Agent Factory Recap: A Deep Dive into Agent Evaluation, Practical Tooling, and Multi-Agent Systems

Annie Wang
Google AI Cloud Developer Advocate
Mollie Pettit
Developer Relations Engineer
How do you know if your agent is actually working? It’s one of the most complex but critical questions in development. In our latest episode of the Agent Factory podcast, we dedicated the entire session to breaking down the world of agent evaluation. We'll cover what agent evaluation really means, what you should measure, and how to measure using ADK and Vertex AI. You'll also learn more advanced evaluation in multi-agents systems.

This post guides you through the key ideas from our conversation. Use it to quickly recap topics or dive deeper into specific segments with links and timestamps.
Deconstructing Agent Evaluation
We start by defining what makes agent evaluation so different from other forms of testing.
Beyond Unit Tests: Why Agent Evaluation is Different
Timestamp: [02:20]
The first thing to understand is that evaluating an agent isn't like traditional software testing.
Traditional software tests are deterministic; you expect the same input to produce the same output every time (A always equals B).
LLM evaluation is like a school exam. It tests static knowledge with Q&A pairs to see if a model "knows" things.
Agent evaluation, on the other hand, is more like a job performance review. We're not just checking a final answer. We're assessing a complex system's behavior, including its autonomy, reasoning, tool use, and ability to handle unpredictable situations. Because agents are non-deterministic, you can give the same prompt twice and get two different--but equally valid--outcomes.

A Full-Stack Approach: What to Measure
Timestamp: [04:15]
So, if we're not just looking at the final output, what should we be measuring? The short answer is: everything. We need a full-stack approach that looks at four key layers of the agent's behavior:
- Final Outcome: Did the agent achieve its goal? This goes beyond a simple pass/fail to look at the quality of the output. Was it coherent, accurate, and safe? Did it avoid hallucinations?
- Chain of Thought (Reasoning): How did the agent arrive at its answer? We need to check if it broke the task into logical steps and if its reasoning was consistent. An agent that gets the right answer by luck won't be reliable.
- Tool Utilization: Did the agent pick the right tool for the job and pass the correct parameters? Crucially, was it efficient? We've all seen agents get stuck in costly, redundant API call loops, and this is where you catch that.
- Memory & Context Retention: Can the agent recall information from earlier in the conversation when needed? If new information conflicts with its existing knowledge, can it resolve that conflict correctly?

How to Measure: Ground Truth, LLM-as-a-Judge, and Human-in-the-Loop
Timestamp: [06:43]
Once you know what to measure, the next question is how. We covered three popular methods, each with its own pros and cons:
-
Ground Truth Checks: These are fast, cheap, and reliable for objective measures. Think of them as unit tests for your agent's outputs: "Is this a valid JSON?" or "Does the format match the schema?" Their limitation is that they can't capture nuance.
-
LLM-as-a-Judge: Here, you use a powerful LLM to score subjective qualities, like the coherence of an agent's plan. This approach scales incredibly well, but its judgments are only as good as the model's training and biases.
-
Human-in-the-Loop: This is the gold standard, where domain experts review agent outputs. It's the most accurate method for capturing nuance but is also the slowest and most expensive.
The key takeaway is not to pick just one. The best strategy is to combine them in a calibration loop: start with human experts to create a small, high-quality "golden dataset," then use that data to fine-tune an LLM-as-a-judge until its scores align with your human reviewers. This gives you the best of both worlds: human-level accuracy at an automated scale.
The Factory Floor: Evaluating an Agent in 5 Steps
The Factory Floor is our segment for getting hands-on. Here, we moved from high-level concepts to a practical demo using the Agent Development Kit (ADK).
Hands-On: A 5-Step Agent Evaluation Loop with ADK
Timestamp: [08:41]
The ADK Web UI is perfect for fast, interactive testing during development. We walked through a five-step "inner loop" workflow to debug a simple product research agent that was using the wrong tool.
