Feature Attributions の監視:Google はいかに大規模な ML サービスの障害を乗り越えたのか
Google Cloud Japan Team
※この投稿は米国時間 2021 年 9 月 29 日に、Google Cloud blog に投稿されたものの抄訳です。
Google で起きた大規模 MLOps の危機
クラウディ・グルシアは Google のソフトウェアエンジニアであり、何十億ものユーザーにコンテンツを推薦している機械学習(ML)モデルに関わっています。2019 年 10 月、彼は ML 監視サービスからアラートを受けました。モデルの特徴量(ここでは、この特徴量を F1 とします)の重要度が下がってきていたのです。この特徴量の重要度は、モデルの予測において、特徴量の影響の大きさを表す指標である「Feature Attributions」で計測されています。この重要度の減少とともに、モデルの精度が急激に低下していました。
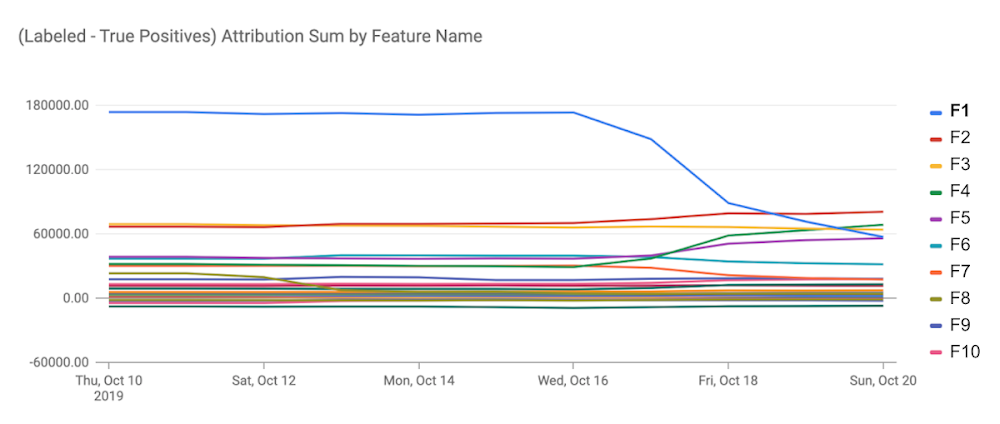
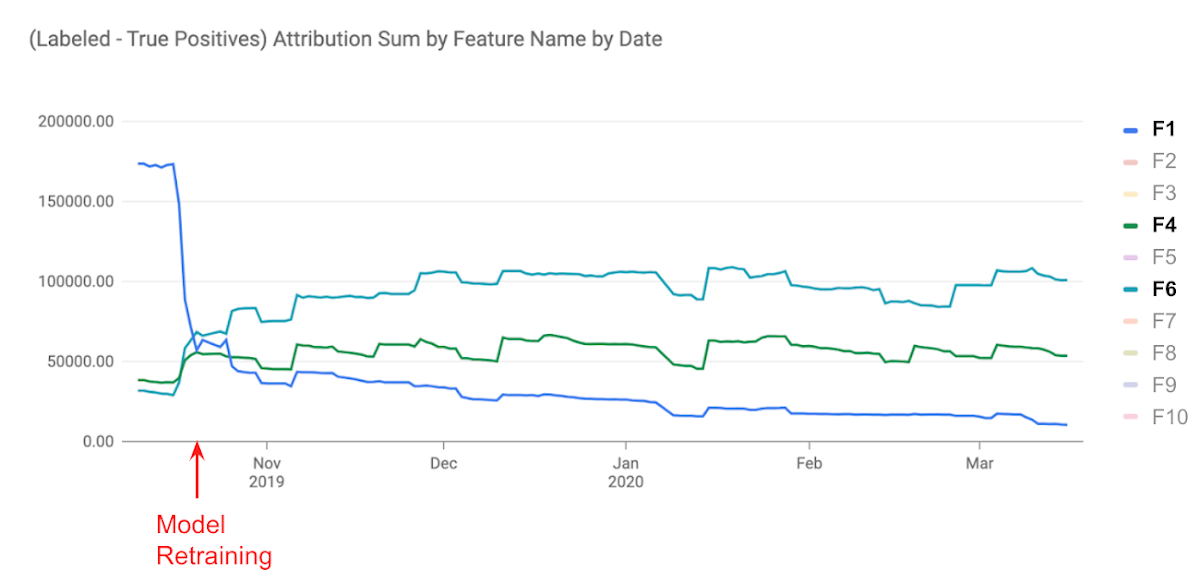
このアラートを受け、彼はすばやくモデルを再学習させました。その結果、F1 の代替となる 2 つの特徴量(F4 および F6)の重要度を向上し、モデルの精度劣化を防ぐことができました。彼の迅速な修正により、Google の大規模サービスのユーザーエクスペリエンスを保つことができたのです。
Ground truth(正解)がない状態での監視
特徴量 F1 に何が起きたのでしょう。F1 はクラウディとは異なるチームが作り出した特徴量でした。さらなる調査によって、あるインフラの移行により F1 の網羅率が急激に損なわれたこと、そしてその結果、複数の事例で F1 の重要度が損なわれていたことが判明しました。
