Vertex AI の Reduction Server を使用してトレーニングのパフォーマンスを最適化する
Google Cloud Japan Team
※この投稿は米国時間 2021 年 8 月 26 日に、Google Cloud blog に投稿されたものの抄訳です。
ディープ ラーニングのモデルがより複雑になり、トレーニング データセットのサイズが大きくなってきているため、ML システムの開発とデプロイにおいてトレーニング時間が主なボトルネックの 1 つになっています。GPU を利用できる場合でも、データセットが大きいと、ディープ ラーニング モデルが収束するまでに数日または数週間かかることもあります。正しいハードウェア構成を使用することで、トレーニング時間を数時間、場合によっては数分にまで短縮できます。トレーニング時間が短くなると、モデリングの目標を達成するための反復をより速く行えるようになります。
大規模モデルのトレーニング時間を短縮するために、多くのエンジニアリング チームは ML アクセラレータのスケールアウト クラスタを使用する分散トレーニングを採用しています。とはいえ、大規模な分散トレーニングには特有の課題が伴います。具体的には、ノード間のネットワーク帯域幅が限られていると、その性質として分散トレーニングのパフォーマンス最適化が難しくなり、特に大規模クラスタ構成でより顕著になります。
この記事では、Reduction Server を紹介します。これは、同期データ並列型アルゴリズムのために、NVIDIA GPU でのマルチノードの分散トレーニングの帯域幅とレイテンシを最適化する、Vertex AI の新しい機能です。同期データ並列処理は、TensorFlow の MultiWorkerMirroredStrategy、Horovod、PyTorch Distributed など広く採用されている分散トレーニング フレームワークの基礎となるものです。これらのフレームワークが使用する all-reduce 集団オペレーションの帯域幅使用率とレイテンシを最適化することにより、Reduction Server は大規模トレーニング ジョブの時間とコストの両方を削減できます。
この記事では、データ並列処理、同期トレーニング、all-reduce などの分散トレーニングの分野の重要な用語について説明します。また、Reduction Server を活用する Vertex Training ジョブを構成して送信する方法を紹介します。加えて、MNLI データセットに対して Reduction Server を使用することで BERT モデルを調整するためのサンプルコードを提示します。
GPU での分散データ並列型トレーニングの概要
ここに単純な線形モデルがあり、計算グラフとして考えることができるとします。次の図で、matmul op は X と W のテンソルを受け取ります。それぞれトレーニング バッチと重みです。結果のテンソルが、モデルのバイアス項であるテンソル b とともに add op に渡されます。この op の結果は Ypred であり、これがモデルの予測値となります。

