Using Datastream to unify data for machine learning and analytics
Robin Stringer
Customer Engineer, Google Cloud
While machine learning model architectures are becoming more sophisticated and effective, the availability of high-quality, fresh data for training models remains the largest dependency and potential roadblock to building AI-powered applications. Transferring data from on-premises or cloud databases to a real-time, unified view for feature engineering and transformations necessary for ML modelling can be cumbersome to perform, requiring batch jobs and expensive maintenance.
What is Datastream?
Datastream is a serverless change data capture (CDC) and replication service that is easy to use and addresses these challenges. By making data changes available from a variety of sources at low-latencies, it powers machine learning applications that need to dynamically update their predictive models by the day, hour, or even minute. Datastream unifies and provides low-latency access to data from on-premises and cloud-hosted sources.
Streams can be created from Oracle and MySQL databases, with additional sources coming soon. The streams capture and transmit every change to data in the source - be it an insert, update, or delete - into Google Cloud Storage. The service will add Pub/Sub, a real-time messaging service for streaming data, and BigQuery, Google’s high-performance data warehouse, as destinations in the future. Once connected, previously dormant or inaccessible data become available for event-driven architectures, training machine learning models, synchronizing heterogeneous databases, powering real-time analytics, and more.
What is the need?
Let’s consider a typical machine learning pipeline for a fictional company, Scarfy, which sells scarves online. Their business goal is to increase revenue by using data to serve personalized recommendations to users on the homepage, and when they add items to the shopping cart.
Scarfy has an Oracle database containing user events, such as browsing and adding items to a shopping cart, and a MySQL instance for their product catalogue. Both are on-premises. Scarfy’s designers are prolific and their catalog is updated daily. The data science team aims to include these new items in the recommendations as soon as possible.
In pre-Datastream times, Scarfy may have set up Cloud Storage as a low-latency gateway to data integration and warehouse tools such as Data Fusion and BigQuery. If the company added gloves to their catalog, engineers would have to write more code to add additional tables to account for the new data. They would also be busy writing batch processing jobs to update the object storage bucket data, adding toil, fragility, and latency.
How Datastream helps
With a simple Datastream connection, the Cloud Storage bucket destination receives the data from both the MySQL and Oracle instances, which is then automatically updated with low latency. The data types from both sources are normalized to a Datastream unified type, to facilitate merging the data regardless of original format for further processing.
With the stream established, Scarfy engineers can include the new catalogue data in their pipeline almost as soon as it is generated. Their connection synchronizes and unifies the catalog and user input datasets in Cloud Storage, and keeps current with changes to the original data sources on-premises. Each stream’s hierarchy now comprises:
The stream, with its source database and destination bucket.
Objects - the tables streamed from the source database.
Events, which include every change to the source database (inserts, updates, deletes).
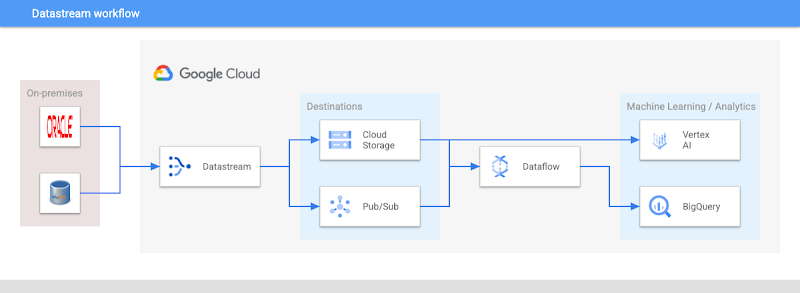
At this stage, Dataflow templates can pick up the data from Cloud Storage and transfer the data downstream for machine learning model development, including:
Creating up-to-date views of the unified data in BigQuery, where engineers can experiment with ML algorithms from k-means clustering for customer segmentation to matrix factorization for recommender systems. These algorithms and more are available natively using simple SQL statements in the console.
Custom model development on the Vertex AI platform, drawing directly on the data in Cloud Storage. Scarfy engineers can use fully-managed Notebooks to work on collaborative filtering for recommendations services, or AutoML to generate a performant model with zero code. Model options include image classification to label new scarves in the catalog based on their appearance, or sales forecasting.
Conclusion
Since Scarfy’s pipeline is now connected to a real-time change stream, they can add new items from their product catalog to their unified dataset, include it in the model training process, and start recommending it to users within a few hours (depending on model training time).
You too can build your machine learning models powered by low-latency CDC data with Datastream, now available in preview. Please see the Datastream product page for more information, or check out the Datastream announcement blog.