このようなトラブルを検知するには、モデルの質的な指標(精度など)を監視し、閾値を下回ったら開発者に報告するのが最も簡単です。しかし、ほとんどの指標はモデルの予測と正解(ground truth)を比較する必要があります。この正解は即座に利用できないことが多々あります。例えば、不正行為の検知、金融サービスの与信判断、オンライン広告でのコンバージョン率の推定などのタスクにおいて、予測に対する正解は数日、数週間、時には数か月遅れで得られることがあります。
正解のない状況下において、Google の ML エンジニアはモデルの劣化を検知する代替策を講じてきました。この対策は利用可能な観測値として、モデルへの入力とその予測値を使用します。主な2つの対策は以下の通りです。
Feature Distribution monitoring: 特徴量分布におけるスキューやドリフトを検知するものです。
Feature Attribution monitoring: 特徴量の重要度におけるスキューやドリフトを検知するものです。
最近の記事「Vertex Model Monitoring で活用する Google の MLOps 監視手法」では、1つ目に紹介したFeature Distribution の監視を解説しました。この時、サービス中に発生する特徴量のスキューと異常値を検知するために、学習時または他のベースラインと比較していました。本稿では、Googleの大規模なMLサービスの監視において広く利用されているFeature Attributions monitoring について議論します。
Feature Attributions の監視
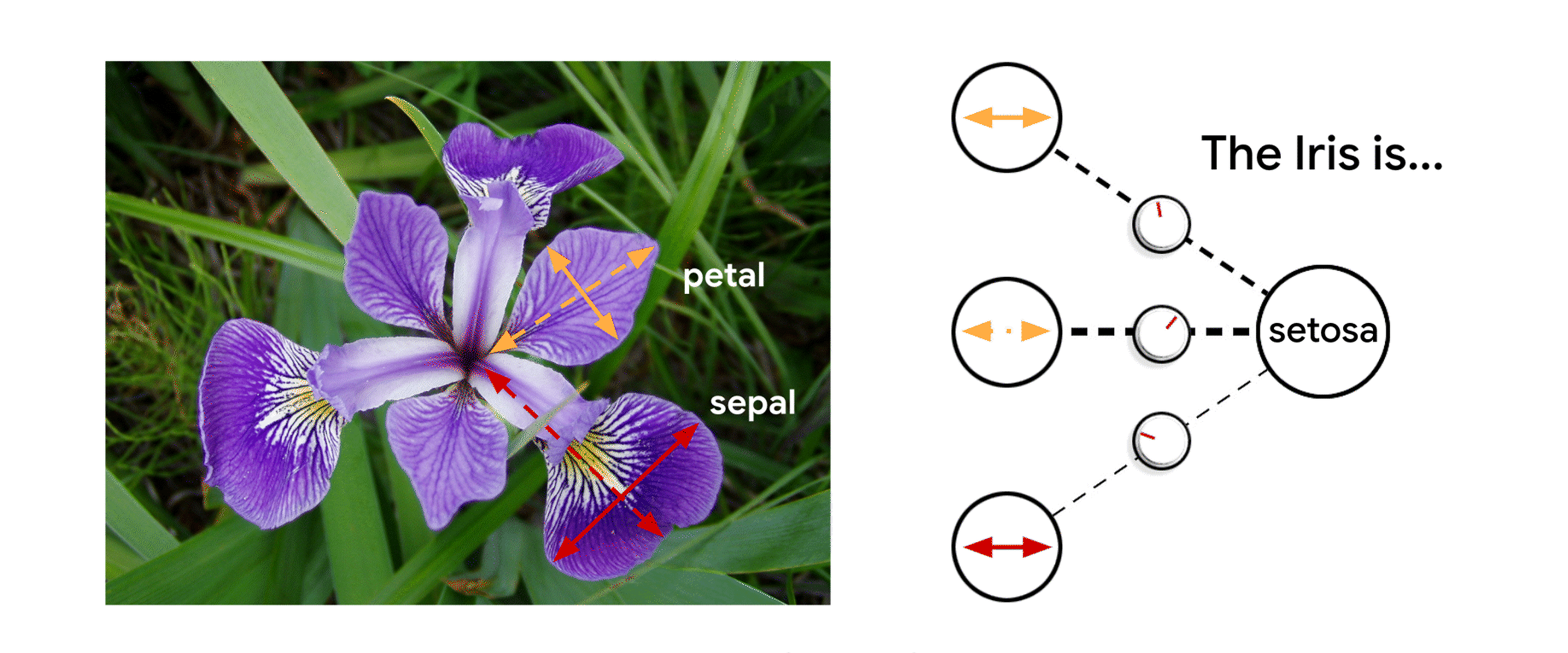
