GKE でワークロードを多次元にスケーリング
Google Cloud Japan Team
※この投稿は米国時間 2021 年 3 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
Google Kubernetes Engine(GKE)では、アプリケーション オーナーは、1 つの Kubernetes リソース、多次元 Pod オートスケーラー(MPA)のみを使用して、ワークロードに複数の自動スケーリング動作を定義できます。
Pod の水平スケーリングと垂直スケーリングの課題
Kubernetes が広く採用されるプラットフォームとして成功した要因は、多様なワークロードとそのさまざまな要件に対応したことにあります。Kubernetes でこれまで継続的に改善してきた分野の一つが、ワークロードの自動スケーリングです。
Kubernetes の初期から使用されていた Pod の自動スケーリングの主要メカニズムが、水平 Pod オートスケーラー(HPA)でした。その名前のとおり、HPA は特定の指標がユーザー定義のしきい値を超えたときに、Pod レプリカを追加するための機能をユーザーに提供します。初期には、この指標は通常、CPU 使用量またはメモリ使用量でしたが、現在はカスタム指標や外部指標にも対応しています。
その後少し経って、ワークロードの自動スケーリングに新しい次元として垂直 Pod オートスケーラー(VPA)が追加されました。その名前が示すように、VPA は使用パターンに基づいて Pod がリクエストする必要のある最適な CPU 量またはメモリ量に関する推奨値を算出する機能を提供します。ユーザーは、その推奨値を確認して適用する必要があるかどうかを決定します。また、VPA 側で変更を自動的に適用するように構成することもできます。
当然ながら、Kubernetes ユーザーは、この 2 つのスケーリング形式両方の利点を活用しようとしてきました。
これらのオートスケーラーは互いに独立して機能しますが、2 つを同時に実行すると、予期しない結果が生じる可能性があります。
以下の例をご覧ください。

HPA は、Pod がターゲット CPU 使用率 50% を維持するように、レプリカの数を調整します。
VPA で推奨値を自動的に適用するように構成した場合、CPU リクエストが継続的に縮小するループに陥る可能性があります。これは、HPA で比較的低いターゲット CPU 使用率を維持しているのが原因で発生します。VPA を自律的に動作するように構成すると、CPU とメモリの両方に変更が適用される点が、ここでの課題の一つです。そのため、VPA で変更を自動的に適用する限り、競合を回避するのが困難になる可能性があります。
それ以来、ユーザーは妥協案として次の 2 つの方法のいずれかを使用してきました。
HPA は CPU またはメモリに対するスケーリング、VPA は推奨値の取得にのみ使用して、推奨値の確認と適用を行う自動化を別個に構築する
VPA を使用して CPU とメモリに変更を自動的に適用し、同時にカスタム指標または外部指標に基づいて HPA を使用する
これらの回避策が適しているユースケースもいくつかありますが、なかには CPU とメモリの両方の次元にわたる自動スケーリングでメリットが得られるワークロードもあります。
たとえば、ウェブ アプリケーションでは、CPU がバインドされている場合には CPU の水平自動スケーリングが必要になりますが、メモリの構成ミスによりコンテナで OOMkilled イベントが発生した場合には、信頼性を確保するためにメモリの垂直自動スケーリングが必要になります。
多次元 Pod オートスケーラー
MPA で初めて可能になった機能により、ユーザーは CPU 使用率に基づいて Pod を水平スケーリングし、メモリに基づいて垂直スケーリングできるようになりました。これは、GKE クラスタ バージョン 1.19.4-gke.1700 以降で利用できます。
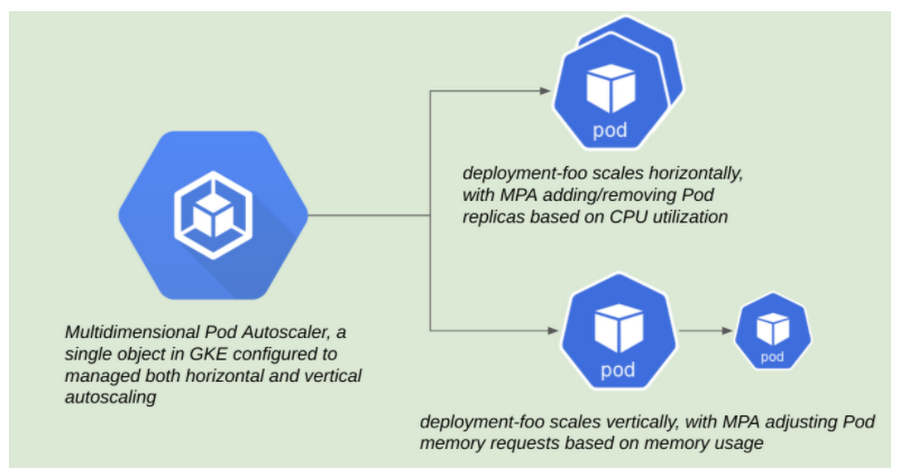