この計算グラフを、複数のワーカーを活用できる手法で実行したいと思います。1 つは、モデル並列処理の一種である、モデルの異なるレイヤを異なるマシンまたはデバイスに渡す方法です。また、各ワーカーが同じモデルを使用して、それぞれがトレーニングの各ステップで入力バッチの別箇所を担当するよう、データセットを分散させるという方法もあります。これは、データ並列処理として知られています。以上の 2 つの方法を組み合わせることも可能です。一般的に、モデルに計算の独立した部分が含まれていて、それらを並列で実行できる場合、モデル並列処理が最適です。データ並列処理はあらゆるモデル アーキテクチャに適用できるため、分散トレーニングでより広範に採用されています。
次の図は、データ並列処理の例を示しています。入力バッチ X は半分に分割され、1 つのスライスは GPU 0 に送信され、もう 1 つは GPU 1 に送信されます。この場合、各 GPU は同じ op を、データの別のスライスに対して計算します。

その後の勾配の更新は同期的に行われます。
各ワーカー デバイスは、入力データの別のスライスに対してフォワード パスを実行して、損失を計算します。
各ワーカー デバイスは、損失関数に基づいて勾配を計算します。
これらの勾配は、すべてのデバイス全体で集約 (リダクション)されます。
最適化アルゴリズムがリダクションされた勾配を使用して重みを更新し、デバイスの同期状態を維持します。
データ並列処理を使用すると、複数の GPU を持つ単一のマシン、またはそれぞれが 1 つもしくは複数の GPU を持つ複数のマシンによるトレーニング時間を短縮できます。この記事の以降の説明では、コンピューティング ワーカーが GPU デバイスに 1 対 1 でマッピングされることを前提とします。たとえば、2 つの GPU デバイスを持つ単一のコンピューティング ノードには 2 つのワーカーがあります。そして、各ノードが 2 つの GPU デバイスを持つ 4 ノードクラスタは、8 つのワーカーを管理します。
データ並列型分散トレーニングの重要な側面の 1 つが、勾配集約です。各ワーカーは、他のすべてのワーカーが現在のステップを終了するまで次のトレーニング ステップに進むことができません。そのため、この勾配計算が分散トレーニングでの同期に関して主要なオーバーヘッドとなります。最も多く採用されている分散トレーニング フレームワークでは、この勾配集約を実行するために、同期型の all-reduce 集団通信オペレーションを活用しています。
all-reduce は、分散ワーカーで一式の配列を単一の配列にリダクションしてから各ワーカーに再分配する、集団通信オペレーションです。勾配集約では、リダクション オペレーションは加算です。

上の図は、4 つの GPU ワーカーを示しています。ワーカーは all-reduce オペレーションの前の時点で、それぞれのトレーニング データのバッチに対して計算された勾配の配列を持っています。各ワーカーが受け取ったトレーニング データのバッチはそれぞれ異なるため、その後の勾配配列(g0、g1、g2、g3)はすべて異なります。