Feature Attributionsは、与えられた入力におけるモデルの予測を、個々の入力の特徴量に対応させて説明する手法の一種です。アトリビューションは予測に対する特徴量の貢献度に比例し、特徴量が予測に対して役立つかどうかを示します。最終的に、すべての特徴におけるアトリビューションはモデルの予測を計算するために必要となります。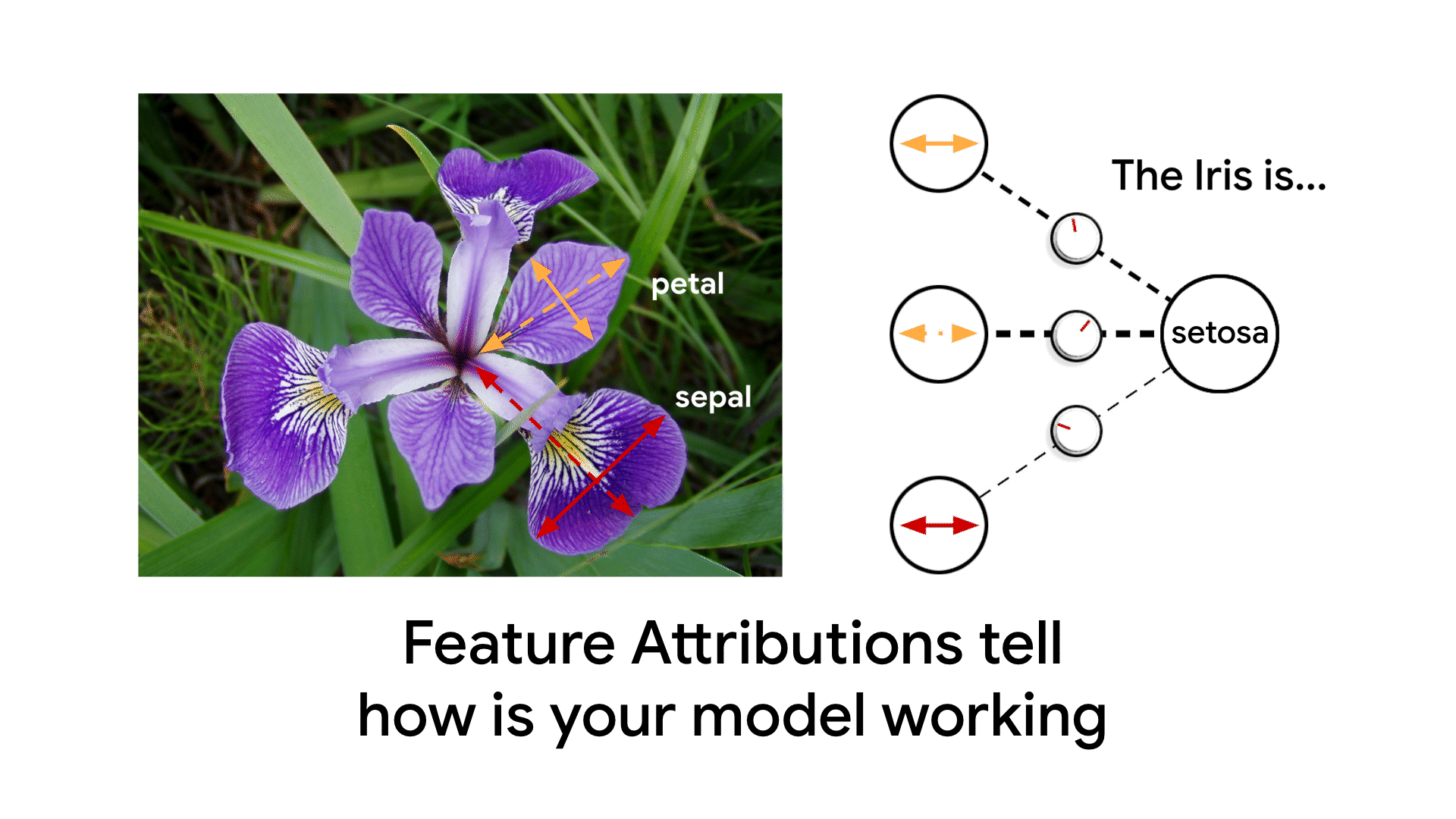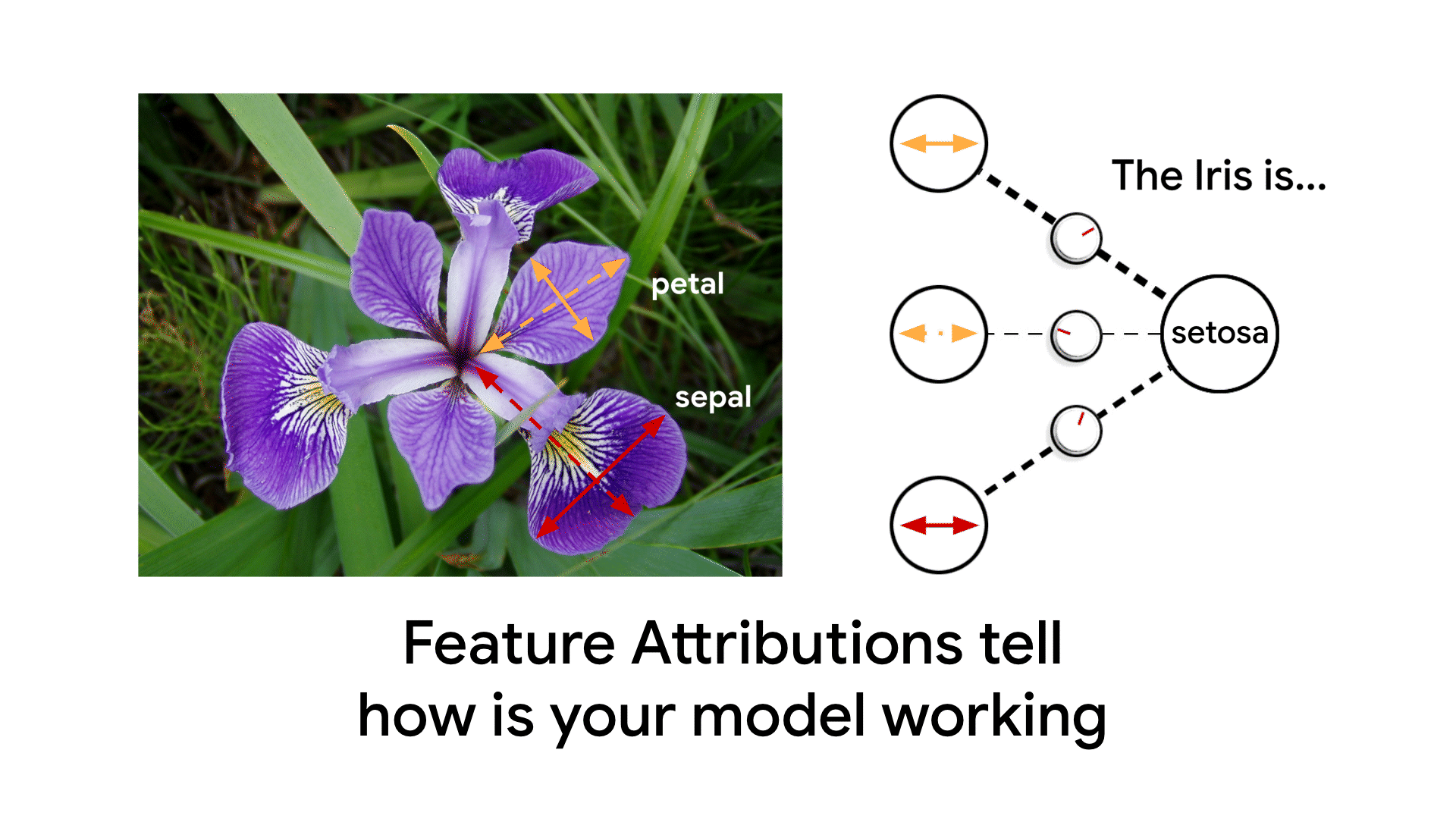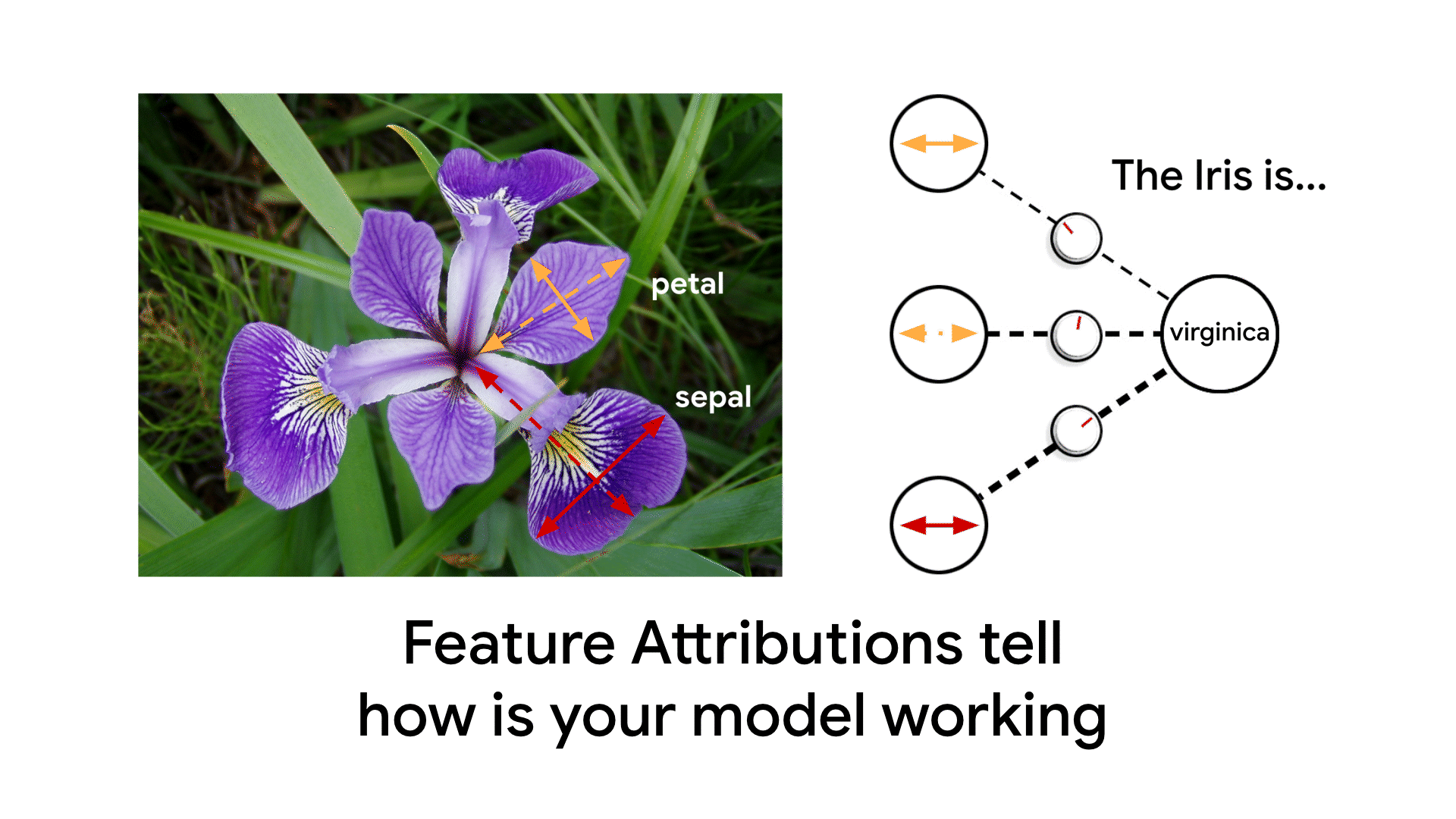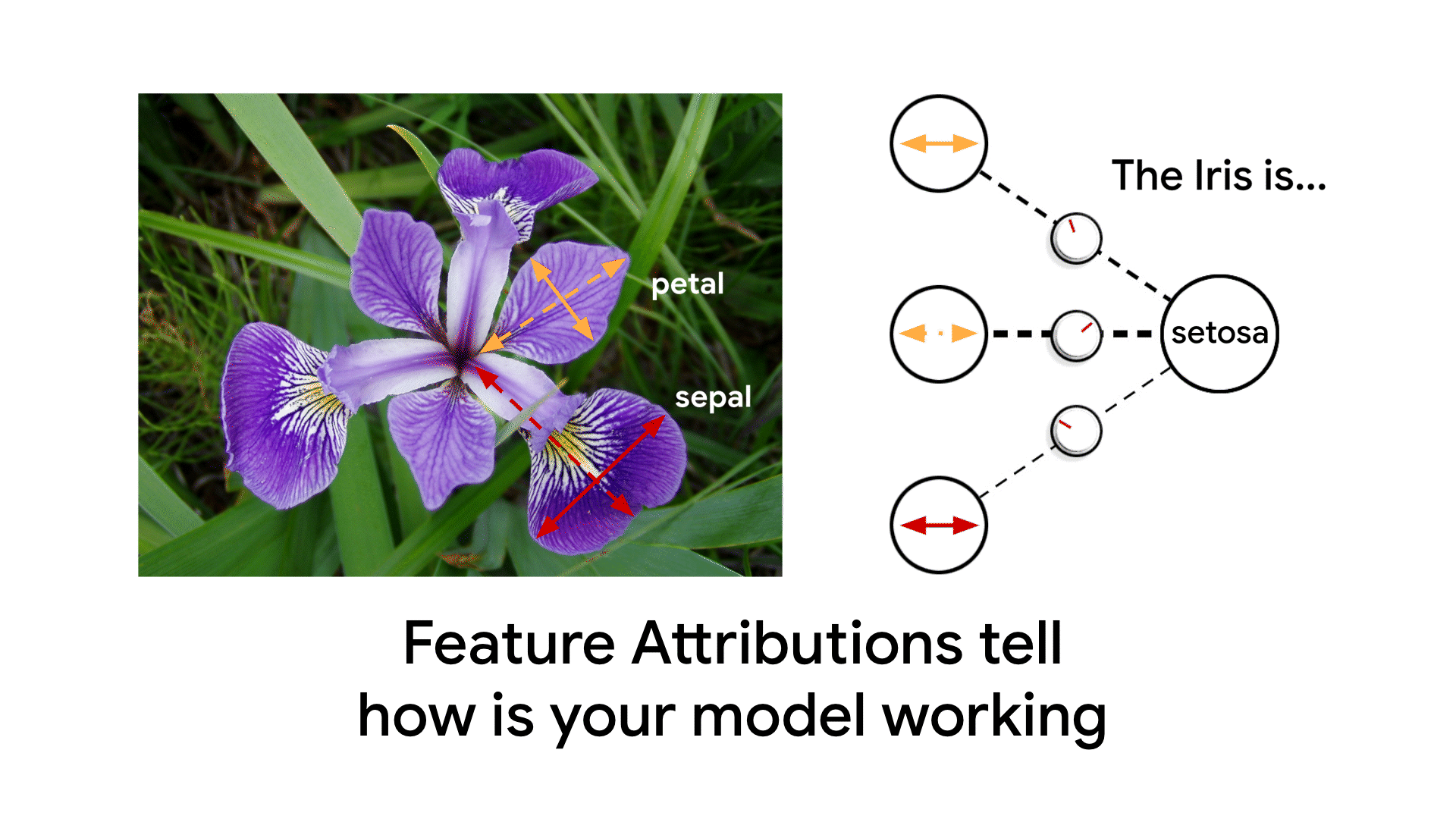
Feature Attributions はどのようにモデルが機能しているか教えてくれます
産業界や Google では、Feature Attributions はモデルの透明性改善、モデルのデバッグ、モデルのロバスト性評価において上手く機能してきました。Feature Attributions を計算する代表的なアルゴリズムとして、SHAP ・ Integrated Gradients ・ LIMEがあり、各アルゴリズムはそれぞれ特性が異なります。詳細な技術的な議論については、AI Explanations Whitepaperを参照ください。
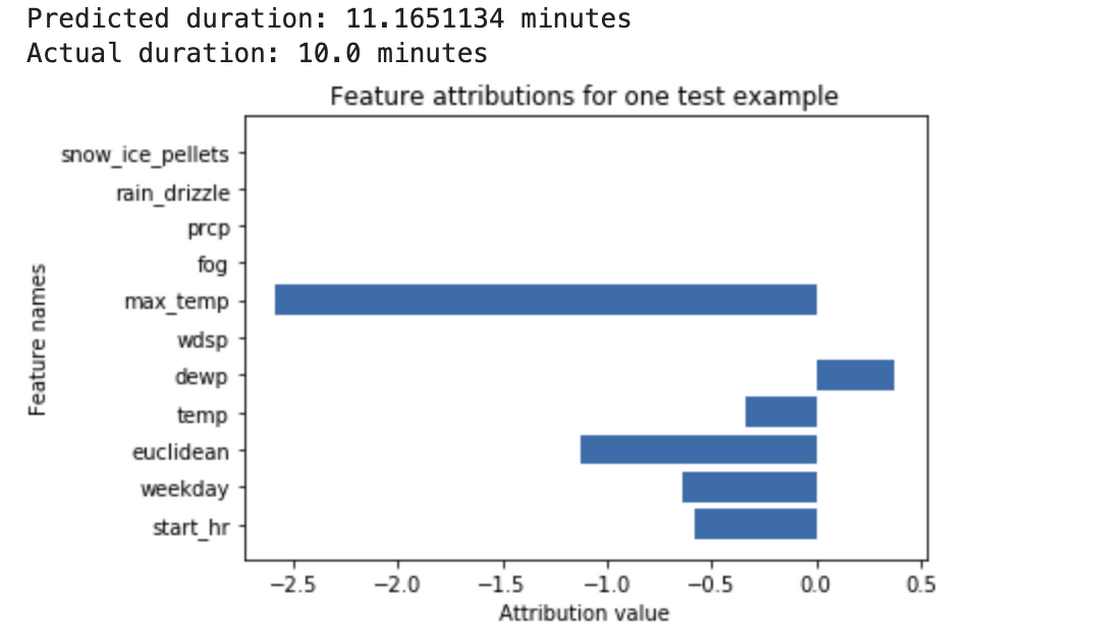
Feature Attributions の監視
Feature distribution の監視は手軽に使える手法です。しかし、以下の点において注意が必要です。
(1) 特徴量のドリフトスコアは、ドリフトがモデルの予測に寄与する影響を明らかにするものではありません。
(2) 特徴量の種類や表現(数値、カテゴリ、画像、埋め込みなど)において機能する統一的なドリフト測定値はありません。
