How BIG is Cloud Bigtable?
Priyanka Vergadia
Staff Developer Advocate, Google Cloud
Billy Jacobson
Developer Advocate, Cloud Bigtable
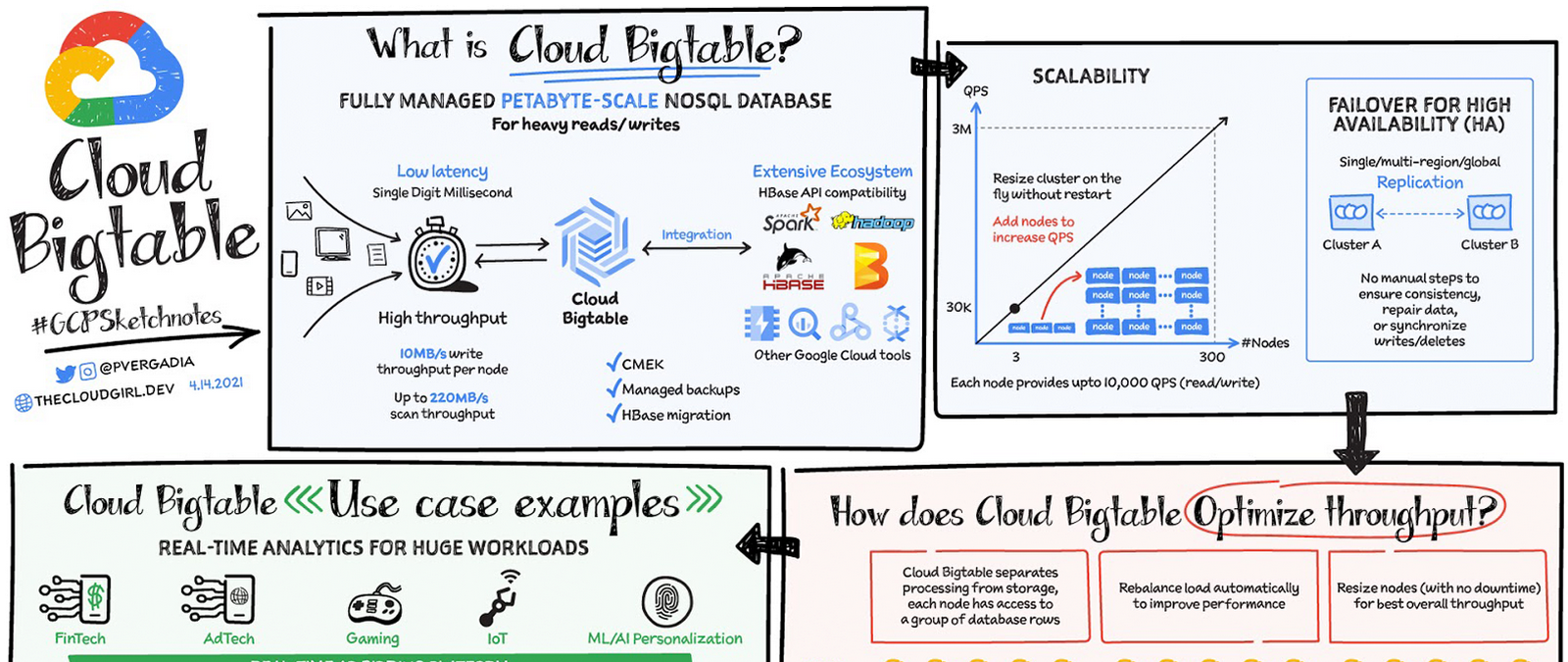
“Building an application that needs low latency and high throughput?”—You need a database that can scale for a large number of reads and writes. Cloud Bigtable is designed to handle just that.