これが all-reduce オペレーションが完了すると、各ワーカーは他ワーカーと同じ配列を持つようになります。この配列は、すべてのワーカーの勾配配列を集約(加算)することで計算されます。
この集約を効率的に実装するためのアルゴリズムは多数存在しています。一般的には、ワーカーは通信リンクのトポロジを利用して互いに通信し、勾配を交換します。選択するトポロジと勾配の交換方法は、アルゴリズムで必要になる帯域幅とそのレイテンシに影響を与えます。
all-reduce 実装の簡単な例として、Ring All-reduce があります。Ring All-reduce ではワーカーが論理リングを形成し、隣のワーカーとのみ通信します。
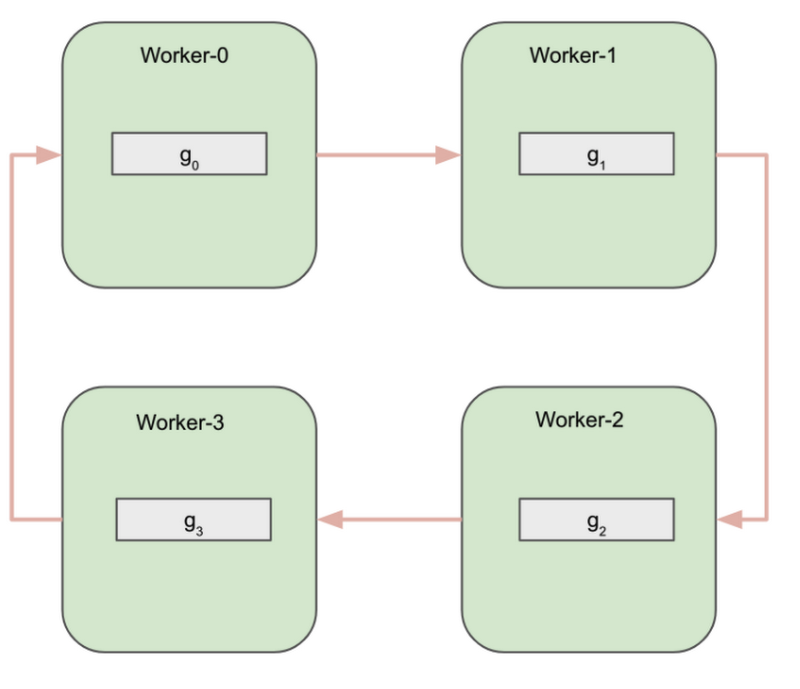
このアルゴリズムは、論理的に 2 つのフェーズに分割できます。
Reduce-scatter フェーズ
All-gather フェーズ
Reduce-scatter フェーズの開始時点で、各ワーカーの勾配配列は N 個の等しいサイズのブロックに分割されます。N はワーカーの数であり、この例では 4 です。
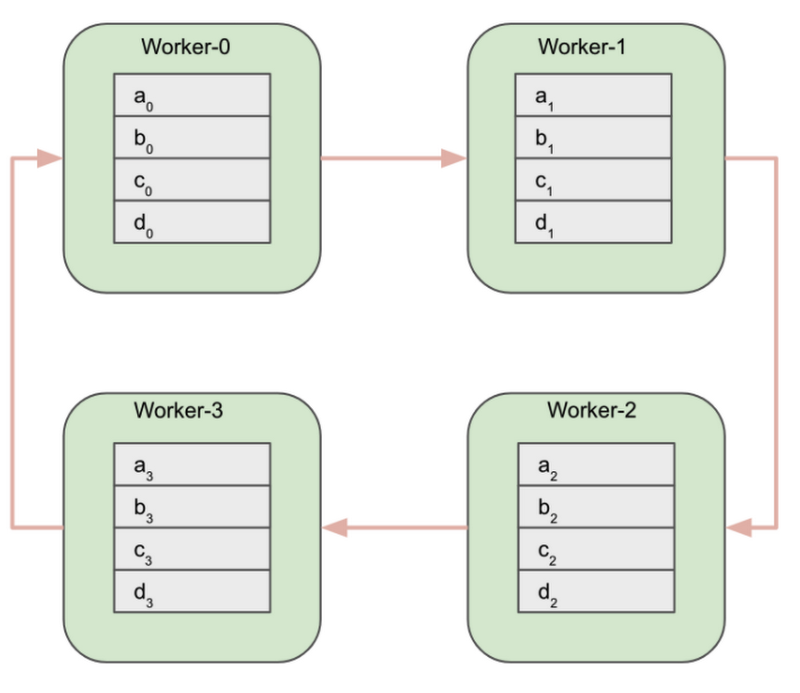
次のステップで、各ワーカーは同時に 1 つのブロックを隣のワーカーに送信し、反対側のワーカーから別のブロックを受信します。
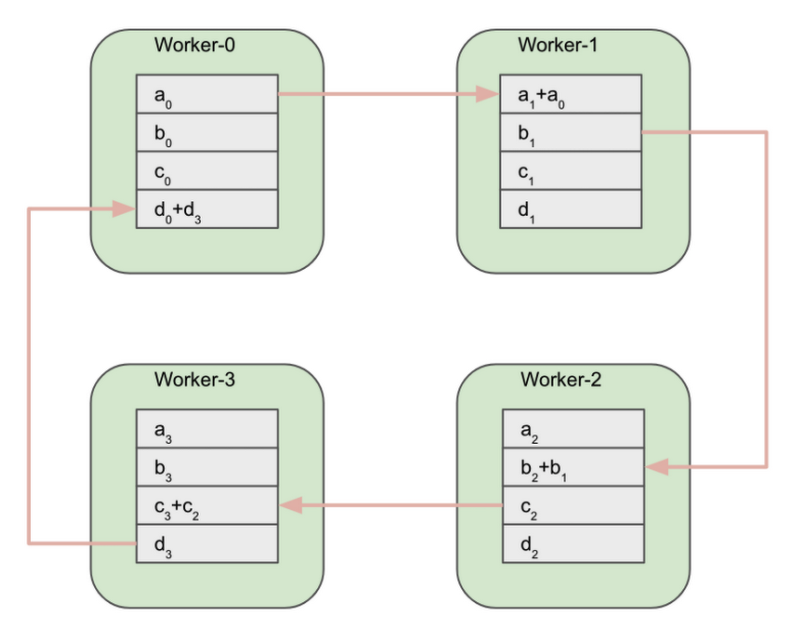
Worker-0 が a0 ブロックを Worker-1 に送信します。 Worker-1 が b1 ブロックを Worker-2 に送信します。Worker-2 が c2 ブロックを Worker-3 に送信します。最後に、Worker-3 が d3 ブロックを Worker-0 に送信します。すでに説明した通り、リングでのすべての送信および受信オペレーションは同時に行われます。
このステップが完了すると、各ワーカーは隣のワーカーから受信したブロックを使用して、部分的なリダクションを行うことができます。
部分的なリダクションの完了後、ワーカーは部分的にリダクションされたブロックを交換します。Worker-1 がリダクションされた a1+a0 ブロックを Worker-2 に送信します。Worker-2 がリダクションされた b2+b1 ブロックを Worker-3 に送信します。その他に関しても同様です。

Reduce-scatter フェーズの終了時点で、各ワーカーは元の配列を完全にリダクションしたブロックを 1 つ持っています。
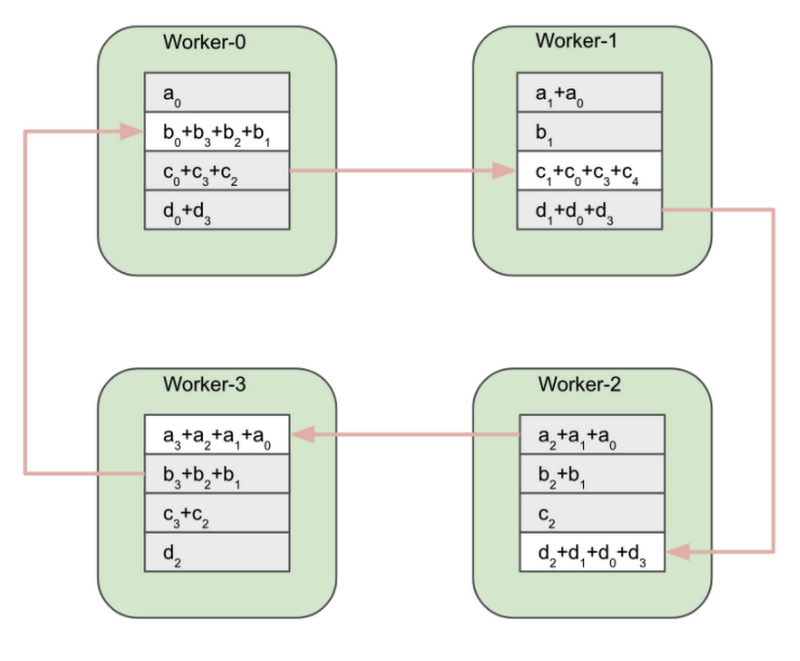
この時点で、アルゴリズムの All-gather フェーズが開始します。

Worker-0 が完全にリダクションされた b0+b3+b2+b1 ブロックを Worker-1 に送信します。Worker-1 が c1+c0+c3+c4 ブロックを Worker-2 に送信します。その他のワーカーも同様です。
All-gather フェーズの終了時点で、すべてのワーカーは完全にリダクションされた同じ配列を持ちます。