(3) 特徴量のドリフトスコアは、特徴量間の相関を考慮するものではありません。
こうした問題に対応するため、9 月 10 日にVertex Model MonitoringにFeature Attuributionsを監視する新しい機能が追加されました。Feature distribution の監視とは対照的に、学習時(または他のベースライン)と比較して有意なドリフトを報告するために、サービス中に各特徴の予測への貢献度(すなわち、アトリビューション)を監視することがおもな考え方です。これには、以下の注目すべき利点があります。
ドリフトスコアは予測に及ぼす影響に対応します。特徴量のアトリビューションが大きく変化することは、特徴量の予測への貢献度が変化することを意味します。特徴量の貢献度の合計が予測に等しいため、通常、大きなアトリビューションのドリフトは、モデルの予測が大きくドリフトする指標となります。(しかし、特徴間のアトリビューションのドリフトが相殺され、予測ドリフトが無視できるほどになってしまうと、偽陽性になる可能性があります。偽陽性や偽陰性のさらなる議論は、Note#1 をご覧ください。)
特徴量表現の均質な解析。Feature Attributions は特徴量の種類によらず常に数値です。さらに、Feature Attributions の性質により、次元間のアトリビューションを合計することで、多次元の特徴量(例:エンベッディング)のアトリビューションも単一の数値へ集約できます。この特性により、すべての特徴量において標準的な単変量ドリフトを検知する手法が適用可能となります。
特徴量間の相互作用の考慮。アトリビューションは特徴量とその他の特徴量との相互作用による予測への貢献度を考慮します。したがって、特徴量の周辺分布が変化しなくても、相互作用する特徴量が変化すれば、feature attributions の分布は変化することがあります。
