Cloud Bigtable の規模
Google Cloud Japan Team
※この投稿は米国時間 2021 年 6 月 9 日に、Google Cloud blog に投稿されたものの抄訳です。
「低レイテンシと高スループットを必要とするアプリケーションを構築している場合」- 大量の読み取りと書き込みに対応できるデータベースが必要です。Cloud Bigtable は、まさにこの処理を前提として設計されています。
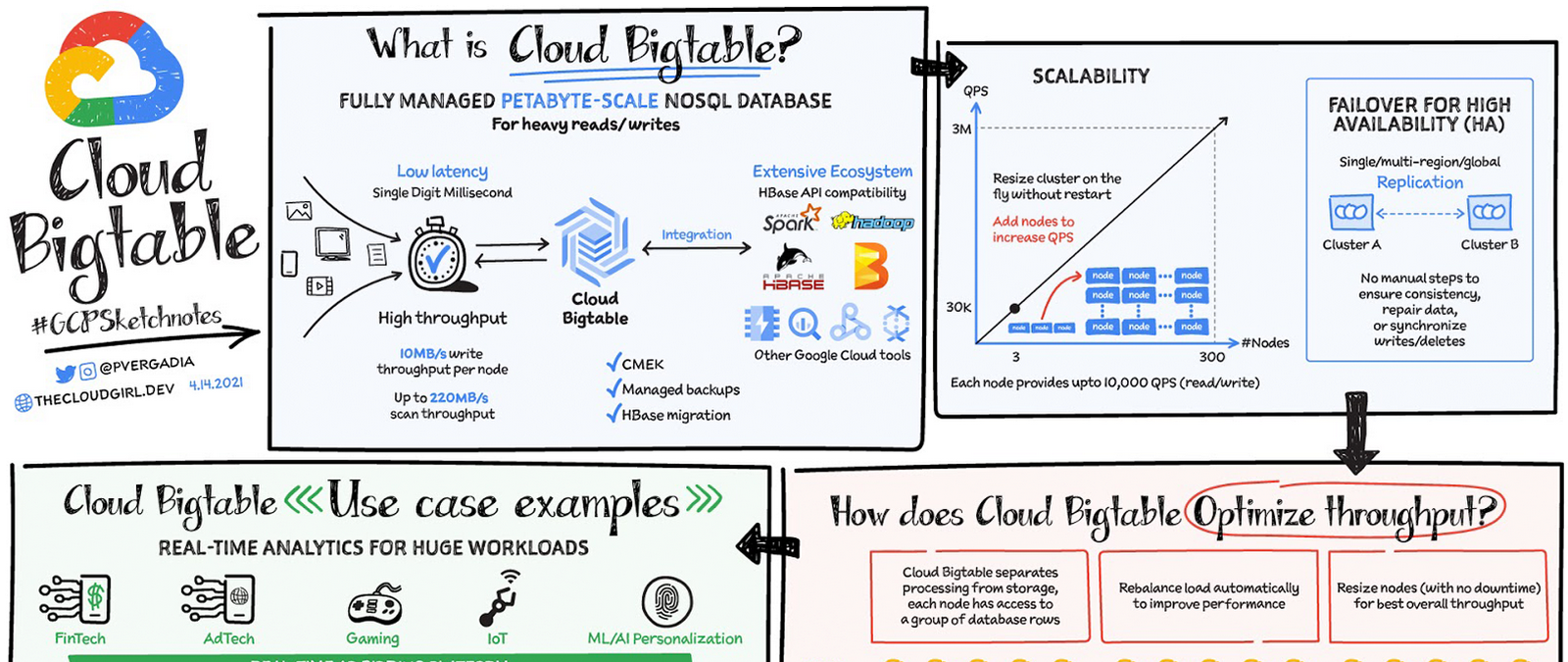
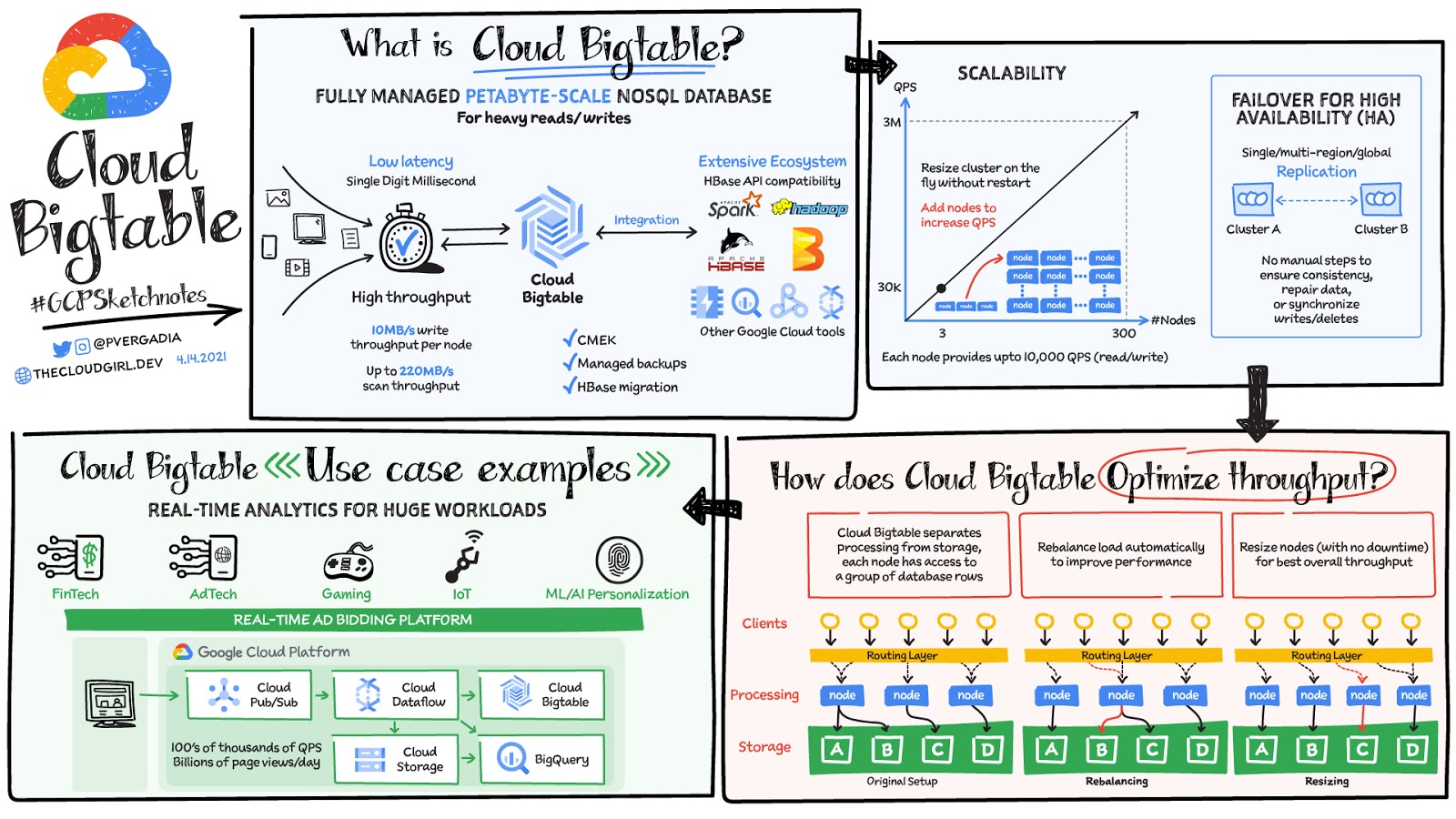
Cloud Bigtable はフルマネージド、ワイドカラム型 NoSQL データベースで、ペタバイト規模まで対応可能です。低レイテンシ、大量の読み取りと書き込み、大規模でのパフォーマンスの維持に向けて最適化されています。数ミリ秒単位の超低レイテンシを実現します。時系列のオペレーションや MapReduce スタイルのオペレーションに最適なデータソースです。Bigtable はオープンソースの HBase API 規格をサポートしているため、HBase、Beam、Hadoop、Spark などの Apache エコシステムと簡単に統合できます。また、Memorystore、BigQuery、Dataproc、Dataflow などの Google Cloud エコシステムとの統合も可能です。
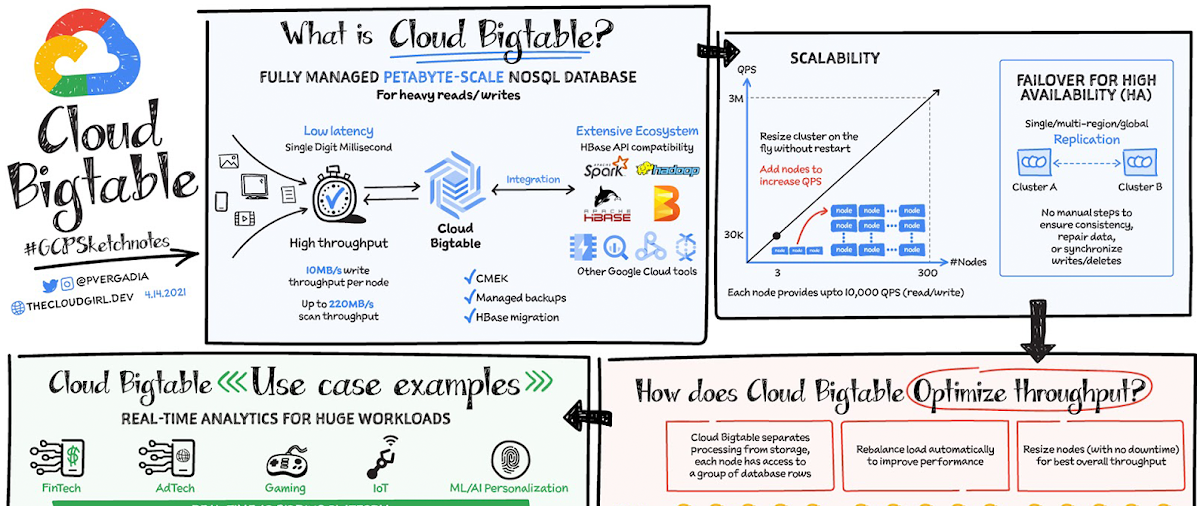
Cloud Bigtable の特長
データは Google が管理する暗号鍵を使ってデフォルトで暗号化されます。ただし、特定のコンプライアンス要件や規制要件において、お客様が独自の鍵を管理する必要がある場合は、顧客管理の暗号鍵(CMEK)も使用できます。
