BigQuery でのスパースな特徴のサポート
Google Cloud Japan Team
※この投稿は米国時間 2023 年 1 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
はじめに
ほとんどの機械学習モデルでは特徴を数値形式で入力する必要があり、特徴がカテゴリ形式である場合、ワンホット エンコーディングなどの前処理ステップで数値形式に変換する必要があります。大量のカテゴリ値を変換すると、値の大部分がゼロまたは空の一連の特徴、いわゆる「スパースな特徴」が作成される場合があります。
ゼロの値も保存容量を必要とし、スパースな特徴に含まれる値は大部分がゼロまたは空であるため、これらを効果的に保存する方法が不可欠です。そこで今回、スパースな特徴をサポートする BigQuery の新機能をリリースしました。この新機能により、Array[Struct<int, numerical>] データ型を使用して効率的に BigQuery でスパースな特徴を保存して処理できます。
スパースな特徴とは?
機械学習システムに関してある程度の経験がある方なら、「スパースな特徴」という言葉を耳にしたことがあるでしょう。ほとんどの機械学習アルゴリズムでは入力として数値特徴を必要とするため、特徴がカテゴリ形式である場合、通常はワンホット エンコーディングなどの前処理ステップを適用して変換してから入力用の特徴として使用します。大量のカテゴリ値が含まれるカテゴリデータの列にワンホット エンコーディングを適用すると、大部分がゼロまたは空の値である一連の特徴が作成されます。これを「スパースな特徴」とも呼びます。
「Hello World」と「BigQuery supports sparse features now」という 2 つの文を例に考えてみましょう。bag-of-words アプローチでこれらの文のベクトル表現を作成すると、以下のような結果になります。

「Hello World」は [0 0 1 0 0 0 1] と表現されます。1 となっているのは 2 つだけで、ベクトルの残りの値はすべてゼロです。つまり、テキストのコーパスが大規模である場合、大部分がゼロの非常に大きな NxM 次元となります。スパースな特徴は本質的に予測不可能なため、数列で済むこともあれば、数万列(またはそれ以上)に及ぶ可能性もあります。