特徴量グループの監視。アトリビューションは付加的であるため、特徴量グループへのアトリビューションを得るために、関連する特徴量にアトリビューションを加えることができます。例えば、住宅の価格を予測するモデルでは、住宅の位置(街、学区など)に関する特徴量へのアトリビューションを組み合わせることができます。特徴量グループの変化を監視するために、グループレベルでのアトリビューションを追跡することができます。
モデル更新における重要度の追跡。モデルの再学習に伴うアトリビューションの監視は、関連する特徴量の重要度がモデルの更新に伴ってどう変化するのか理解するのに役立ちます。冒頭で述べた例では、特徴量F4とF6は再学習後に重要度が高まっていったことが分かりました。
特徴量重要度の監視を使う
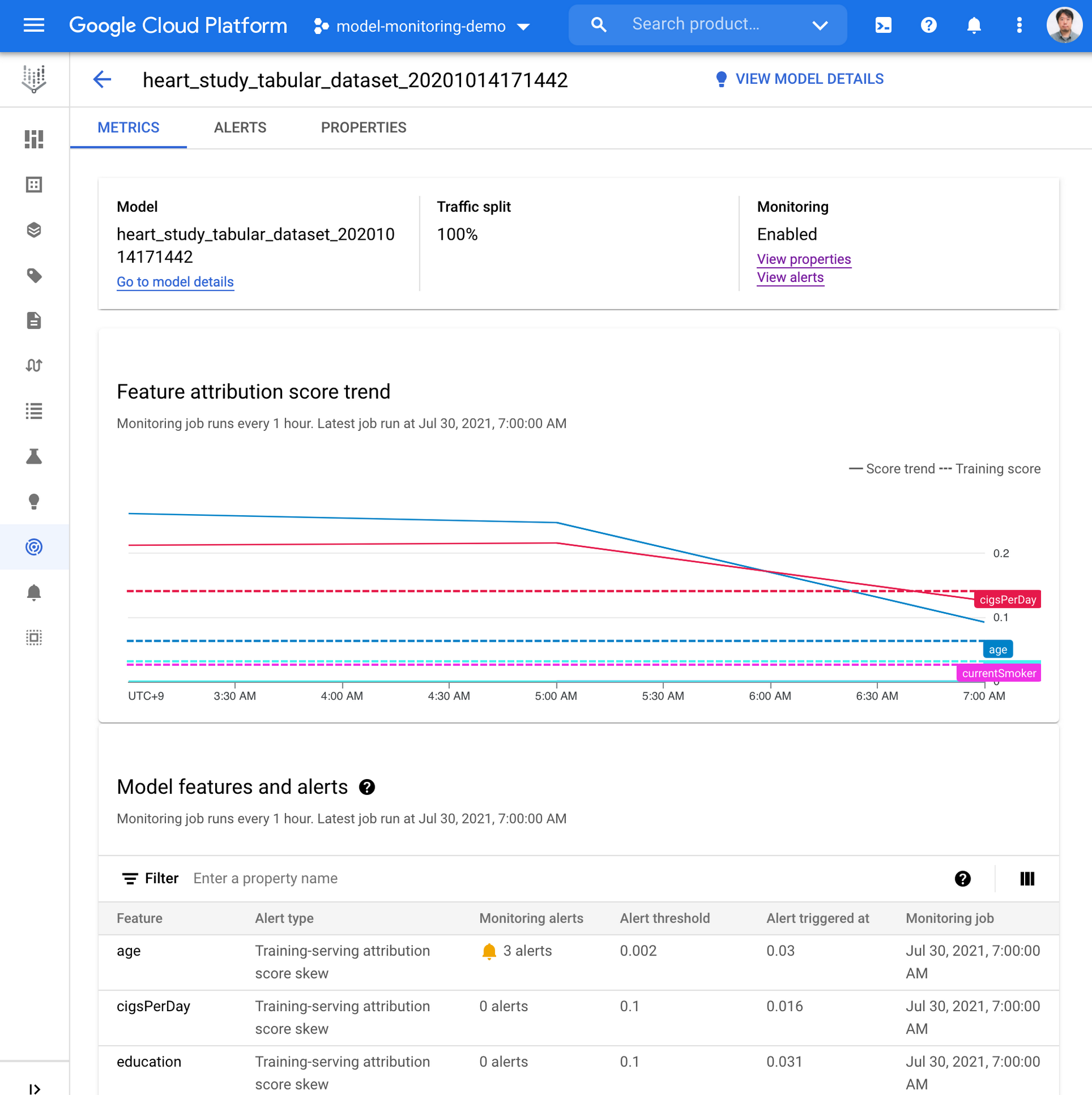
Vertex AI Prediction のエンドポイントが稼働している状況で、以下のような gcloud コマンドを実行し、Feature Distibution や Feature Attributions に対するスキューやドリフトを検知できます。これには、前処理や追加の設定は必要ありません。
ここで、キーとなるパラメータは以下の通りです:
email:監視アラートを送付する電子メールアドレス
Endpoint:監視する予測エンドポイント ID
prediction-sampling-rate:受信した予測要求のうち、監視目的でサンプリングする割合を制御するパラメータ
feature-thresholds:Feature Distribution を監視する入力特徴量と各特徴量に対するアラート閾値を指定
feature-attribution-thresholds:Feature Attribution を監視する入力特徴量と各特徴量に対するアラート閾値を指定
