BigQuery Java クライアント ライブラリ: executeSelect を活用して SQL のパフォーマンスを向上させる

Google Cloud Japan Team
※この投稿は米国時間 2022 年 6 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
BigQuery Java クライアント ライブラリを利用すると、Java を使用した BigQuery API へのアクセスが容易になります。2016 年の提供開始以来、多数の機能と改善が Java クライアント ライブラリに追加され、BigQuery 開発者と実務担当者を支援してきました。最も注目すべき点は、最近、Java クライアント ライブラリに新しい Connection インターフェース が登場したことです。その背景には、SQL クエリを実行できるという BigQuery の主要機能のユーザビリティとパフォーマンスを向上させるという目的があります。この新しいインターフェースは、データベース アプリケーションの業界標準の方法で BigQuery Java クライアント API を定義します。
この新しいインターフェースで導入する最初のメソッドは「executeSelect」です。読み取り専用の SELECT クエリをサポートし、高スループットのワークロード(1 億行の読み取り)で 30 倍以上の速度のクエリ パフォーマンスを提供します。Google では、あらゆる SQL(DML、DDL、スクリプト)をサポートするために、今後「executeUpdate」と「execute」を導入する予定です。
このブログ投稿では、この新しいインターフェースの設計と実装について詳しく解説し、スムーズに利用を開始する方法について説明します
bigquery.query と比較して変わった点
従来の bigquery.query クライアント ライブラリ メソッドでは、BigQuery の jobs.getQueryResults API と jobs.query API(該当する場合)のみが使用されます。一方、新しい executeSelect メソッドでは、よりパフォーマンスの高い tabledata.list API と BigQuery Storage Read API が使用され、Apache Arrow を行のシリアル化形式として使用する高スループットのクエリを実現します。さらに、業界標準に則してクエリ結果を使用するための基礎となる java.sql.ResultSet オブジェクトを含む BigQueryResult を(TableResult の代わりに)返します。
クエリ実行のロジック
executeSelect を導入する以前は、bigquery.query は REST API エンドポイント(jobs.getQueryResults と jobs.query)のみを使用してクエリ結果を取得していました。新しい executeSelect メソッドがもたらした主な改善点の一つは、BigQuery Storage Read API との内部でのインテグレーションです。ライブラリは、結果サイズなどのヒューリスティックに基づいて、行を返すための最適なメカニズムを決定します。Storage Read API を使用するための前提条件が満たされている場合、テーブルからレコードのストリームを読み取るバックグラウンド スレッドを初期化します。BigQuery Java クライアント ライブラリは、行のシリアル化に Apache Arrow を使用し、列から行への変換を処理して、データを従来どおりに使用できるようにします。
それに加えて、BigQuery Storage Read API が使用されない場合、jobs.getQueryResults API ではなく tabledata.list API を使用します。これは tabledata.list API の方がより速くクエリ結果を取得できるためです。
戻り値の型
