オンプレミス データ ウェアハウスを Google Cloud 上の BigQuery へ移行する方法

Google Cloud Japan Team
※この投稿は米国時間 2021 年 12 月 17 日に、Google Cloud blog に投稿されたものの抄訳です。
企業のデータ チームは、データの結合、処理、そしてデータの有効活用に苦慮しています。データ チームは、複数の ETL ジョブの混在、ETL 処理時間が長く、容量が制限されたオンプレミス データ ウェアハウス、ユーザーからの増え続ける要求などといった課題に対応しなくてはなりません。データ処理が、機械学習(ML)、レポート、分析という下流の要件を満たすようにすることも必要です。さらに、もっと多くのデータにどのように対応するか、新しい下流チームをどのようにサポートするかなど、今後についても計画する必要があります。
Independence Health Group におけるエンタープライズ データ ウェアハウス(EDW)の移行の取り組みを、上の動画でご覧ください。
BigQuery を選択する理由
スケーリングが難しいオンプレミス データ ウェアハウスを抱える多くの企業にとって、安全性とスケーラビリティが高く、費用対効果に優れた未来志向のシステムを作ることが最大目標となっています。GCP の BigQuery はサーバーレスでスケーラビリティが非常に高く費用対効果に優れており、EDW のユースケースに大きな技術的適合性があります。BigQuery は、ビジネスのアジリティを実現するために設計された、マルチクラウドのデータ ウェアハウスです。しかし、高度に統合された大規模なデータ ウェアハウスをオンプレミスから BigQuery に移行することは、スイッチを切り替えるように簡単にできるものではありません。データセットの移行では、移行中および移行後の結果が整合しないと下流のシステムに影響が出る、という点に注意する必要があります。そのためには、計画的な移行が不可欠です。
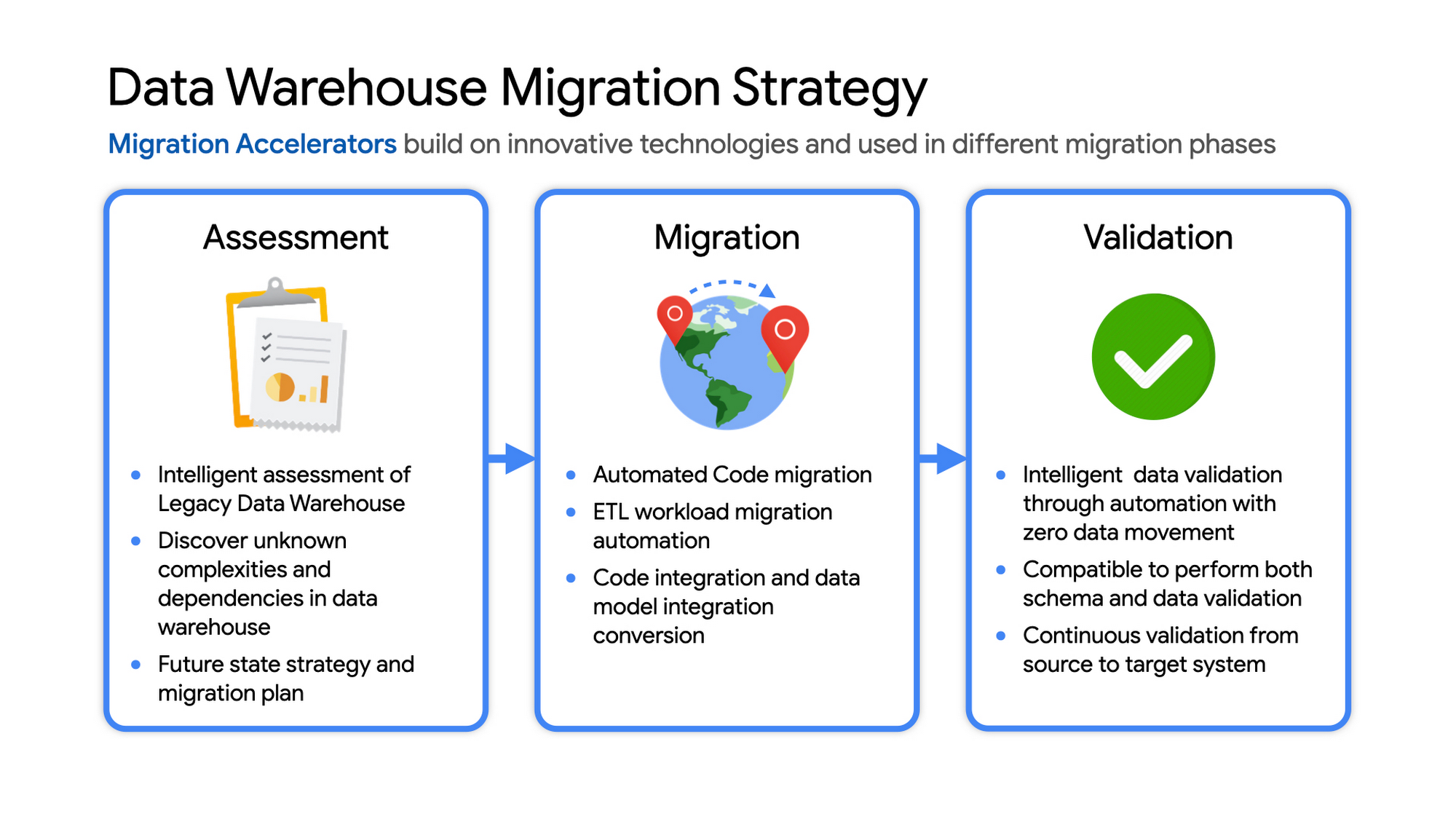
データ ウェアハウスの移行戦略
移行を成功させるための一般的な手順は次のとおりです。
評価と計画: レガシー(従来型)データ ウェアハウスにおける移行計画の対象を事前に特定する
データ グループ、アプリケーションのアクセス パターンおよびキャパシティを特定する
ツールとユーティリティを使用して、把握していない複雑性と依存関係を特定する
必要なアプリケーションのコンバージョンとテストを特定する
予算の予測とキャパシティ プランニングのために、初期処理能力とストレージ容量を特定する
移行期間中に予想される成長と変更を検討する
設計の基盤となる、戦略とビジョンの将来像を作成する
移行: GCP での基盤を作り、移行を開始する
クラウドの基盤を設定しながら、データ移行プロセスとタイムラインを検証するための集中的な概念実証の実施を検討する