新しいエンドポイントを作成する際に、以下のようにモニターを設定するコンソールUIを使用することもできます。
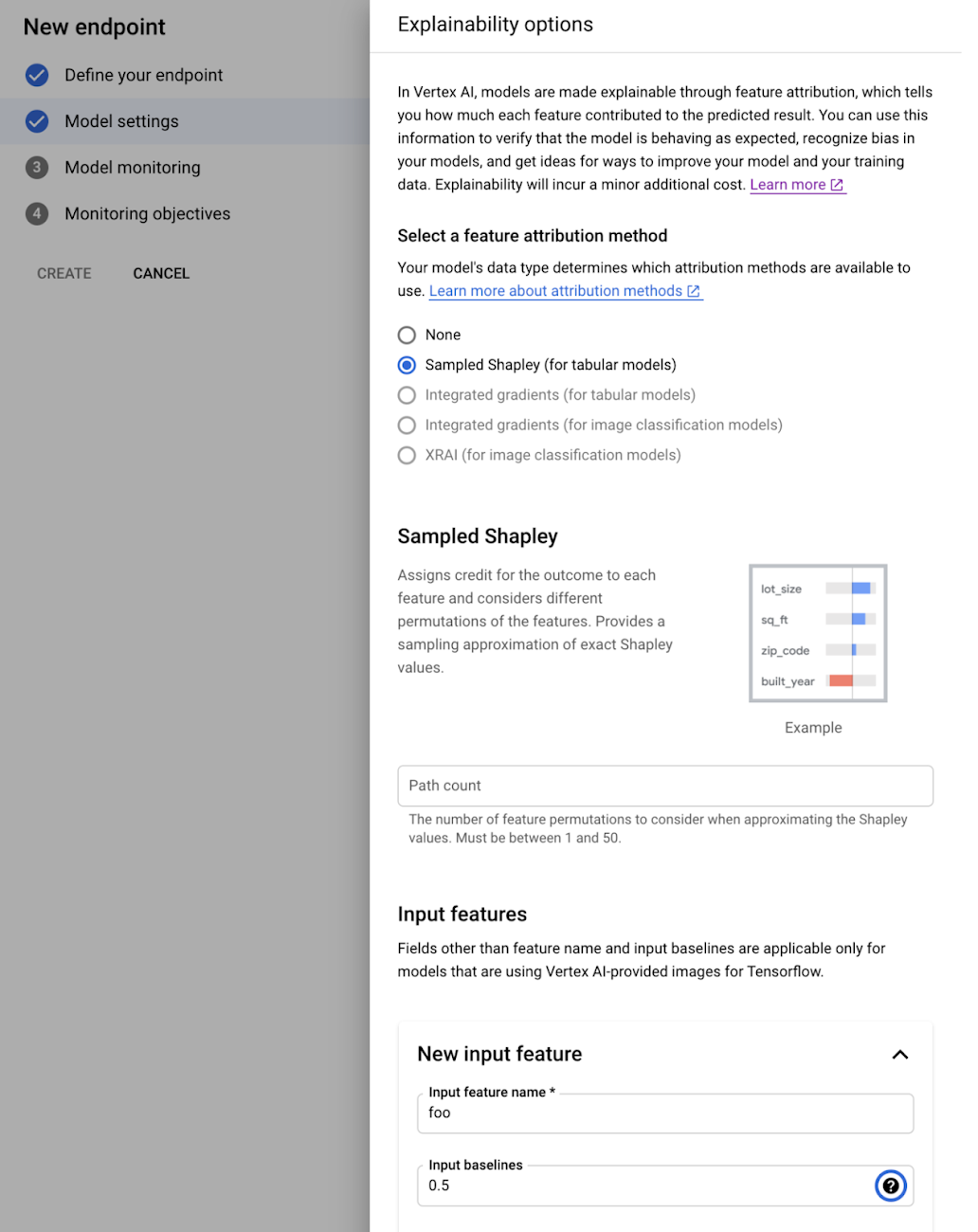
モニターを設定する詳細な方法については、こちらのドキュメントを参照ください。
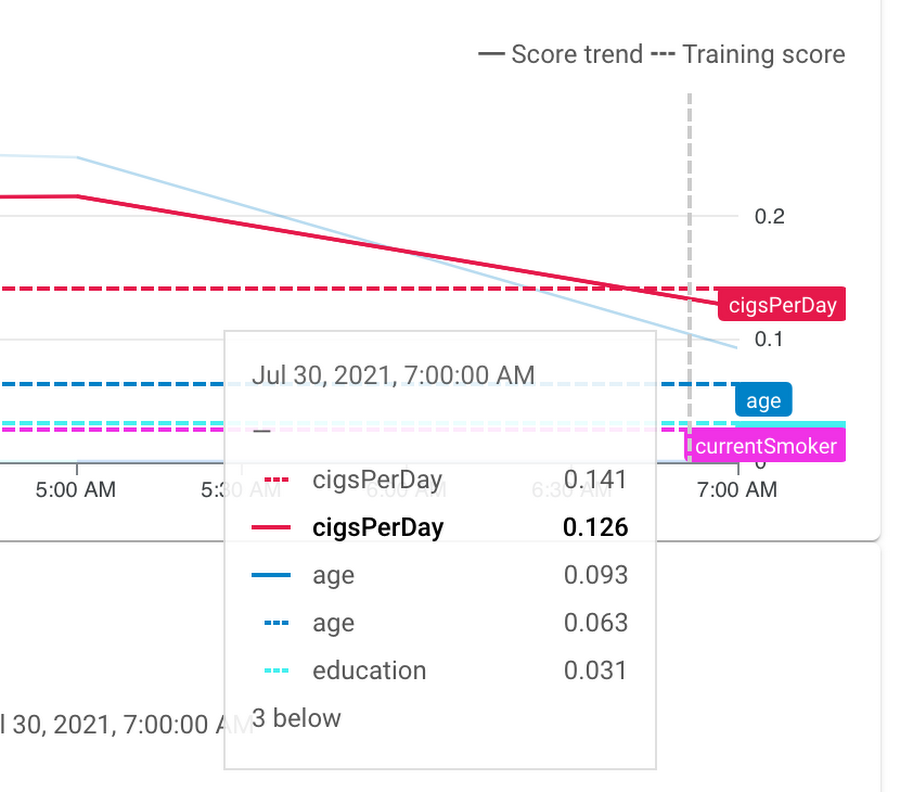
サービスを有効にした後、feature attribution のスキューやドリフトが検知されたら、コンソール上で以下のようなアラートが表示されます。同様に、監視アラートの email を受け取ります。これによって、運用者は適切な是正措置を講じることができます。

監視設定の考慮点
最後に、feature attribution の監視の設計に関わる2つの重要な技術的な考慮事項をみていきます。
アトリビューションのための予測クラスの選択。分類モデルの場合、feature attributions は入力と予測クラスに依存します。入力分布を監視する際、アトリビューションを計算するためにはどの予測クラスを使うべきでしょうか。この答えとしては、入力に対して予測を決定すると考えられるクラスをお勧めします。マルチクラスモデルの場合、通常、予測確率が最も大きいクラス(すなわち、”argmax”クラス)です。場合によっては、特定の主要なクラス(不正行為を予測モデルの場合、”不正行為”クラス)があり、そのスコアは下流のアプリケーションで考慮されます。その場合、アトリビューションには、常にその主要なクラスを使うのが合理的です。