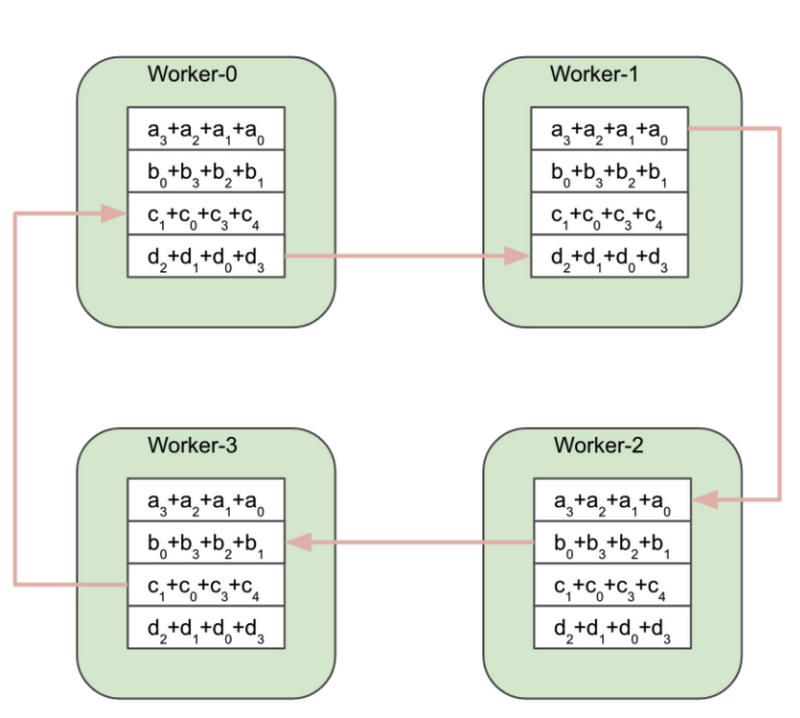
Reduce-scatter フェーズ中に、各ワーカーは N-1 個のデータのブロックを送受信します。N はワーカーの数です。All-gather フェーズ中に、同じ数のブロックが交換されます。合計で、Ring All-reduce アルゴリズムにおいて 2(N-1) 個のデータのブロックが各ワーカーによって送受信されます。勾配配列のサイズが K バイトの場合、all-reduce オペレーション中に送受信されるバイト数は (2(N-1)/N)*K になります。
Ring All-reduce の欠点は、アルゴリズムのレイテンシが、ワーカーの数に応じて直線的に増加することです。そのため、大規模クラスタに対してスケーリングすることは難しくなります。ツリー型トポロジに基づく all-reduce の別の実装では、対数的なスケーリングが可能になります。
Reduction Server アルゴリズム
Vertex Reduction Server は、追加のワーカーロールである「レデューサ」を導入することにより、特有の通信リンクトポロジを使用します。レデューサが提供するのは、ワーカーからの勾配の集約という 1 つの機能だけです。レデューサは勾配を計算せず、モデル パラメータも維持しません。機能が限られているため、レデューサは多くの計算能力を必要とせず、比較的低コストなコンピューティング ノードでも実行できます。
次の図は、4 つの GPU ワーカーと 5 つのレデューサを持つクラスタを示しています。GPU ワーカーはモデルのレプリカを維持して、勾配を計算し、パラメータを更新します。レデューサは GPU ワーカーから勾配のブロックを受信して、ブロックをリダクションし、リダクションされたブロックを GPU ワーカーに対して再分配します。
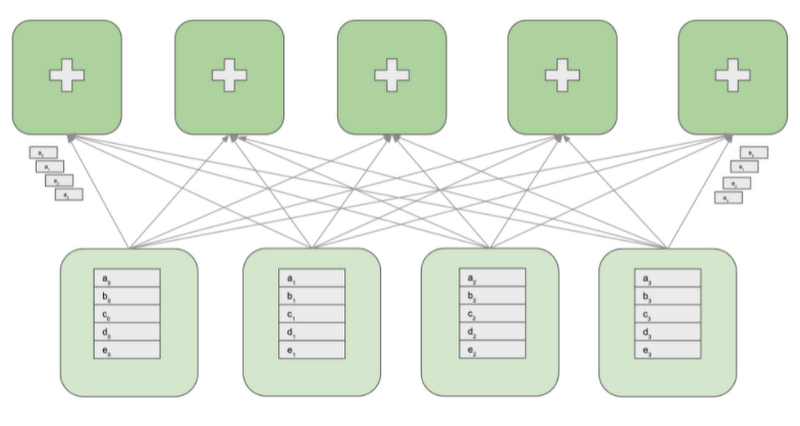
all-reduce オペレーションを実行するために、各 GPU ワーカーの勾配配列は最初に M 個のブロックにパーティショニングされます。M はレデューサの数です。特定のレデューサは、すべての GPU ワーカーから送られてくる、勾配の同じパーティションを処理します。例として上の図では、最初のレデューサは a0 から a3 までのブロックをリダクションし、2 番目のレデューサは b0 から b3 までのブロックをリダクションします。受信したブロックをリダクションした後、レデューサはリダクションされたパーティションをすべての GPU ワーカーに送り返します。
勾配配列のサイズが K バイトだと仮定すると、トポロジの各ノードは K バイトのデータを送受信します。これは、リングおよびツリー ベースの all-reduce 実装で交換されるデータのおよそ半分です。また、レイテンシがワーカーの数に依存しないことも Reduction Server の利点の 1 つです。
次の表では、Reduction Server のデータ転送とレイテンシの特性を、リングおよびツリーベースの all-reduce アルゴリズムと比較します。N はワーカーの数で、K は勾配配列のサイズです(バイト)。