1. Test and Define the "Golden Path." We gave the agent a prompt ("Tell me about the A-phones") and saw it return the wrong information (an internal SKU instead of a customer description). We then corrected the response in the Eval tab to create our first "golden" test case.
2. Evaluate and Identify Failure. With the test case saved, we ran the evaluation. As expected, it failed immediately.
3. Find the Root Cause. This is where we got into the evaluation. We jumped into the Trace view, which shows the agent's step-by-step reasoning process. We could instantly see that it chose the wrong tool (lookup_product_information instead of get_product_details).
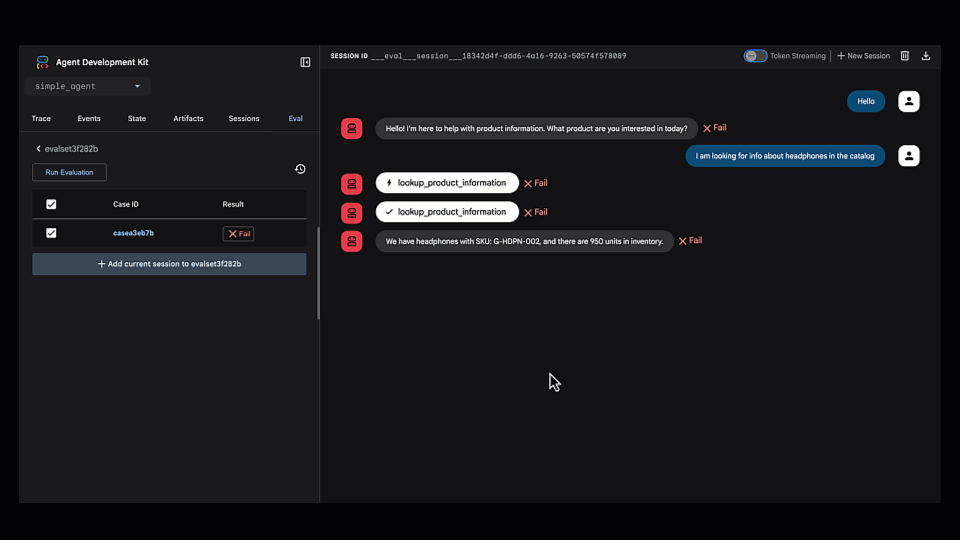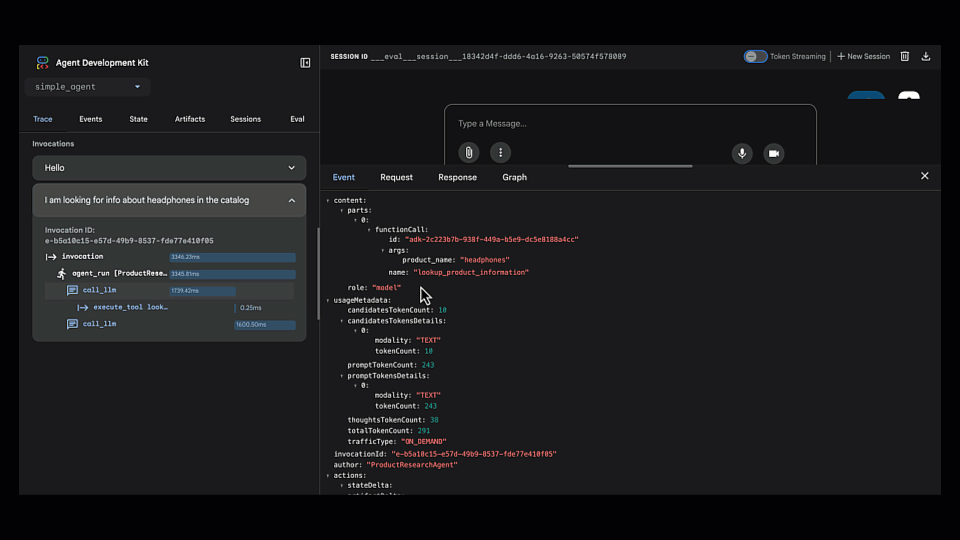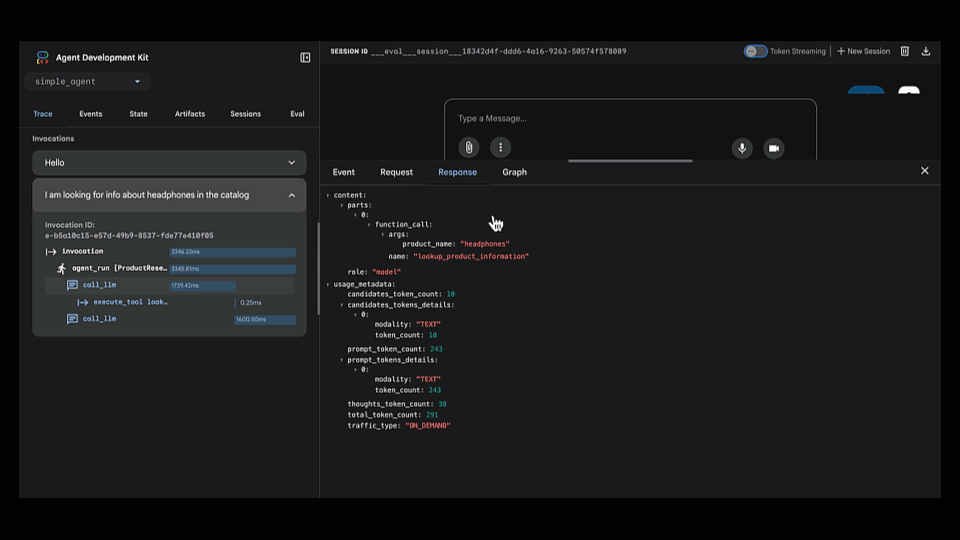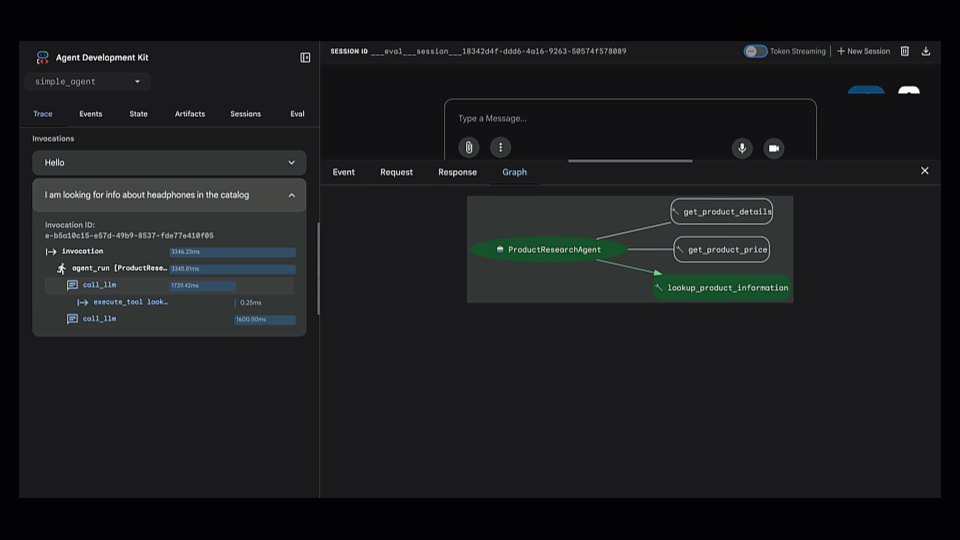
4. Fix the Agent. The root cause was an ambiguous instruction. We updated the agent's code to be more specific about which tool to use for customer-facing requests versus internal data.
5. Validate the Fix. After the ADK server hot-reloaded our code, we re-ran the evaluation, and this time, the test passed. The agent provided the correct customer-facing description.
From Development to Production
This ADK workflow is fantastic for development, but it doesn't scale. For that, you need to move to a production-grade platform.