ユーザーがワークロードをより便利に移行できるように、BigQuery 様式の ResultSet オブジェクトを提供する BigQueryResult を返すことにしました。基盤となる ResultSet オブジェクトを使用すると、REST API と Read API の結果の処理(ページ分け、行のシリアル化など)についての実装の詳細を抽象化することもできます。ただし、ResultSet のすべてのメソッドが BigQuery に関連しているわけではありません。したがって、必要なメソッドは BigQueryResultImpl で実装され、無関係なメソッドは AbstractJdbcResultSet で処理されます。使用を可能にするうえで、すべてのデータ型アクセサーを実装しました。コードは JDBC 様式の構文に従っており、開発者のオンボーディング時間を短縮できます。以下で簡単に利用を始められる方法を見てみましょう。
executeSelect を使い始める方法
BigQuery Java クライアント ライブラリのバージョンを 2.12.0 以降にアップグレードすることで、executeSelect メソッドの利用を開始できます。
クライアント ライブラリのユーザーは、新しい Connection インターフェースに対してコーディングすることが想定されています。SQL ステートメントの実行によって返される結果には、Connection のコンテキストが含まれていません。したがって、最初に Connection オブジェクトを作成する必要があります。Java クライアント ライブラリはそれを使用して、クエリを実行して結果を取得する際に、jobs.query、jobs.getQueryResults、tabledata.list、または BigQuery Storage Read API のどちらを使用するか決定します。デフォルトでは、Read API が有効になっています。
Connection を作成する
Connection を特別な構成なしで作成するには:
executeSelect を使用したクエリ
SELECT のみのクエリを実行するには、前のステップで作成した Connection オブジェクトの executeSelect メソッドを呼び出すだけです。executeSelect はスレッドセーフではありませんのでご注意ください。JDBC 様式の BigQueryResult が返されます。
簡単なクエリを実行するには:
位置クエリ パラメータを使用したクエリの実行も簡単です。
クエリのドライランを行う
クエリの dryRun を実行するには、Connection オブジェクトで dryRun メソッドを呼び出すだけです。
BigQueryDryRunResult が返され、クエリ処理統計(スキーマ、クエリ パラメータ、sessionInfo など)を取得するために使用できます。
クエリのドライランを行うには:
executeSelect を使用することで期待できるパフォーマンスの向上
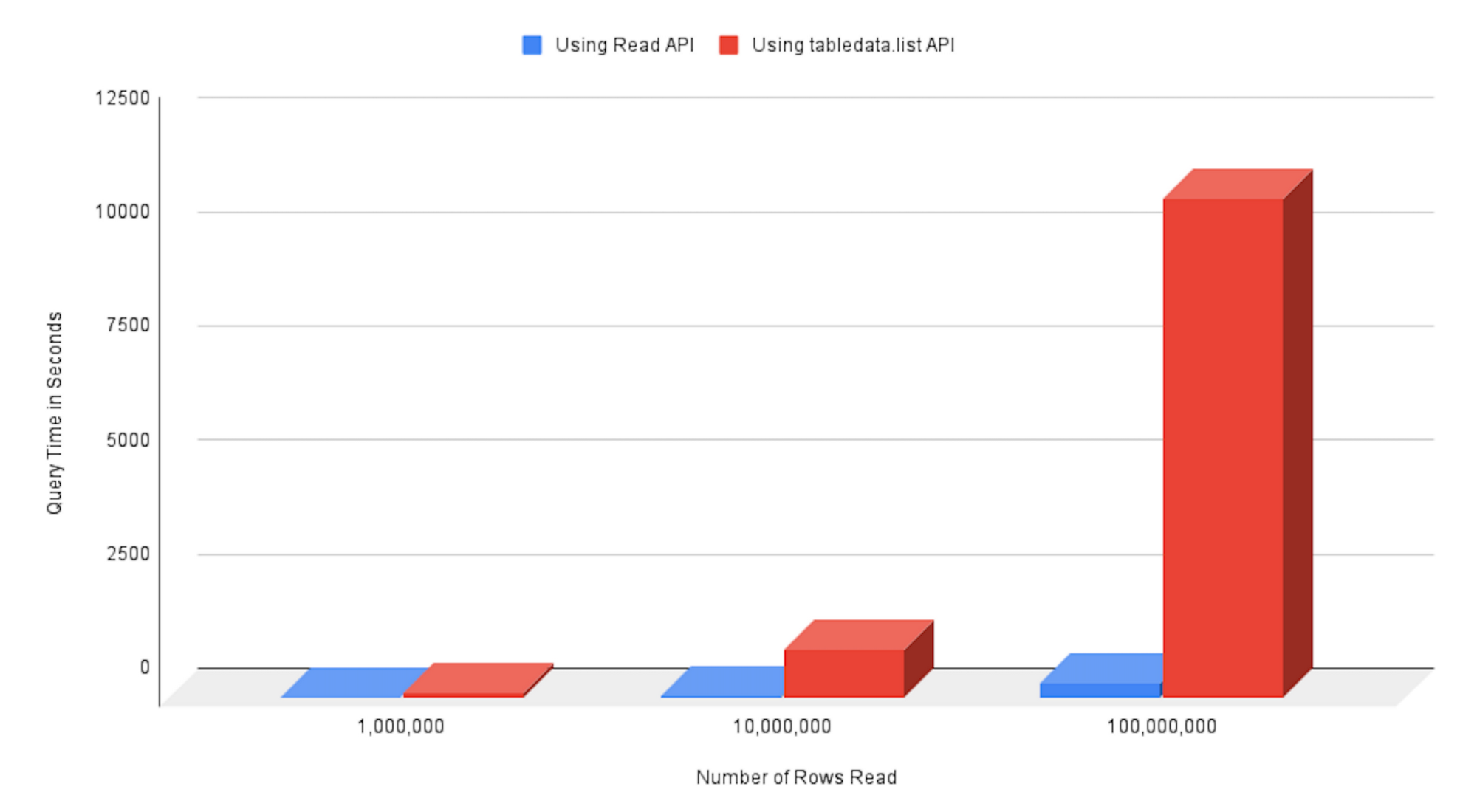
bigquery.query API と connection.executeSelect API のパフォーマンスを比較するベンチマークを実行しました。このベンチマークでは、bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2017 テーブルのレコードを読み取ります。connection.executeSelect API を使用した場合、最大 30 倍の速度のパフォーマンスが観察されました。
次のステップ
このフィードバック フォームに記入して、executeSelect を試してみた感想をお聞かせください。何か問題にお気づきの場合は、GitHub でご遠慮なく公開イシューを作成してください。フォームとイシューの両方を常にモニターしています。今後登場する executeUpdate と execute にもご期待ください。
ご精読ありがとうございました。
- シニア デベロッパーリレーションズ エンジニア Stephanie Wang
- シニア デベロッパー プログラム エンジニア Prashant Mishra