Reduction Server を Vertex Training とともに使用する
Reduction Server は、all-reduce 集団オペレーションに対して NVIDIA NCCL ライブラリを使用する分散トレーニング フレームワークとともに使用できます。トレーニング アプリケーションを変更または再コンパイルする必要はありません。
Reduction Server を Vertex Training のカスタムジョブとともに使用するには、次のことを行う必要があります。
Vertex Training ワーカープールのトポロジを選択します。
トレーニング コンテナ イメージに、Reduction Server NVIDIA NCCL トランスポート プラグインをインストールします。
Reduction Server ワーカープールを含む Vertex Training のカスタムジョブを構成し、送信します。
それぞれのステップについて、次のセクションで詳細を説明します。
Vertex Training ワーカープールのトポロジの選択
マルチワーカー トレーニング ジョブを Vertex AI で実行するには、トレーニング クラスタで複数のマシン(ノード)を指定します。トレーニング サービスにより、指定したマシンタイプに応じてリソースが割り当てられます。特定のノード上で実行中のジョブは「レプリカ」と呼ばれます。同じ構成のレプリカのグループはワーカープールと呼ばれます。Vertex AI は、異なる種類のマシンタスクに対応するために、最大で 4 つのワーカープールを提供します。Reduction Server を使用する場合、最初の 3 つのワーカープールが使用されます。
ワーカープール 0 は、プライマリ、チーフ、スケジューラ、または「マスター」を構成します。このワーカーは通常、チェックポイントの保存やサマリー ファイルの書き込みなど、いくつかの追加の作業を引き受けます。クラスタにチーフワーカーは 1 つしかないので、ワーカープール 0 のワーカー数は必ず 1 になります。
ワーカープール 1 で、クラスタの残りのワーカーを構成します。
ワーカープール 2 は、Reduction Server のレデューサを管理します。レデューサの数と種類を選択する際に、レデューサ レプリカのマシンタイプでサポートされているネットワーク帯域幅を考慮する必要があります。GCP では、VM のマシンタイプによって最大の下り(外向き)帯域幅が決まります。たとえば、n1-highcpu-16 マシンタイプの下り(外向き)帯域幅は、32 Gbps に制限されています。
レデューサは勾配のブロックの集約という、非常に限られた機能だけを実行するので、低電力で費用対効果の優れたマシンでも実行できます。勾配が大量である場合でも、この計算では高速なハードウェア、高性能な CPU リソース、大量のメモリ リソースは必要ありません。ただし、ネットワークのボトルネックを避けるには、レデューサ ワーカー プールのすべてのレプリカの集約帯域幅の合計は、GPU ワーカーをホストするワーカープール 0 および 1 のすべてのレプリカの集約帯域幅の合計と同じか、それ以上である必要があります。