Bigtable バックアップを使用すると、テーブルのスキーマとデータのコピーを保存しておき、後でバックアップから新しいテーブルに復元できます。バックアップは、アプリケーション レベルのデータ破損や、テーブルを誤って削除するなどオペレーターのエラーから回復させる場合に役立ちます。
スケーラビリティと高可用性(HA)
Bigtable の規模について言うと、Bigtable では全体で 10 エクサバイトに近いデータを管理しています。
Bigtable は、予測可能性の高いパフォーマンスを実現し、線形的にスケールできます。スループットはノードの追加や削除によって調整します。1 つのノードで、最大 1 秒間に 10,000 件のオペレーションまで対応できます(読み取りと書き込み)。Bigtable は、大容量の低レイテンシ アプリケーションに加え、スループット重視型のデータ処理や解析ツールのストレージ エンジンとして利用することもできます。ゾーン インスタンスで SLA 99.5% の高可用性を実現します。1 つのクラスタ内で強整合性があり、クラスタ間のレプリケーションにより結果整合性が追加されます。Bigtable の複数クラスタ ルーティングを 2 つのクラスタ間で利用すると、SLA が 99.99% に向上します。そのルーティング ポリシーを 3 つの異なるリージョンにあるクラスタ間で利用すると、稼働率 99.999% の SLA を達成できます。
Cloud Bigtable のレプリケーションにより、データを複数のリージョンまたは同じリージョン内の複数のゾーンにコピーして、データの可用性と耐久性を向上させることができます。Bigtable インスタンスでレプリケーションを使用するには、1 つ以上のクラスタを持つインスタンス作成するか、既存のインスタンスに複数のクラスタを追加します。Bigtable は、Bigtable が利用可能な Google Cloud ゾーンにある最大 4 つの複製クラスタをサポートします。