Scaling workloads across multiple dimensions in GKE
Anthony Bushong
Developer Relations Engineer
In Google Kubernetes Engine (GKE), application owners can define multiple autoscaling behaviors for a workload using a single Kubernetes resource: Multidimensional Pod Autoscaler (MPA).
The challenges of scaling Pods horizontally and vertically
The success of Kubernetes as a widely adopted platform is grounded in its support for a variety of workloads and their many requirements. One of the areas that has continuously improved over time is workload autoscaling.
Dating back to the early days of Kubernetes, Horizontal Pod Autoscaler (HPA) was the primary mechanism for autoscaling Pods. By the very nature of its name, it provided users the ability to have Pod replicas added when a user-defined threshold of a given metric was crossed. Early on this was typically CPU or Memory usage, though now there's support for custom and external metrics.
A bit further down the line, Vertical Pod Autoscaler (VPA) added a new dimension to workload autoscaling. Much like its name suggests, VPA has the ability to make recommendations on the best amount of CPU or Memory that Pods should be requesting based on usage patterns. Users can then either review those recommendations and make the call as to whether or not they should be applied, or entrust VPA to apply those changes automatically on their behalf.
Naturally, Kubernetes users have sought to get the benefits from both of these forms of scaling.
While these autoscalers work well independent of one another, the results of running both at the same time can produce unexpected results.
Picture an example where HPA adjusts the number of replicas for a Pod to maintain a target 50% CPU utilization. VPA, when configured to automatically apply recommendations, could fall into a loop of continuously shrinking CPU requests – a direct result of HPA maintaining its relatively low target for CPU utilization!
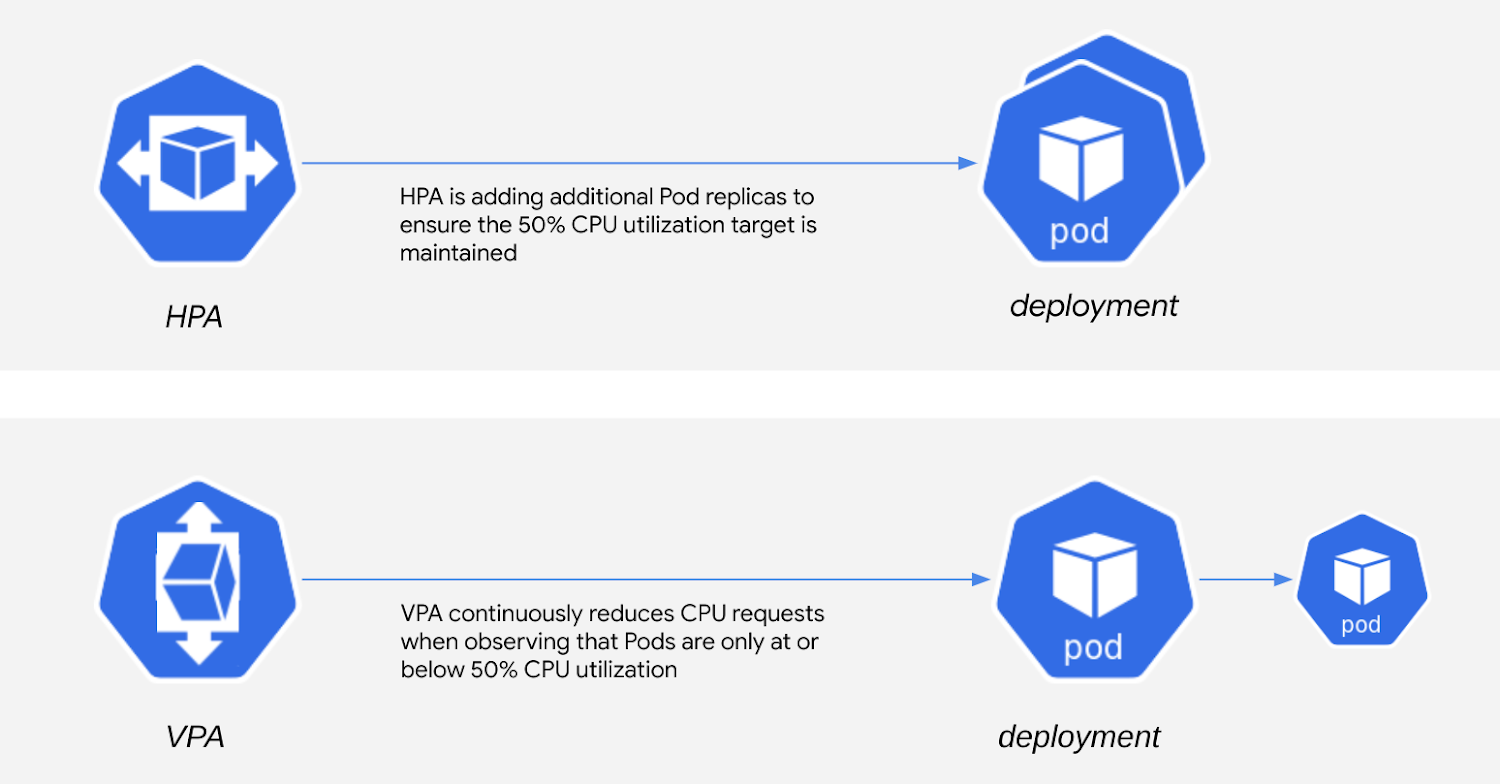
Part of the challenge here is that when configured to act autonomously, VPA applies changes for both CPU and memory. Thus, the contention can be difficult to avoid as long as VPA is automatically applying changes.
