BigQuery Java client library: Leverage executeSelect to get better SQL performance
Stephanie Wang
Senior Developer Relations Engineer
Prashant Mishra
Senior Developer Programs Engineer
Introduce executeSelect client library method and how to use it.
The BigQuery Java client library makes it easier to access BigQuery APIs using Java. Since its inception in 2016, numerous features and improvements have been added to the client library to enable BigQuery developers and practitioners. Most notably, a new Connection interface was recently introduced in the Java client library. It aims to improve the usability and performance of the main feature of BigQuery – its ability to run SQL queries. This new interface defines BigQuery Java client APIs in an industry standard way for database applications.
The first method we are introducing in this new interface is `executeSelect`. It supports read-only SELECT queries and provides more than 30x faster query performance on high throughput workloads (reading 100 million rows). We plan on introducing `executeUpdate` and `execute` later on to support any SQL (i.e. DML, DDL, and scripts).
In this blog post, we will delve into the design and implementation of this new interface and discuss how you can quickly get started with it
What has changed compared to bigquery.query?
The legacy bigquery.query client library method only uses BigQuery’s jobs.getQueryResults and jobs.query (when applicable) APIs. The new executeSelect method, on the other hand, also uses the more performant tabledata.list API and the BigQuery Storage Read API for high throughput queries which uses Apache Arrow as the row serialization format. In addition, we return BigQueryResult (instead of TableResult) which contains an underlying java.sql.ResultSet object for industry-standard consumption of query results.
Query execution logic
Prior to introducing executeSelect, bigquery.query only used REST API endpoints (jobs.getQueryResults and jobs.query) to retrieve query results. One major improvement that is introduced by the new executeSelect method is the integration with the BigQuery Storage Read API under-the-hood. The library determines the optimal mechanism for returning rows based on heuristics such as result size. If the prerequisite conditions for using the Storage Read API are met, then we initialize a background thread which reads a stream of records from the table. The BigQuery Java client library uses Apache Arrow for row serialization and takes care of the column to row translation so that data can be consumed conventionally.
Additionally, we are using tabledata.list API instead of jobs.getQueryResults API when the BigQuery Storage Read API is not used since tabledata.list API is faster in fetching query results.
Return type
We decided to return BigQueryResult which provides a BigQuery-esque ResultSet object for users to migrate their workload more conveniently. The underlying ResultSet object also allows us to abstract away the implementation details on REST API and Read API result handling (pagination, row serialization, etc.). However, not all methods in ResultSet are relevant to BigQuery. Therefore, the methods that are necessary are implemented in BigQueryResultImpl and the methods that are irrelevant are handled in AbstractJdbcResultSet. We implemented all the data type accessors to enable usage. The code follows a JDBC-esque syntax which should reduce the onboarding time for developers. Let’s take a look at how you can get started quickly below.
How can you get started with executeSelect?
You can start using the executeSelect method by upgrading your BigQuery Java client library version to 2.12.0 and above.
We expect client library users to code against the new Connection interface. SQL statements are executed and results are returned without the context of a Connection. Therefore, the first thing to do is to create a Connection object and the Java client library will use it to determine whether to use jobs.query, jobs.getQueryResults, tabledata.list, or the BigQuery Storage Read API to execute the query and fetch query results. By default, the Read API is enabled.
Create a Connection
To create a Connection without any special configuration:
Query with executeSelect
To execute a SELECT-only query, we simply call the executeSelect method on the Connection object we created in the previous step. Note that executeSelect is not thread-safe. A JDBC-style BigQueryResult is returned.
To execute a simple query:
You can also easily execute a query with positional query parameters:
Run a query dry run
To execute a query dryRun, simply call the dryRun method on the Connection object.
A BigQueryDryRunResult is returned and can be used to retrieve query processing statistics such as schema, query parameters, sessionInfo, and so on.