たとえば、最大で 800 Gbps の集約帯域幅を持つ、8 つの GPU を搭載したレプリカ(GPU 搭載の VM は、最大 100 Gbps の下り(外向き)帯域幅をサポートします)で分散トレーニング ジョブを実行し、32 Gbps の下り(外向き)帯域幅を持つレデューサを使用する場合、少なくとも 25 個のレデューサが必要になります。
レデューサ ワーカー プールのサイズを妥当な水準に保つには、32 Gbps の下り(外向き)帯域幅を持つマシンタイプを使用することをおすすめします。これは、Vertex Training の CPU のみのマシンで利用できる最大帯域幅です。Computer Vision と NLP ドメインにおいて、多くの主流のディープ ラーニング モデルに対して実行されたテストに基づいて、16~32 個の vCPU と 16~32 GB の RAM を備えたレデューサを使用することをおすすめします。さまざまな分散トレーニング シナリオに最適と思われる初期の構成は、n1-highcpu-16 マシンタイプです。
Reduction Server NVIDIA NCCL トランスポート プラグインのインストール
Reduction Server は、NVIDIA NCCL トランスポート プラグインとして実装されます。このプラグインは、トレーニング アプリケーションを実行するために使用するコンテナ イメージにインストールする必要があります。
この記事で示されているコードには、Vertex のビルド済み TensorFlow 2.5 GPU Docker イメージ(本プラグインがインストール済みのもの)をベース イメージとして使用する Dockerfile のサンプルが含まれています。
Dockerfile に次を含めることで、プラグインを直接インストールすることもできます。
Reduction Server を使用する Vertex Training ジョブの構成
まず、Vertex SDK をインポートして初期化します。
次に、カスタムジョブの構成を指定します。次の仕様では、3 つのワーカープールが定義されています。
ワーカープール 0 は、4 つの NVIDIA A100 Tensor Core GPU を持つ 1 つのワーカーを持っています。
ワーカープール 1 は、追加の 7 つの GPU ワーカーを定義しており、結果として全体で 8 つの GPU ワーカーを持ちます。
ワーカープール 2 はマシンタイプが n1-highcpu-16 の 14 個のレデューサを指定しています。
なお、ワーカープール 0 と 1 は、トレーニング アプリケーションを Reduction Server NCCL トランスポート プラグインで構成されたコンテナ イメージ内で実行します。ワーカープール 2 は、Vertex AI が提供する Reduction Server コンテナ イメージを使用します。
次に、CustomJob を作成して実行します。
Cloud Console の [トレーニング] セクションにある [CUSTOM JOBS] タブに、トレーニング ジョブが表示されます。