MPA スキーマには、ユーザーが目的の動作を構成するために必要な 2 つの重要な構成要素である目標と制約があります。MPA リソースについては、以下のマニフェストを参照してください。これは読みやすいように短縮しています。
目標は、ユーザーが指標のターゲットを定義できるようにするものです。最初にサポートされた指標はターゲット CPU 使用率で、これはユーザーが HPA リソースでターゲット CPU 使用率を定義する方法と同様です。MPA は、特定の Pod に追加されたレプリカ全体に負荷を分散して、これらの目標を達成しようとします。
一方、制約はもう少し厳格です。制約は目標よりも優先され、グローバル ターゲット(特定の Pod の最小レプリカ数と最大レプリカ数など)または特定のリソースのいずれかに適用できます。垂直自動スケーリングの場合、制約は、ユーザーが(a)MPA によってメモリを制御するように指定する場所であり、かつ(b)必要に応じて特定の Pod に対してメモリ リクエストの上限と下限を定義する場所です。
では、これをテストしてみましょう。
Cloud Shell をワークステーションとして使用し、MPA をサポートするバージョンの GKE クラスタを作成します。
Kubernetes ドキュメントの HPA に関する項目にある標準の php-apache サンプル Pod を使用します。これらのマニフェストでは、3 つの Kubernetes オブジェクト(Deployment、Service、多次元 Pod オートスケーラー)を作成します。
Deployment は php-apache Pod で構成され、Service タイプ: LoadBalancer を介して公開され、多次元 Pod オートスケーラー(MPA)によって管理されます。
Deployment の Pod テンプレートは、100 ミリコアの CPU と 50 メビバイトのメモリをリクエストするように構成されます。MPA は CPU 使用率 60% を目指すように構成され、使用量に基づいて Pod のメモリ リクエストを調整します。
リソースをデプロイしたら、php-apache サービスの外部 IP アドレスを取得します。
次に、hey ユーティリティを使用して php-apache Pod に人為的なトラフィックを送信し、MPA からアクションをトリガーして、Service の外部 IP アドレスを介して Pod にアクセスします。
次に、MPA は Deployment を水平にスケールし、Pod レプリカを追加して受信トラフィックを処理します。
また、各 Pod レプリカが使用している CPU 量とメモリ量を確認することもできます。
前のコマンドの出力では、Pod は Deployment で指定したメモリ リクエストを十分に上回る量のメモリを使用しているはずです。MPA オブジェクトを詳しく調べると、MPA もそのことに気づいてメモリ リクエストでの増加を推奨していることがわかります。
最後に、MPA がこれらの推奨を実行して、Pod を垂直にスケールしたことを確認する必要があります。
これが完了したことを把握するには、Pod 内の注釈で MPA によってアクションが実行されたことを確認し、また新しいメモリ リクエストが MPA のアクションを反映するように調整されていることを確認します。
まとめ
多次元 Pod オートスケーラーは、単一のリソースを介して水平および垂直自動スケーリングを制御する新しい方法により、多くの GKE ユーザーが直面している課題を解決します。GKE バージョン 1.19.6-gke.600 以降でぜひこの機能をお試しください。現在 GKE Rapid チャンネルでご利用いただけます。また、今後 MPA に追加される機能にもご注目ください。
このブログ投稿に協力してくれた Mark Mirchandani、Jerzy Foryciarz、Marcin Wielgus、Tomek Weksej に感謝します。
-Kubernetes スペシャリスト カスタマー エンジニア Anthony Bushong