Cloud Bigtable is a fully managed wide-column NoSQL database that scales to petabyte-scale. It's optimized for low latency, large numbers of reads and writes, and maintaining performance at scale. It offers really low latency of the order of single-digit milliseconds. It is an ideal data source for time series and MapReduce-style operations. Bigtable supports the open-source HBase API standard to easily integrate with the Apache ecosystem including HBase, Beam, Hadoop and Spark. It also integrates with Google Cloud ecosystem including Memorystore, BigQuery, Dataproc, Dataflow and more.
Some Cloud Bigtable Features
- Data is by default encrypted with Google managed encryption keys but, for specific compliance and regulatory requirements if customers need to manage their own keys, customer managed encryption keys (CMEK) are also supported.
- Bigtable backups let you save a copy of a table's schema and data, then restore from the backup to a new table at a later time. Backups can help you recover from application-level data corruption or from operator errors such as accidentally deleting a table.
Scale and High Availability (HA)
How BIG is Bigtable? Bigtable has nearly 10 Exabytes of data under management.
It delivers highly predictable performance that is linearly scalable. Throughput can be adjusted by adding/removing nodes -- each node provides up to 10,000 operations per second (read and write). You can use Bigtable as the storage engine for large-scale, low-latency applications as well as throughput-intensive data processing and analytics. It offers high availability with an SLA of 99.9% for zonal instances. It’s strongly consistent in a single cluster; replication between clusters adds eventual consistency. If you leverage Bigtable’s multi cluster routing across two clusters, the SLA increases to 99.99% and if that routing policy is utilized across clusters in 3 different regions you get a 99.999% uptime SLA.
Replication for Cloud Bigtable enables you to increase the availability and durability of your data by copying it across multiple regions or multiple zones within the same region. To use replication in a Bigtable instance, just create an instance with more than 1 cluster or add clusters to an existing instance. Bigtable supports up to 4 replicated clusters located in Google Cloud zones where Bigtable is available. Placing clusters in different zones or regions enables you to access your data even if one zone or region becomes unavailable. Bigtable treats each cluster in your instance as a primary cluster, so you can perform reads and writes in each cluster. You can also set up your instance so that requests from different types of applications are routed to different clusters. The data and changes to data are synchronized automatically across clusters.