クラスタを別々のゾーンまたはリージョンに配置すると、1 つのゾーンまたはリージョンが利用できなくなった場合でもデータにアクセスできます。Bigtable はインスタンスの各クラスタをプライマリ クラスタとして扱うため、各クラスタで読み取りと書き込みのどちらも可能です。また、さまざまなタイプのアプリケーションからのリクエストがそれぞれ異なるクラスタにルーティングされるようにインスタンスを設定することもできます。データおよびデータの変更は、複数のクラスタにわたって自動的に同期されます。
スループットを最適化する仕組み
処理とストレージを切り離すことにより、Cloud Bigtable はノードとデータの関連付けを調整してスループットを自動的に構成できます。再調整の例では、ノード A の負荷が高くなると、ルーティング レイヤによってトラフィックの一部が負荷の低いノードに移動されて、全体的なパフォーマンスが改善されます。ノードが追加された場合はサイズ変更が行われ、ノード間の負荷が再調整されて、全体のスループットが最適化されます。
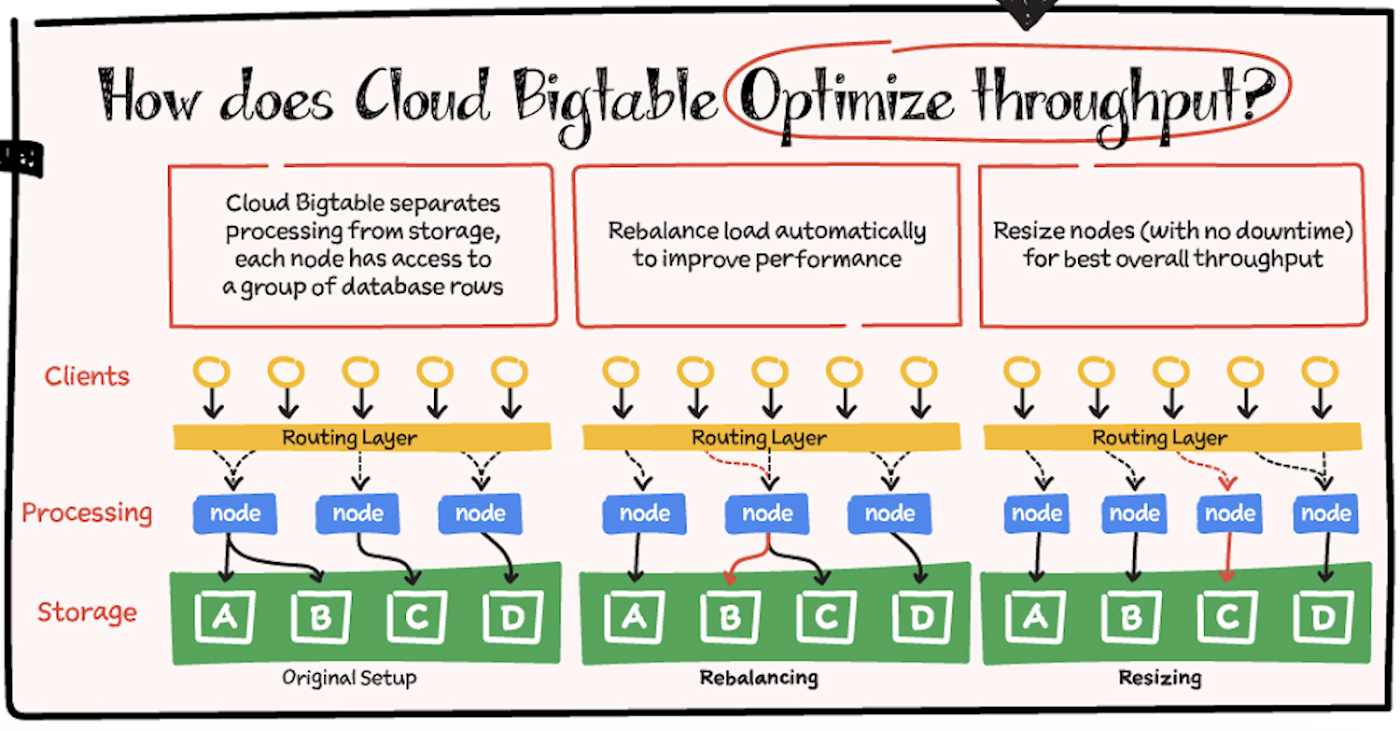
アプリ プロファイルやトラフィック ルーティングの選択もパフォーマンスに影響します。複数クラスタ ルーティングを使用するアプリ プロファイルは、アプリケーションの観点から、インスタンス内の最も近いクラスタに自動的にリクエストをルーティングします。その後、書き込みはインスタンス内の他のクラスタに複製されます。このように最短距離が自動的に選択されるため、レイテンシが可能な限り最小限に抑えられます。単一クラスタ ルーティングを使用するアプリ プロファイルは、ワークロードの分離や単一クラスタでの read-after-write セマンティクスを使用するなど、特定の使用例には最適ですが、複数クラスタ ルーティングのようにレイテンシを低減することはできません。