必要なコードの移行に役立つ、自動化されたユーティリティを探す
レガシー EDW とターゲット EDW 間における移行期間中のデータ同期を維持するための計画の作成。これは、プロジェクトをスケジュールに従って行うための、必須のビジネス プロセスとなります。
既存のチームが両方の環境で業務を行えるように、一部のエンタープライズ ツールの統合を計画する
EDW ユーザー コミュニティにおける現在のデータ アクセス パターン、およびこれらが Big Query で利用可能な同種のコントロールにどのようにマッピングされるかを検討する
主要なスコープにはコードの統合とデータモデルのコンバージョンが含まれる
キャパシティ予測と割り当て設計の精緻化を図る。BigQuery には、コストとパフォーマンスのバランスを図り、ビジネス価値を最大化するためのオプションが数多くあります。たとえば、オンデマンド料金または定額料金のいずれか、または両方を組み合わせた料金プランを選択できます。
検証とテスト
自動化された、インテリジェントなデータ検証を実現するツールを探す
スコープは、スキーマとデータ検証の両方を含むことが必要
可能であれば、ソース システムからターゲット システムへの移行中に継続的に検証を行うソリューションを使用する
テストの複雑性と期間は、レガシー EDW のデータを消費するアプリケーションの数と複雑性、およびこれらのアプリケーションの変化率によって決定される
移行成功の鍵は、EDW ワークロードの移行経験を有する Google Cloud パートナーを見つけることです。たとえば、Google Cloud パートナーである Datametica は、移行を効率的に計画および実行できるよう、サービスと特化型移行アクセラレータをそれぞれの移行段階で提供しています。
データ ウェアハウスの移行: 注意点
オープンソースの財政的メリット: ターゲットは、すべてのサービスにライセンス料がかからない「オープンソース」に移行されます。たとえば、BigQuery は標準 SQL を使用しています。Cloud Composer は、マネージド Apache Airflow であり、Dataflow は Apache Beam を基盤としています。これらをマネージド サービスとして使用することにより、オープンソースの財政的メリットが得られると同時に、オープンソース プラットフォームの社内メンテナンスの負荷を回避できます。
サーバーレス: 「サーバーレス」なビッグデータ サービスに移行します。推奨される GCP データ アーキテクチャで使用されるサービスの大半は、ニーズに合わせてオンデマンドでスケーリングし、費用対効果をさらに高めてくれます。フルマネージド サービスを使用することで、エンジニアリングの時間を、インフラストラクチャの構築や維持ではなく、ビジネス ロードマップの優先事項に集中させることができます。