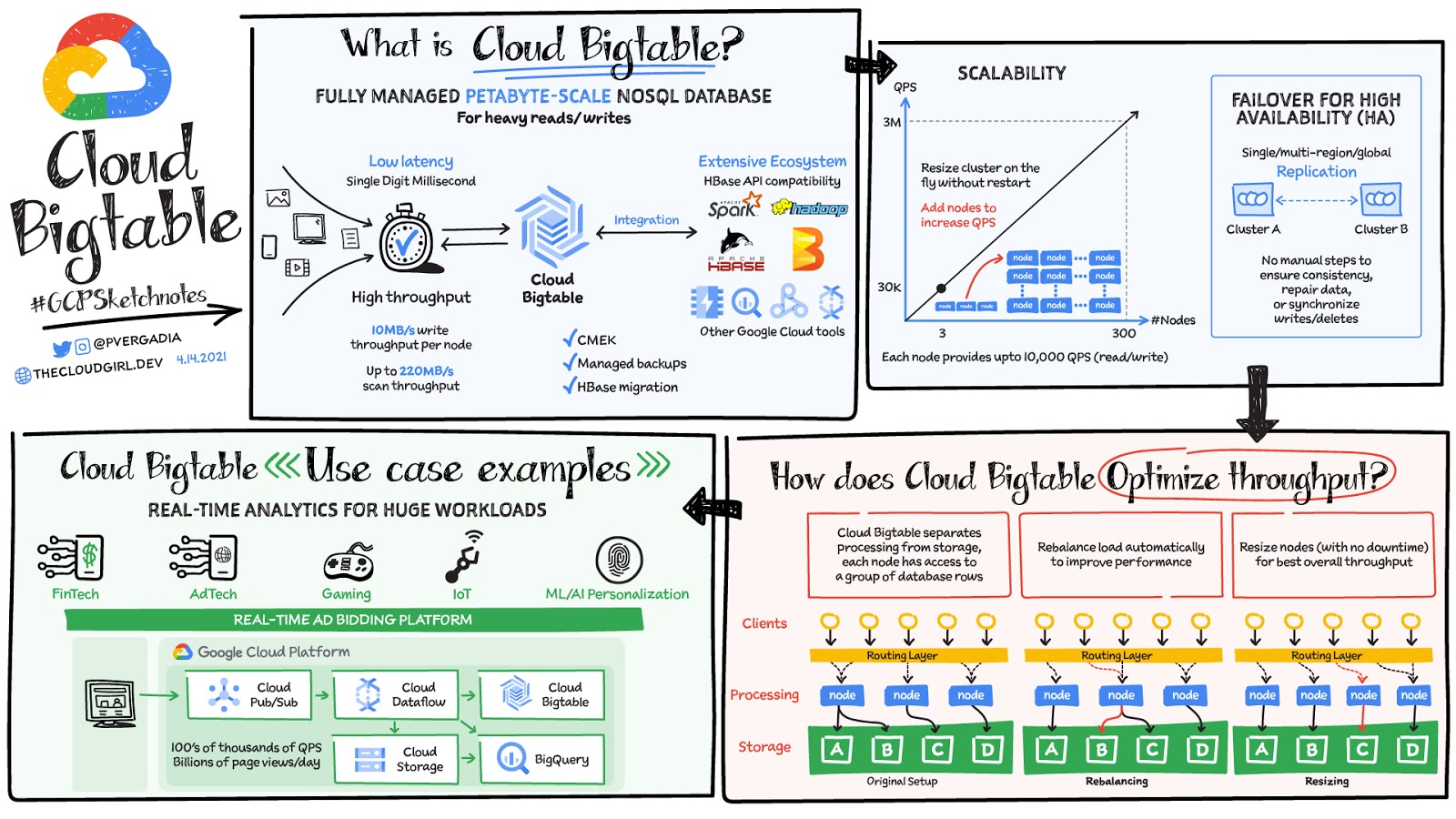
How does it optimize throughput
Through separation of processing and storage, Cloud Bigtable is able to automatically configure throughput by adjusting the association of nodes and data. In the rebalancing example, if Node A is experiencing a heavy load, the routing layer can move some of the traffic to a less heavily loaded node, improving overall performance. Resizing comes into play when a node is added to again ensure a balanced load across nodes, ensuring best overall throughput.

Choice of app profile and traffic routing can also affect performance. An app profile with multi-cluster routing automatically routes requests to the closest cluster in an instance from the perspective of the application, and the writes are then replicated to the other clusters in the instance. This automatic choice of the shortest distance results in the lowest possible latency. An app profile that uses single-cluster routing can be optimal for certain use cases, like separating workloads or to have read-after-write semantics on a single cluster, but it will not reduce latency in the way multi-cluster routing does.
Replication can improve read throughput, especially when you use multi-cluster routing. And it can reduce read latency by placing your data geographically closer to your users. Write throughput does not increase with replication because write to one cluster must be replicated to all other clusters in the instance. Resulting in each cluster spending the CPU resources to pull changes from the other clusters.
Conclusion
Bigtable is a database of choice for use cases that require a specific amount of scale or throughput with strict latency requirements, such as IoT, AdTech, FinTech, gaming and ML based personalizations. You can ingest 100s of thousands of events per second from websites or IoT devices through Pub/Sub, process them in Dataflow and send them to Cloud Bigtable. For a more in-depth look into Cloud Bigtable check out the documentation or join the upcoming webinar with our experts Build high-throughput, low-latency apps with Cloud Bigtable.
For more #GCPSketchnote, follow the GitHub repo. For similar cloud content follow me on Twitter @pvergadia and keep an eye out on thecloudgirl.dev.




