How to migrate an on-premises data warehouse to BigQuery on Google Cloud

Priyanka Vergadia
Staff Developer Advocate, Google Cloud
Michael Ernesto
Specialist Customer Engineer
Data teams across companies have continuous challenges of consolidating data, processing it and making it useful. They deal with challenges such as a mixture of multiple ETL jobs, long ETL windows capacity-bound on-premise data warehouses and ever-increasing demands from users. They also need to make sure that the downstream requirements of ML, reporting and analytics are met with the data processing. And, they need to plan for the future - how will more data be handled and how new downstream teams will be supported?
Checkout how Independence Health Group is addressing their enterprise data warehouse (EDW) migration in the video above.
Why BigQuery?
On-premises data warehouses become difficult to scale so most companies' biggest goal is to create a forward looking system to store data that is secure, scalable and cost effective. GCP’s BigQuery is serverless, highly scalable, and cost-effective and is a great technical fit for the EDW use-case. It’s a multicloud data warehouse designed for business agility. But, migrating a large, highly-integrated data warehouse from on-premise to BigQuery is not a flip-a-switch kinda migration. You need to make sure your downstream systems dont break due to inconsistent results in migrating datasets, both during and after the migration. So..you have to plan your migration.
Data warehouse migration strategy
The following steps are typical for a successful migration:
Assessment and planning: Find the scope in advance to plan the migration of the legacy data warehouse
Identify data groupings, application access patterns and capacities
Use tools and utilities to identify unknown complexities and dependencies
Identify required application conversions and testing
Determine initial processing and storage capacity for budget forecasting and capacity planning
Consider growth and changes anticipated during the migration period
Develop a future state strategy and vision to guide design
Migration: Establish GCP foundation and begin migration
As the cloud foundation is being set up, consider running focused POCs to validate data migration processes and timelines
Look for automated utilities to help with any required code migration
Plan to maintain data synchronization between legacy and target EDW during the duration of the migration. This becomes a critical business process to keep the project on schedule.
Plan to integrate some enterprise tooling to help existing teams span both environments
Consider current data access patterns among EDW user communities and how they will map to similar controls available in Big Query.
Key scope includes code integration and data model conversions
Expect to refine capacity forecasts and refine allocation design. In Big Query there are many options to balance cost and performance to maximize business value. For example, you can use either on-demand or flat-rate slot pricing or a combination of both.
Validation and testing
Look for tools to allow automated, intelligent data validation
Scope must include both schema and data validation
Ideally solutions will allow continuous validation from source to target system during migration
Testing complexity and duration will be driven by number and complexity of applications consuming data from the EDW and rate of change of those applications