From the Inner Loop to the Outer Loop: ADK and Vertex AI
Timestamp: [11:51]
Think of your workflow in two loops:
-
ADK for the Inner Loop: It's built for the fast, manual, and interactive debugging you do during development.
-
Vertex AI for the Outer Loop: When you need to run evaluations at scale with richer metrics (like LLM-as-a-judge), you need a production-grade platform like Vertex AI's Gen AI evaluation services. It’s designed to handle complex, qualitative evaluations for agents at scale and produce results you can build monitoring dashboards with.
The Cold Start Problem: Generating Synthetic Data
Timestamp: [13:03]
Both of these workflows require a dataset, but what if you don't have one? This is the "cold start problem," and we solve it with synthetic data generation. We walked through a four-step recipe:
-
Generate Tasks: Ask an LLM to generate realistic user tasks.
-
Create Perfect Solutions: Have an "expert" agent produce the ideal, step-by-step solution for each task.
-
Generate Imperfect Attempts: Have a weaker or different agent try the same tasks, giving you a set of flawed attempts.
-
Score Automatically: Use an LLM-as-a-judge to compare the imperfect attempts against the perfect solutions and score them.
The Three-Tier Framework for Agent Testing
Timestamp: [14:10]
Once you have evaluation data, the developer's next challenge is clear: how do you use it to design tests that scale? You can't just manually check every output forever. We approach this problem with a three-tier testing strategy.
-
Tier 1: Unit Tests. This is the ground floor. Just like in traditional coding, you test the smallest pieces of your agent in isolation. For example, verifying that a specific tool, like
fetch_product_price, correctly extracts data from a sample input without running the whole agent. -
Tier 2: Integration Tests. This is the agent's "test drive." Here, you evaluate the entire, multi-step journey for a single agent. You give it a complete task and verify that it can successfully chain its reasoning and tools together to produce the final, expected outcome.
-
Tier 3: End-to-End Human Review. This is the ultimate sanity check where automation meets human judgment. For complex tasks, a human expert evaluates the agent's final output for quality, nuance, and correctness. This creates a "human-in-the-loop" feedback system to continuously calibrate and improve the agent's performance. It's also at this stage that you begin testing how multiple agents interact within a larger system.

The Next Frontier: Evaluating Multi-Agent Systems
Timestamp: [15:09]
As we move from single agents to multi-agent systems, evaluation has to evolve. Judging an agent in isolation doesn't tell you much about the overall system's performance.
We used an example of a customer support system with two agents: Agent A for initial contact and Agent B for processing refunds. If a customer asks for a refund, Agent A's job is to gather the info and hand it off to Agent B.

If you evaluate Agent A alone, its task completion score might be zero because it didn't actually issue the refund. But in reality, it performed its job perfectly by successfully handing off the task. Conversely, if Agent A passes the wrong information, the system as a whole fails, even if Agent B's logic is perfect.
This shows why, in multi-agent systems, what really matters is the end-to-end evaluation. We need to measure how smoothly agents hand off tasks, share context, and collaborate to achieve the final goal.
Open Questions and Future Challenges
Timestamp: [18:06]
We wrapped up by touching on some of the biggest open challenges in agent evaluation today:
-
Cost-Scalability Tradeoff: Human evaluation is high-quality but expensive; LLM-as-a-judge is scalable but requires careful calibration. Finding the right balance is key.
-
Benchmark Integrity: As models get more powerful, there's a risk that benchmark questions leak into their training data, making scores less meaningful.
-
Evaluating Subjective Attributes: How do you objectively measure qualities like creativity, proactivity, or even humor in an agent's output? These are still open questions the community is working to solve.
Your Turn to Build
This episode was packed with concepts, but the goal was to give you a practical framework for thinking about and implementing a robust evaluation strategy. From the fast, iterative loop in the ADK to scaled-up pipelines in Vertex AI, having the right evaluation mindset is what turns a cool prototype into a production-ready agent.
We encourage you to watch the full episode to see the demos in action and start applying these principles to your own projects.
Connect with us



