更をキャプチャして、Google Cloud Storage に送信します。このサービスには、宛先として Pub/Sub(ストリーミング データ用のリアルタイム メッセージング サービス)と BigQuery(Google の高性能データ ウェアハウス)が今後追加される予定です。これらのプロダクトに接続することで、以前は使用されていなかったデータやアクセスできなかったデータを、イベント ドリブン アーキテクチャ、機械学習モデルのトレーニング、異種データベースの同期、リアルタイム分析の強化などに利用できるようになります。
Datastream のニーズ
典型的な機械学習パイプラインの例として、オンラインでスカーフを販売する架空の会社 Scarfy について考えてみましょう。Scarfy のビジネス目標は、ホームページにアクセスしたユーザーとショッピング カートに商品を追加したユーザーに、データを使用してカスタマイズしたおすすめ商品を提案して収益を増やすことです。
Scarfy には、ユーザー イベント(商品の閲覧やショッピング カートへの商品の追加など)を含む Oracle データベースと、商品カタログ用の MySQL インスタンスがあり、どちらもオンプレミスに保存されています。Scarfy ではデザイナーがスカーフをたくさん制作していて、カタログが毎日更新されます。データ サイエンス チームは、これらの新しい商品をできるだけ早くおすすめ商品として提案できるようにしたいと考えています。
Datastream を導入する前は、Data Fusion や BigQuery などのデータ統合ツールやデータ ウェアハウス ツールへの低レイテンシ ゲートウェイとして Cloud Storage を設定していました。手袋などの新しい商品をカタログに追加する場合、エンジニアは新しいデータの格納用テーブルを追加するためにコードを記述する必要がありました。また、オブジェクト ストレージ バケット データを更新するためのバッチ処理ジョブのコードも記述しなければならないため、労力や脆弱性、レイテンシが増大していました。
Datastream がどのように役立ったか
Datastream を接続するだけで、Cloud Storage バケットの宛先に MySQL インスタンスと Oracle インスタンスの両方からデータが送信され、自動的に低レンテンシで更新されます。両方のソースのデータタイプは Datastreamの統合タイプに正規化されるので、元の形式にかかわらずデータをマージして処理できるようになります。
ストリームが確立されると、Scarfy のエンジニアは新しいカタログデータが生成されるのとほぼ同時に、パイプラインに新しいカタログデータを追加できます。オンプレミスの元のデータソースに変更が加えられると、Cloud Storage 内のカタログとユーザー入力データセットの同期と統合が行われて最新の状態に維持されます。各ストリームの階層は現在、次のもので構成されています。
ストリームと、そのソース データベースと宛先バケット。
オブジェクト – ソース データベースからストリーミングされるテーブル。
ソース データベースに対するあらゆる変更(挿入、更新、削除)を含むイベント。
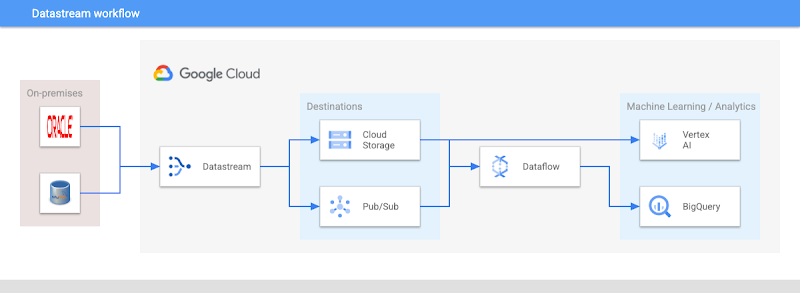
この段階では、Dataflow テンプレートを使って、次のような機械学習モデルの開発向けに Cloud Storage からデータを取得し、データ ダウンストリームを転送できます。
BigQuery で統合データの最新ビューを作成する。エンジニアはこのビューで、顧客セグメンテーション用の K 平均法クラスタリングやレコメンダー システム用の行列分解といった ML アルゴリズムをテストできます。このようなアルゴリズムなどは、単純な SQL ステートメントを使用してコンソールでネイティブに使用できます。
Cloud Storage 内のデータを直接利用する、Vertex AI プラットフォームでのカスタムモデル開発。Scarfy のエンジニアは、フルマネージドの Notebooks を使用してレコメンデーション サービスの協調フィルタリングを行ったり、AutoML を使用して、コードを記述することなく高パフォーマンス モデルを生成したりできます。モデル オプションには、外観に基づいてカタログ内の新しいスカーフにラベルを付けるための画像分類や、販売予測などがあります。
まとめ
Scarfy のパイプラインはリアルタイムの変更ストリームに接続されているため、商品カタログにある新商品を統合データセットに追加し、それをモデルのトレーニング プロセスに含めることで、数時間以内(モデルのトレーニング時間によって異なります)におすすめ商品としてユーザーに提案できるようになります。
ぜひ、現在プレビュー版の Datastream を使用して、低レイテンシ CDC データを活用した機械学習モデルを構築してみてください。詳細については、Datastream プロダクト ページまたは Datastream の発表に関するブログをご覧ください。
-Google Cloud カスタマー エンジニア Robin Stringer