A key to successful migration is finding Google Cloud partners with experience migrating EDW workloads. For example, our Google Cloud partner Datametica offers services and specialized Migration Accelerators for each of these migration stages to make it more efficient to plan and execute migrations.
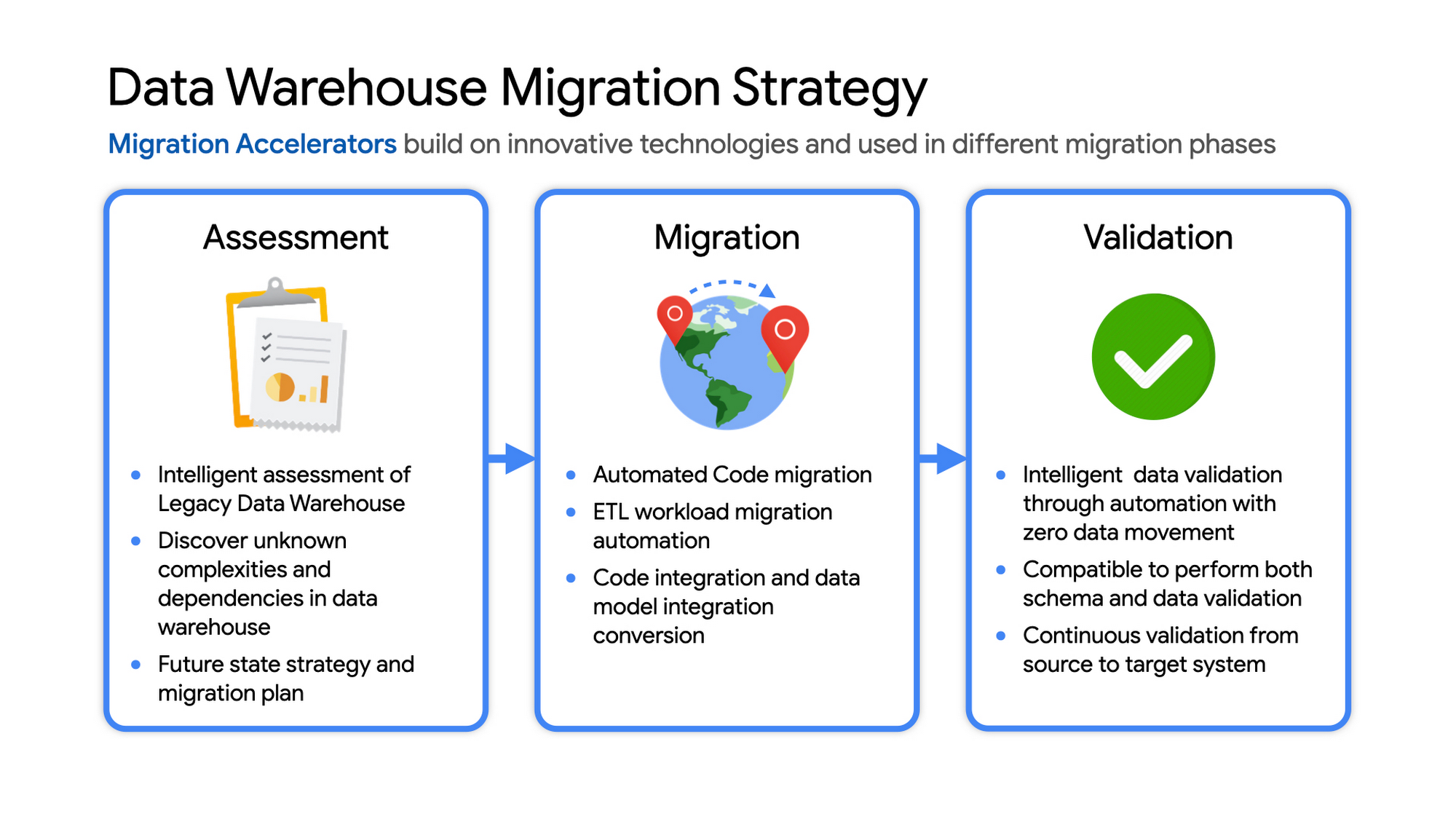
Data warehouse migration: Things to consider
Financial benefits of open source: Target moving to ‘Open Source' where none of the services have license fees. For example BigQuery uses Standard SQL; Cloud Composer is managed Apache Airflow, Dataflow is based on Apache Beam. Taking these as managed services provides the financial benefits of open source, but avoids the burden of maintaining open source platforms internally.
Serverless: Move to “serverless” big data services. The majority of the services used in a recommended GCP data architecture scale on demand allowing more cost effective alignment with needs. Using fully managed services lets you focus engineering time on business roadmap priorities, not building and maintaining infrastructure.
Efficiencies of a Unified platform: Any data warehouse migration involves integration with services that surround the EDW for data ingest and pre-processing and advanced analytics on the data stored in the EDW to maximize business value. A cloud provider like GCP offers a full breadth of integrated and managed ‘big data’ services with built-in machine learning. This can yield significantly reduced long-term TCO by increasing both operational and cost efficiency when compared to EDW-specific point solutions.
Establishing a solid cloud foundation: From the beginning, take the time to design a secure foundation that will serve the business and technical needs for workloads to follow. Key features include: Scalable Resource Hierarchy, Multi-layer security, multi-tiered network and data center strategy and automation using Infrastructure-as-Code. Also allow time to integrate cloud-based services into existing enterprise systems such as CI/CD pipelines, monitoring, alerting, logging, process scheduling, and service request management.
Unlimited expansion capacity: Moving to cloud sounds like a major step, but really look at this as adding more data centers accessible to your teams. Of course, these data centers offer many new services that are very difficult to develop in-house and provide nearly unlimited expansion capacity with minimal up-front financial commitment. .
Patience and interim platforms: Migrating an EDW is typically a long running project. Be ready to design and operate interim platforms for data synchronization, validation and application testing. Consider the impact on up-stream and down-stream systems. It might make sense to migrate and modernize these systems concurrent with the EDW migration since they are probably data sources and sinks and may be facing similar growth challenges. Also be ready to accommodate new business requirements that develop during the migration. Take advantage of the long duration to have existing your operational teams learn new services from the partner leading the deployment so your teams are ready to take over post-migration.
Experienced partner: An EDW migration can be a major undertaking with challenges and risks during migration, but offers tremendous opportunities to reduce costs, simplify operations and offer dramatically improved capacities to internal and external EDW users. Selecting the right partner reduces the technical and financial risks, and allows you to plan for and possibly start leveraging these long-term benefits early in the migration process.