Attribution分布の比較。attribution分布を比較する方法は、distribution divergence metrics (例えば、Jensen-Shannon divergence)や統計的検定(例えば、Kolmogorov-Smirnov 検定)といったものがいくつかあります。ここでは、比較的シンプルである分布の絶対値の平均を比較する手法を使います。この値は、各特徴量の貢献度を反映しています。アトリビューションは予測値の構成要素であるため、この値の差異は予測値の構成要素と解釈することができます。大きな差異は、予測に大きな影響を及ぼします。
次のステップ
Feature Attributions の監視を始めるにあたって、the Model Monitoring documentationから試してみてください。また、マーク・コーエンが作成したは優れた教材も利用できます。Vertex Model Monitoring とExplainable AI をベストプラクティスとして組み込むことで、ミッションクリティカルなビジネスやサービスを支援する、Googleスケールのプロダクション向けMLシステムを構築・運用する方法を体験し、学ぶことができるでしょう。
Note #1: Feature Attribution の監視が偽陽性と偽陰性を示す場合
Feature Attribution の監視は充実した手法です。しかし、注意すべきことがあります。以下に示すように、偽陽性や偽陰性を示す場合があります。したがって、本番環境に適用する場合、MLモデルの振る舞いをより良く理解するために、Feature Distribution の監視などと組み合わせて使うことをお勧めします。
[偽陰性]相互作用のないモデルでは、アトリビューションの単変量ドリフトは特徴量の多変量ドリフトを捉えられない場合があります。
例:線形モデルy = x1 +...+ xnを考えてみます。ここで、アトリビューションの単変量ドリフトは特徴量の単変量ドリフトに比例します。したがって、多変量ドリフトが起きているかに関わらず、特徴量の単変量ドリフトが小さいと、アトリビューションドリフトも小さくなります。