To execute a query dry run:
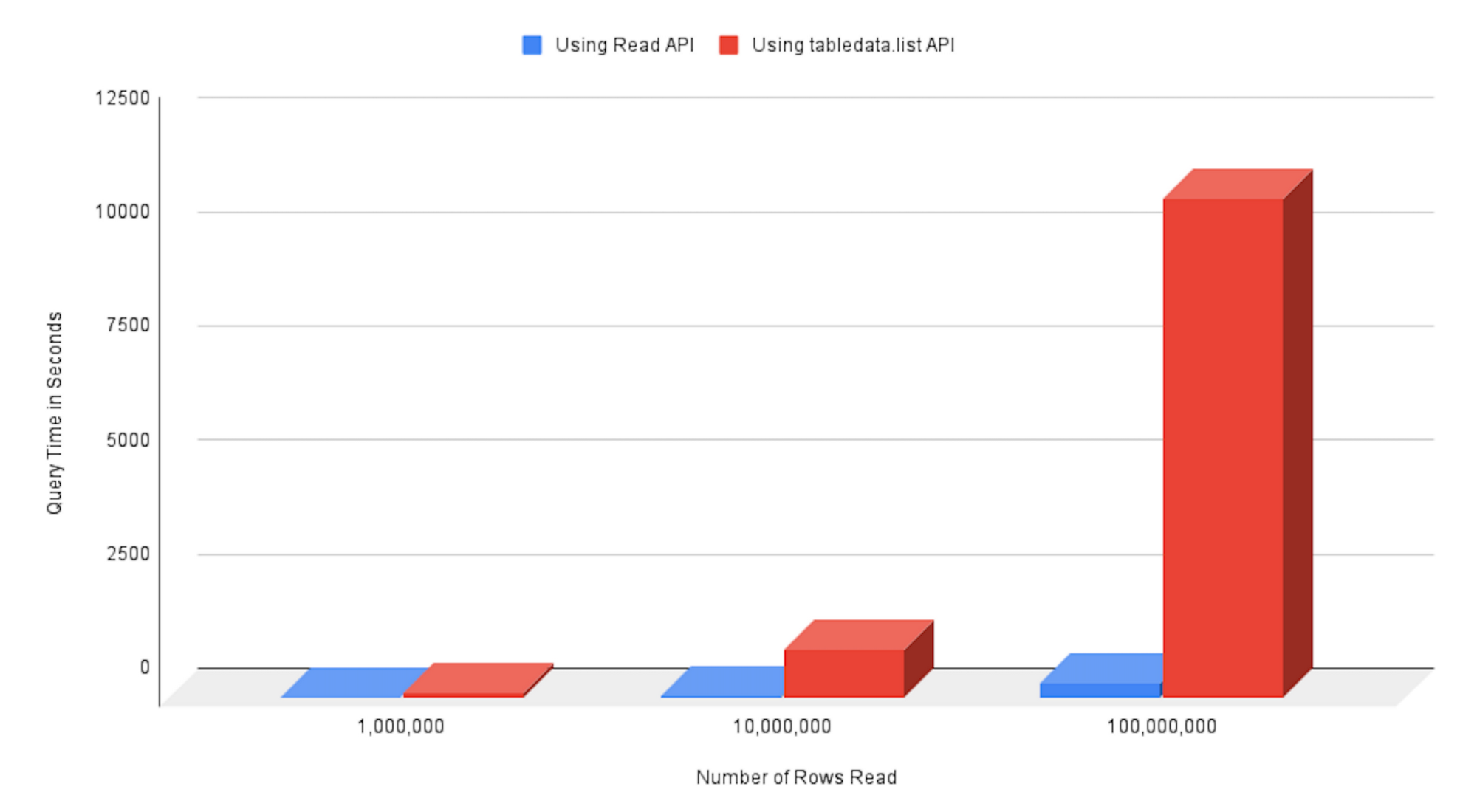
What performance improvement can you expect with executeSelect?
We ran a benchmark which compares the performance of bigquery.query API and connection.executeSelect API. The benchmark reads records in the bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2017 table. We observed up to a 30x faster performance when using the connection.executeSelect API:
What’s Next?
Let us know what you think when you try out executeSelect by filling out this feedback form. If you notice any issues, please don’t hesitate to create public issues on Github. We monitor both the form and the issues actively. Otherwise, please stay tuned for executeUpdate and execute next.
Thank you for reading!