統合プラットフォームの効率: どのようなデータ ウェアハウス移行でも、データの取り込み、事前処理、およびビジネス価値を最大化するために EDW に保存されたデータに対して高度な分析を行う EDW 関連サービスとの統合が必要です。GCP のようなクラウドのプロバイダは、組み込みの機械学習を使用した、全方向に対応する統合およびマネージド「ビッグデータ」サービスを提供しています。これにより、EDW に固有のポイントソリューションと比較して、運用効率性とコスト効率性の両方が向上し、長期的なTCOを大幅に削減することができます。
強固なクラウド基盤の構築: 開始段階から、後続のワークロードにおけるビジネス面および技術面のニーズに対応できる、安全な基盤の設計に時間をかけましょう。主要な機能には、スケーラビリティの高いリソース階層、多層セキュリティ、複層的なネットワークおよびデータ センター戦略、そして Infrastructure as Code(IaC)を使用した自動化が含まれます。クラウドベースのサービスを既存のエンタープライズ システムに統合する時間も確保してください(CI / CD パイプライン、モニタリング、アラート、ロギング、処理スケジュール、サービス リクエストの管理など)。
無制限の拡張キャパシティ: クラウドへの移行はとても大きなステップのように思われますが、実際はチームがアクセスできるデータセンターを追加するようなものです。当然のことながら、これらのデータセンターは、社内開発が非常に困難な新しいサービスを数多く提供します。また、最小限の初期費用で、ほぼ無制限の拡張キャパシティも提供します。
忍耐と暫定プラットフォーム: EDW の移行は、一般的には長期にわたるプロジェクトです。データの同期、検証、アプリケーションのテストのために、暫定プラットフォームの設計と運用の準備をする必要があります。上流システムと下流システムへの影響を検討します。これらのシステムを EDW 移行に合わせて移行およびモダナイズすることは、非常に有益です。これらのシステムがデータソースやシンクとなる可能性、そして同様の拡大という問題を抱えている可能性があるためです。移行中に発生する新しいビジネス要件に対応する準備もします。長期間であることを利用して、既存の運用チームが、デプロイを主導しているパートナーから新しいサービスを学べるようにします。これにより、移行後のチームへの引き継ぎがスムーズになります。
経験豊富なパートナー: EDW 移行は、移行中に課題とリスクをともなう大きな取り組みです。しかし同時に、社内外の EDW ユーザーに、コスト削減、業務の簡素化、大幅なキャパシティ改善をもたらす大きな機会でもあります。適切なパートナーを選択することで、技術面および財政面でのリスクを削減できます。また、長期的メリットを移行プロセスの早期段階で計画して、場合によっては活用開始できます。