[偽陰性]アトリビューション空間では顕在化さないが、モデル性能に影響を与える特徴量のドリフト。
例:y = x1 XOR x2、モデルがy_hat = x1というタスクを考えてみます。学習時の分布を<1, 0>と<0, 0>、その出力分布を<1, 1>と<0, 1>としてみましょう。特徴量x2のアトリビューションは0(したがって、アトリビューションドリフトも0)ですが、x2のドリフトはモデル性能に大きく影響を及ぼします。
[偽陽性]重要な特徴量のドリフトは、常にモデル性能に影響を与えるわけではありません。
例:先程のXORの例で、出力分布は<1, 0>だけで構成されているとしましょう。入力特徴量x1が大きくドリフトしても、性能には影響を及ぼしません。
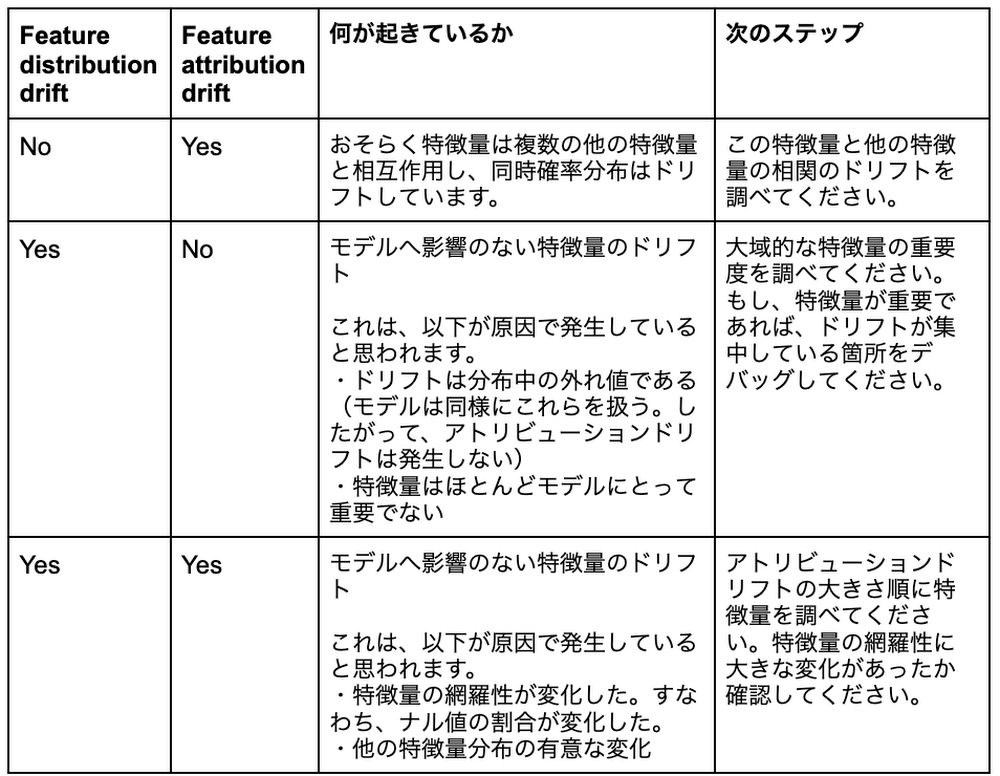
Note #2: Feature Distribution とFeature Attributionsの組み合わせ
Feature DistributionとFeature Attributions monitoringを組み合わせることで、何がどう変化することでモデルに影響を与えるのか、より深く理解できます。2つのモニタリング手法を組み合わせて得られた考察を元に、下記の表は複数の可能性を提示しています。
参考文献
Monitor models for training-serving skew with Vertex AI
- Ankur Taly, Research Scientist
- Kaz Sato, Developer Advocate, Google Cloud
- Claudiu Gruia, Software Engineer