Users have since accepted compromises in one of two ways:
- Using HPA to scale on CPU or memory and using VPA only for recommendations, building their own automation to review and actually apply the recommendations
- Using VPA to automatically apply changes to CPU and memory, while using HPA based on custom or external metrics
While these workarounds are suitable for a handful of use cases, there are still workloads that would benefit from autoscaling across the dimensions of both CPU and memory.
For example, web applications may require horizontal autoscaling on CPU when CPU bound – but may also desire vertical autoscaling on memory for reliability in the event of misconfigured memory that results in OOMkilled events for the container.
Multidimensional Pod Autoscaler
The first feature available in MPA allows users to scale Pods horizontally based on CPU utilization and vertically based on memory, available in GKE clusters versions 1.19.4-gke.1700 or newer.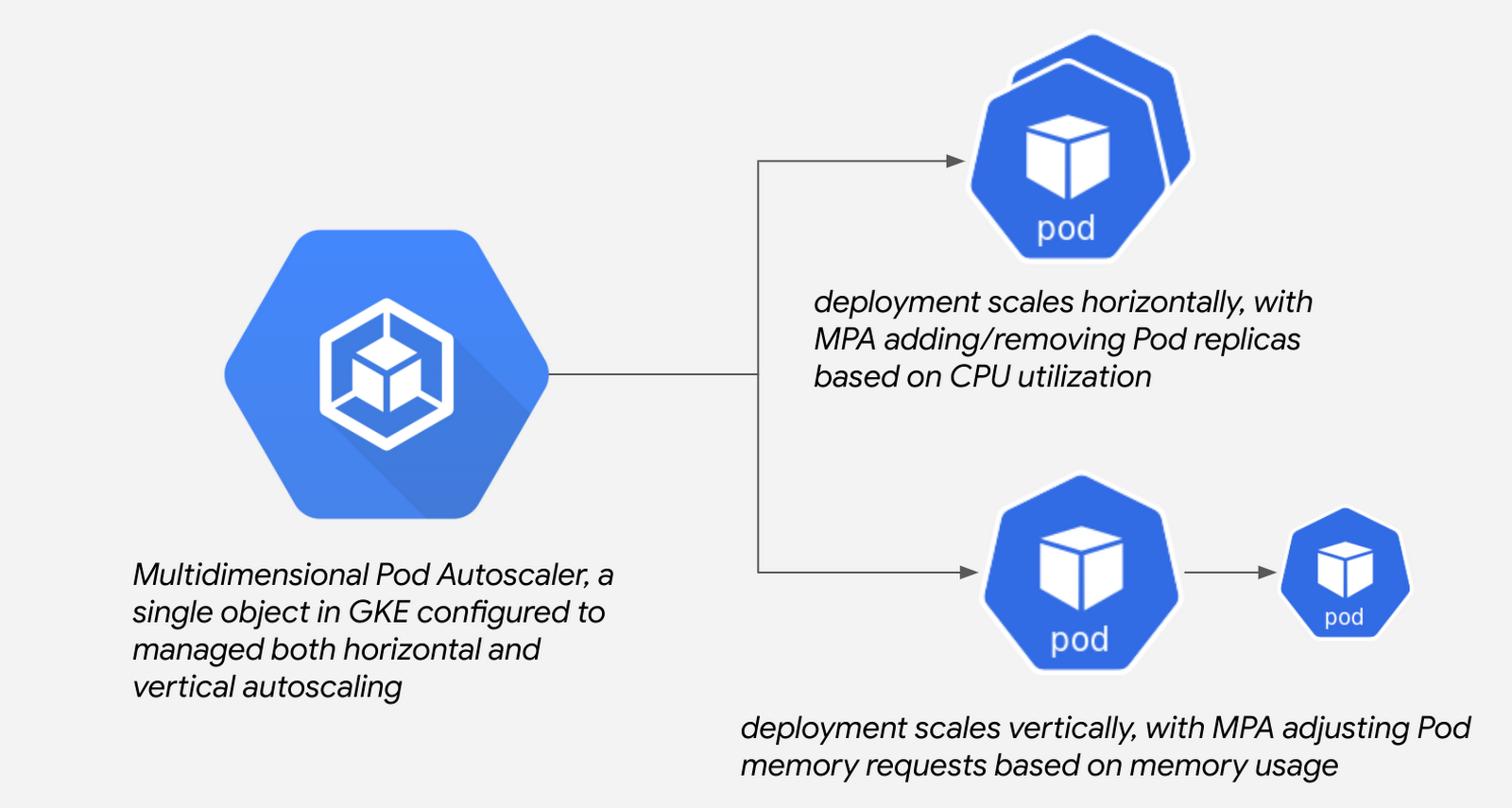
In the MPA schema, there are two critical constructs that enable users to configure their desired behavior: goals and constraints. See the below manifest for an MPA resource, which has been shortened for readability:
Goals allow for users to define targets for metrics. The first supported metric is target CPU utilization, similar to how users define target CPU utilization in an HPA resource. The MPA will attempt to ensure that these goals are met by distributing load across additional replicas of a given Pod.
Constraints, on the other hand, are a bit more stringent. These take precedence over goals, and can be applied either to global targets – think min and max replicas of a given Pod – or specific resources. In the case of vertical autoscaling, this is where users get to a.) specify that memory is controlled by MPA and b.) define the upper and lower boundaries for memory requests for a given Pod should they need to.
Let's test this out!
We'll use Cloud Shell as our workstation and create a GKE cluster with a version that supports MPA:
We'll use the standard php-apache example Pods from the Kubernetes documentation on HPA. These manifests will create three Kubernetes objects - a Deployment, a Service, and a Multidimensional Pod Autoscaler.
The Deployment consists of a php-apache Pod, is exposed via a Service `type: LoadBalancer`, and is managed by a Multidimensional Pod Autoscaler (MPA).
The Pod template in the Deployment is configured to request 100 millicores in CPU and 50 mebibytes in memory. The MPA is configured to aim for 60% CPU utilization and adjusting Pod memory requests based on usage.
Once we have the resources deployed, grab the External IP address for the php-apache Service. Your External IP address will likely vary from the below example.
We will then use the `hey` utility to send artificial traffic to our php-apache Pods and thus trigger action from the MPA. We will be sending traffic to the Pods via the Load Balancer's external IP address.
The MPA will then scale the Deployment horizontally, adding Pod replicas to handle the incoming traffic.
Run the below command in a separate terminal to watch the example app scale up.
We can also observe the amount of CPU and memory each Pod replica is using:
In the output from the previous command, Pods should be utilizing well over the memory requests that we specified in the Deployment. Digging into the MPA object, we can see that the MPA notices that as well, recommending an increase in memory requests.
Eventually, we should see MPA actuate these recommendations and scale the Pods vertically.
We will know this is complete by observing an annotation in any of the Pod replicas that denotes action was taken by the MPA, as well as the new memory requests adjusted to reflect the MPA's action.
Conclusion
Multidimensional Pod Autoscaler solves a challenge that many GKE users have faced, exposing a new method to control horizontal and vertical autoscaling via a single resource. Try it in GKE versions 1.19.4-gke.1700+, and stay tuned for additional functionality in MPA!
A special thanks to Mark Mirchandani, Jerzy Foryciarz, Kaslin Fields, Marcin Wielgus, and Tomek Weksej for their contributions to this blog post.