特に複数クラスタ ルーティングを使用する場合は、レプリケーションによって読み取りスループットが向上します。また、データをユーザーの地理的位置の近くに配置することで、読み取りのレイテンシを短縮できます。書き込みスループットはレプリケーションによって向上しません。これは、1 つのクラスタへの書き込みは、インスタンス内の他のすべてのクラスタに複製される必要があるためです。そのため、各クラスタは、他のクラスタから変更を pull する目的で CPU リソースを消費します。
まとめ
Bigtable は、IoT、AdTech、FinTech、ゲーミング、ML ベースのパーソナライズなど、一定の規模やスループットでレイテンシ要求が厳しいユースケースに最適なデータベースです。Pub/Sub を介してウェブサイトや IoT デバイスから 1 秒間に数十万件ものイベントを取り込み、Dataflow で処理して Cloud Bigtable に送信できます。Cloud Bigtable の詳細については、こちらのドキュメントをご覧ください。また、予定されている Google の専門家によるウェブセミナー Build high-throughput, low-latency apps with Cloud Bigtable(Cloud Bigtable で高スループット、低レイテンシのアプリを構築する)にもご参加ください。
#GCPSketchnote をもっとご覧になるには、GitHub リポジトリをフォローしてください。同様のクラウド コンテンツについては、Twitter で @pvergadia をフォローしてください。thecloudgirl.dev もぜひご覧ください。
-Google デベロッパー アドボケイト Priyanka Vergadia





{kind=link}
{kind=link}