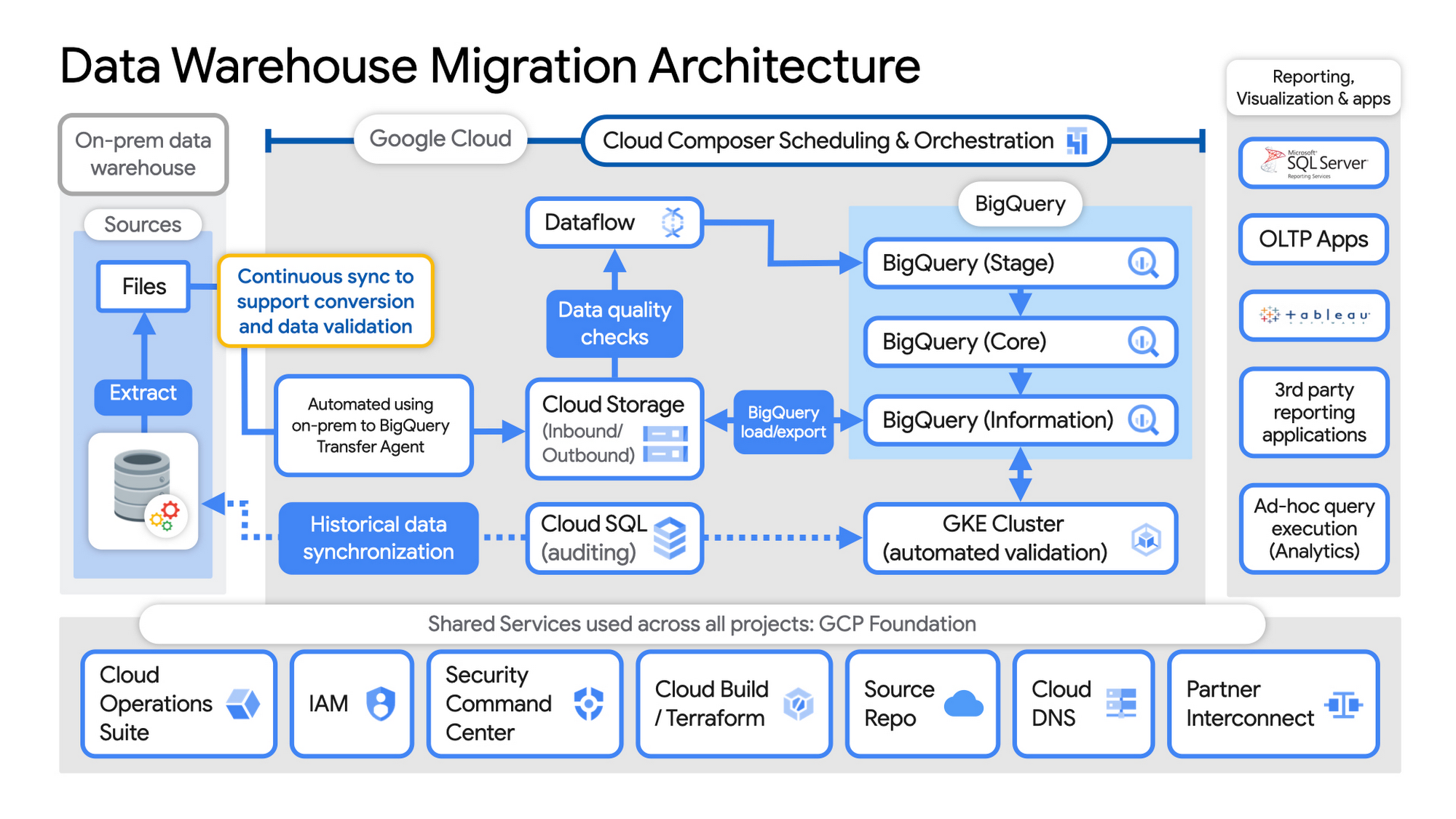
Example Data Warehouse Migration Architecture
Setup foundational elements. In GCP these include, IAM for authorization and access, cloud resource hierarchy, billing, networking, code pipelines, Infrastructure as Code using Cloud Build with Terraform ( GCP Foundation Toolkit), Cloud DNS and a dedicated/partner Interconnect to connect to the current data centers.
Activate monitoring and security scanning services before real user data is loaded using Cloud Operations for monitoring and logging and Security Command Center for security monitoring.
Extract files from on-premise legacy EDW and move to Cloud Storage and establish on-going synchronization using Big Query Transfer services.
From Cloud Storage, process the data in Dataflow and Load/Export data to BigQuery.
Validate the export using Datametica’s validation utilities running in a GKE cluster and Cloud SQL for auditing and historical data synchronization as needed. Application teams test against the validated data sets throughout the migration process.
Orchestrate the entire pipeline using Cloud Composer, integrated with on-prem scheduling services as needed to leverage established processes and keep legacy and new systems in sync.
Maintain close coordination with teams/services ingesting new data into the EDW and down-streams analytics teams relying on the EDW data for on-going advanced analytics.
Establish fine-grained access controls to data sets and start making the data in Big Query available to existing reporting, visualization and application consumption tools using BigQuery data connectors for ‘down-stream’ user access and testing.
Incrementally increase Big Query flat-rate processing capacity to provide the most cost-effective utilization of resources during migration.
To learn more about migrating from on-premises Enterprise Data Warehouses (EDW) to Bigquery and GCP here.