ゼロの値を含む列が数万もあるという状況は、特に規模が大きい場合、望ましいとはいえません。ゼロは容量を占めるだけでなく、検索などの操作でも多くの計算処理が必要となります。このため、スパースな特徴を使用する場合は、効率的に保存して処理することが重要です。
この目標を達成するには、ベクトルのゼロ以外の要素のインデックスのみを保存します。いずれにせよ、残りの値はゼロなので問題ありません。ゼロ以外の要素すべてのインデックスを保存すると、最も大きいインデックスが判明するため、スパースなベクトルを再構築できます。このアプローチにより、「Hello World」を [0 0 1 0 0 0 1] ではなく [(2, 1), (6,1)] と表現できます。TensorFlow の SparseTensor をご存じであれば、この BigQuery の新機能もそれと似たものとお考えください。
BigQuery でのスパースな特徴の使い方
新たにリリースされたこの機能により、BigQuery でスパースな特徴を効率的に保存して処理できます。このブログ投稿では、例を挙げてスパースな特徴の作成方法を説明します。
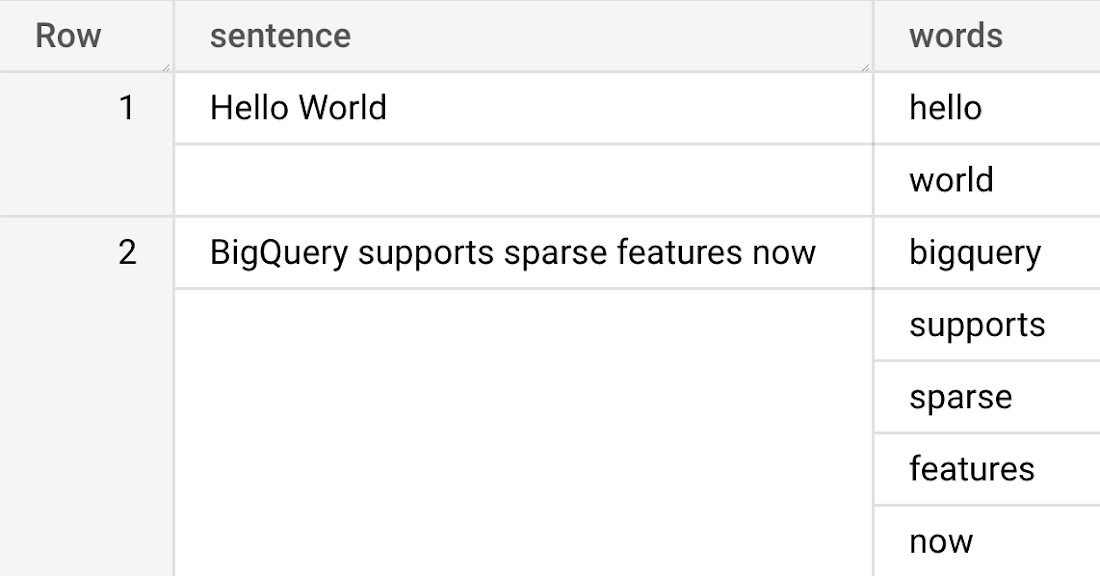
まず、「Hello World」と「BigQuery ML supports sparse features now」という 2 つの文を含むデータセットを作成しましょう。また、REGEXP_EXTRACT_ALL 関数を使用してこれらの文を単語に分割します。
以下のような sentences テーブルが作成されます。
文をベクトル形式で表現できるように、文のすべての単語を使用して、語彙を保存するテーブルを作成します。そのためには、以下のコマンドを実行します。
vocabulary テーブルに以下の情報が入力されます。
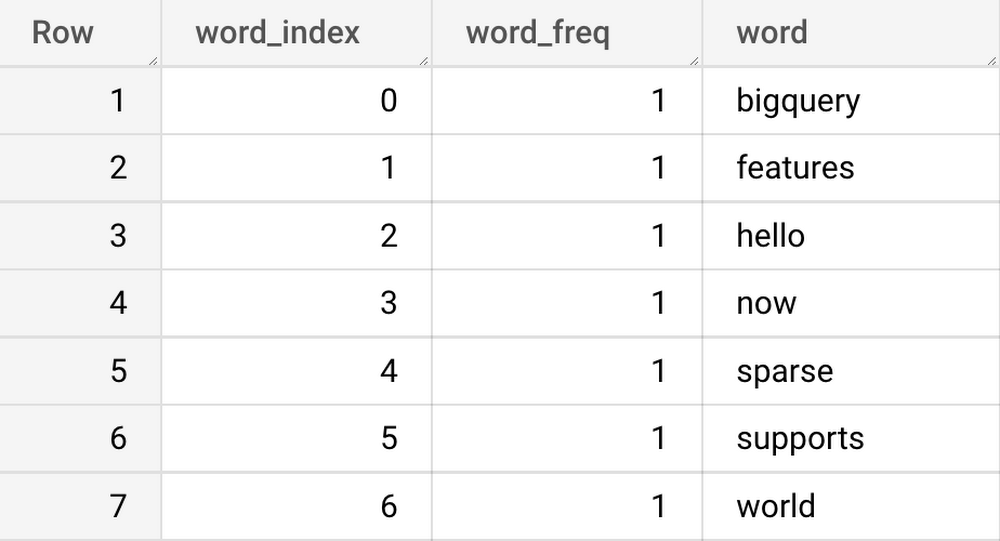
語彙テーブルを作成したら、新機能を使用してスパースな特徴を作成できます。BigQuery でスパースな特徴を作成するには、以下のように Array[Struct<int, numerical>] 型の列を定義するだけです。
以下のような結果になります。
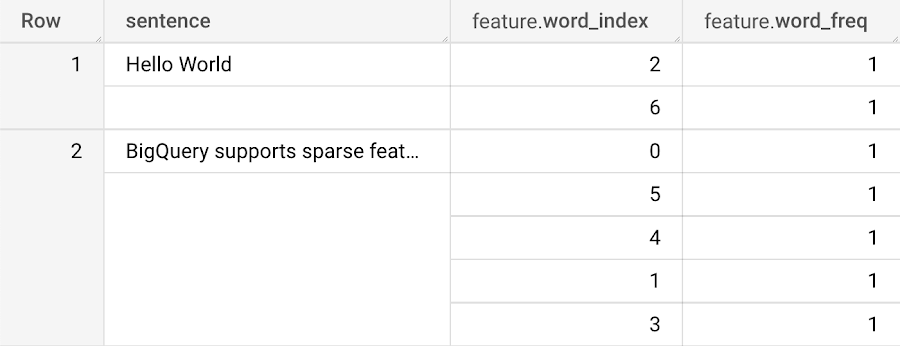
これで完了です。BigQuery を使用してスパースな特徴を作成できました。この特徴を使用して BigQuery ML でモデルをトレーニングできます。スパースな特徴の機能は、このように活用することができます。
- Google Cloud ソフトウェア エンジニア Xiaoqiu Huang