Reduction Server のパフォーマンスとコストの利点の分析
Reduction Server が、トレーニング ジョブにかかる時間にどれほどの影響を与え、結果としてどのくらいコストを削減できるかは、トレーニング ワークロードの特性に依存します。
通常、この効果が最大化するのは、トレーニング モデルに大量のパラメータが含まれていて、妥当な時間内にトレーニングを完了するために多数の GPU を必要とする、計算負荷が高いワークロードになります。これは、標準のリングおよびツリーベースの all-reduce 集団オペレーションのレイテンシが、GPU ワーカーの数と勾配配列のサイズに比例するためです。Reduction Server ではその両方を最適化します。レイテンシは GPU ワーカーの数に依存せず、all-reduce オペレーション中に転送されるデータの量は、リングおよびツリーベースの実装よりも少なくなります。
このカテゴリに属するワークロードの例は、BERT などの大規模な言語モデルの事前トレーニングと微調整です。予備実験に基づくと、この種類のワークロードの場合、トレーニング時間は 30%~40% 減少すると予測されます。
次の図は、それぞれが 8 つの NVIDIA A100 Tensor Core GPU を搭載する 8 つの GPU ワーカーノードを使用して、MNLI データセットの TensorFlow Model Garden からの BERT モデルを微調整した結果を示しています。

この実験では、20 個のレデューサ ノードを追加することで、トレーニングのスループットがおおよそ毎秒 0.4 ステップから毎秒 0.7 ステップまで増加しました。
トレーニング時間の短縮により、トレーニング コストも削減できます。とはいえ、多くのミッション クリティカルなシナリオでは、トレーニング サイクルが短くなることで、計算リソースの使用量における直接的な節約だけでなく、もっと大きなビジネス上の価値がもたらされます。たとえば、デプロイ期間の制約内で、より高い予測パフォーマンスでモデルをトレーニングできるようになります。
次の表は、上記の実験のステップごとのトレーニング コストを示しています。このコスト予測は、南北アメリカ リージョンでのカスタム トレーニング モデル向け Vertex AI 料金に基づいています。

次のステップ
この記事では、勾配集約に特化した特別なワーカータイプを使用することによってレイテンシと転送データを最小化する、all-reduce の新しい実装を提供する Vertex Reduction Server アーキテクチャについて説明しました。実際の例で最初から最後まで試してみたい方は、こちらのノートブックをご覧ください。Reduction Server を使用して、自分で実験してみましょう。それでは、分散トレーニングをお楽しみください。
-ソリューション アーキテクト Jarek Kazmierczak
-デベロッパー アドボケイト Nikita Namjoshi
-ソフトウェア エンジニア Chang Lan