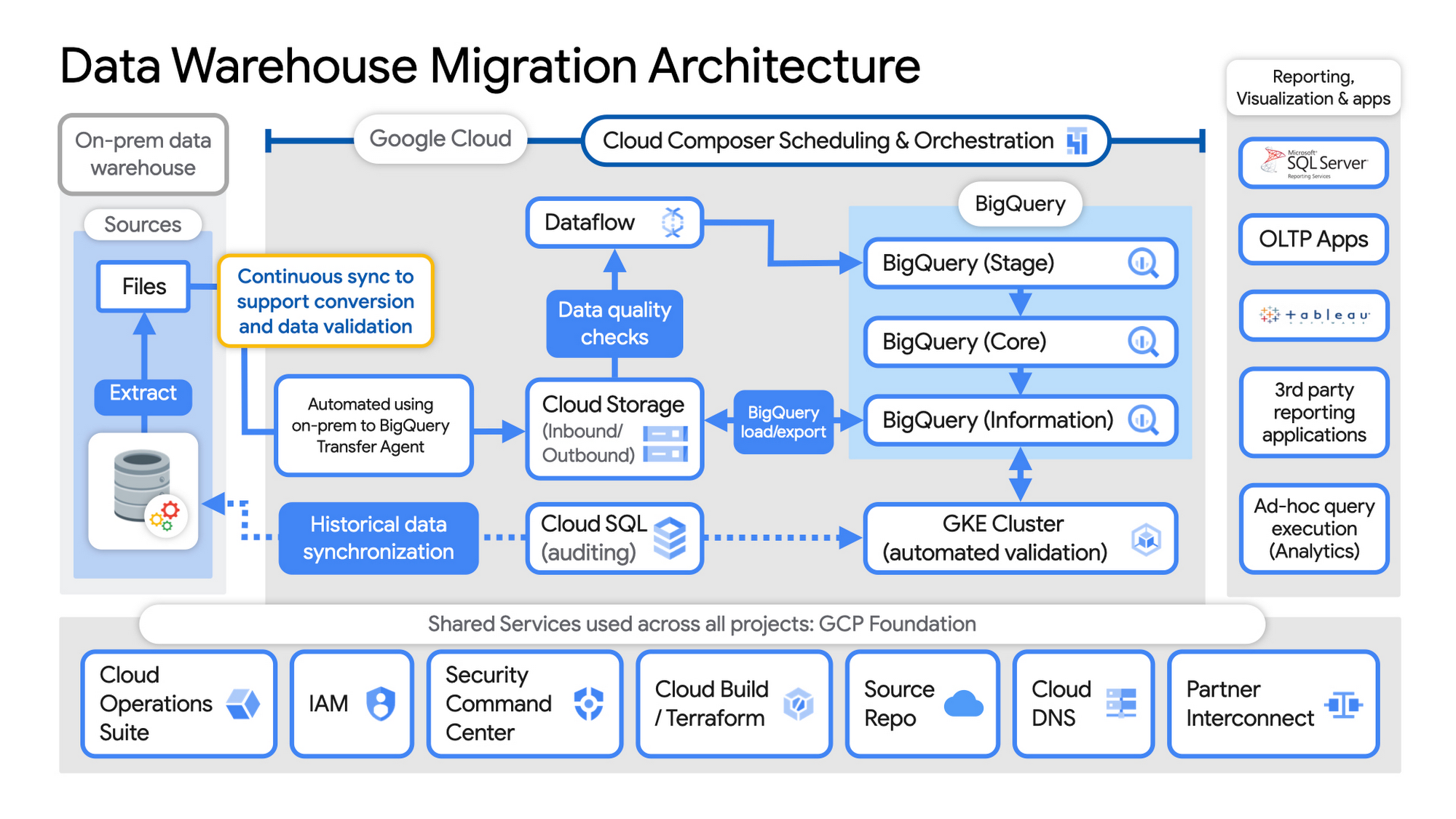
データ ウェアハウス移行アーキテクチャの例
基本的な要素を設定します。GCP では、基本的な要素には、認証およびアクセス用 IAM、クラウドリソース階層、課金、ネットワーキング、コード パイプライン、Cloud Build と Terraform(GCP Foundation Toolkit)を併用した Infrastructure as Code、Cloud DNS、および現在のデータセンターを接続する Dedicated Interconnect / Partner Interconnect が含まれます。
実際のユーザーデータを読み込む前に、モニタリングおよびセキュリティ スキャンサービスを有効にします。この際、Cloud Operations を使用してモニタリングとロギングを行い、Security Command Center を使用してセキュリティ モニタリングを行います。
オンプレミスのレガシー EDW からファイルを抽出して Cloud Storage に移動し、 BigQuery Transfer Service を使用して、継続的な同期を設定します。
Cloud Storage から、Dataflow でデータを処理し、BigQuery へのデータの読み込み / エクスポートを行います。
Datametica の検証ユーティリティを使用してエクスポートを検証します。これは GKE クラスタと Cloud SQL で動作し、監査と過去のデータの同期を必要に応じて実行します。アプリケーション チームは、移行プロセス全体を通じて検証されたデータをテストします。
Cloud Composer を使用してパイプライン全体をオーケストレートします。これは、オンプレミスのスケジュール サービスと必要に応じて統合され、確立されたプロセスを利用し、従来のシステムと新しいシステムの同期を維持します。
新しいデータを EDW に取り込むチーム / サービスと、進行中の高度な分析に EDW データを使用する下流の分析チームの綿密な調整を維持します。
データセットへのきめ細かなアクセス制御を確立します。BigQuery データコネクタを使用して、「下流」のユーザーのアクセスとテスト用に BigQuery のデータを既存のレポート、可視化ツール、アプリケーション消費ツールで利用できるようにします。
BigQuery フラットレート処理キャパシティを徐々に増加させ、移行中にリソースを最大の費用対効果で使用できるようにします。
オンプレミスのエンタープライズ データ ウェアハウス(EDW)からの BigQuery および GCP への移行に関する詳細は、こちらをご覧ください。
- Google デベロッパー アドボケイト Priyanka Vergadia
- スペシャリスト カスタマー エンジニア Michael Ernesto



