Cloud Spanner のマルチリージョン構成について理解する
Google Cloud Japan Team
※この投稿は米国時間 2021 年 3 月 31 日に、Google Cloud blog に投稿されたものの抄訳です。
Cloud Spanner は、強整合性と優れたスケーラビリティを備えたリレーショナル データベースで、毎月のユーザー数が数十億人にものぼるプロダクトで活用されています。Cloud Spanner は、優れたスケーラビリティと地理的な局所性を実現するため、データのコピー(レプリカ)を複数作成し、地理的に異なる場所に保存します。このブログ投稿では、その詳細について説明します。
Cloud Spanner でデータベースを作成するには、まずインスタンスを作成する必要があります。インスタンスにより、そのインスタンス内のすべてのデータベースが使用するレプリケーション トポロジとリソースが指定されます。インスタンスには次の 2 種類があります。
リージョン(シングル リージョン)- リージョン インスタンスでは、すべてのデータベース レプリカが 1 つの地理的場所に置かれます。アプリケーションが単一の地理的場所に存在し、ゾーン障害や他のハードウェア障害に対する復元力が求められる一方で、リージョン障害への耐性は不要な場合に適しています。
マルチリージョン - マルチリージョン インスタンスでは、データベースが複数のリージョンにレプリケートされます。アプリケーションにリージョン障害への耐性が必要な場合や、アプリケーションを新しい地域にスケールする場合、ユーザーがグローバルに分散しており、データベースのコピーをユーザーの近くに置くことで読み取りレイテンシを低減したい場合に適しています。
インスタンスの作成時に、そのインスタンスのノード数を選択できます。Cloud Spanner の「ノード」は「レプリカ」とは異なるものですので注意してください。ノードは、インスタンスが使用できるサービス リソースとストレージ リソースの量を示します。たとえば、1 個のノードを持つリージョン インスタンスと 2 個のノードを持つリージョン インスタンスでは、データのレプリカはどちらも 3 個になります。ただし、2 個のノードを持つリージョン インスタンスには、1 個のノードを持つリージョン インスタンスと比べて 2 倍のサービス リソースおよびストレージ リソースがある点が異なります。
インスタンスとノードを作成したら、そのインスタンス内にデータベースを作成できます。各インスタンスには、最大 100 個のデータベースを作成可能です。すべてのデータベースは、そのインスタンスのサービス リソースとストレージ リソースを共有します。データベースをスケールするには、インスタンスにノードを追加するだけです。新しいノードを追加してもレプリカ数は変わりませんが、サービス リソース(CPU と RAM)およびストレージ リソースが追加されるため、アプリケーションのスループットが向上します。
では、リージョン インスタンスとマルチリージョン インスタンスの違いと、最適な構成を選ぶ方法について説明します。
シングル リージョン インスタンス
シングル リージョン インスタンスの場合、Cloud Spanner はデータのレプリカを 3 個作成し、単一の地理的場所にある 3 つの障害発生ドメイン(ゾーンと呼びます)に分散させます。たとえば、下の図はリージョン us-east1 の構成を表しています。この構成を使用して作成されたインスタンスはすべて、us-east1 の 3 つのゾーンに分散配置された 3 個のデータベース レプリカを持つことになります。
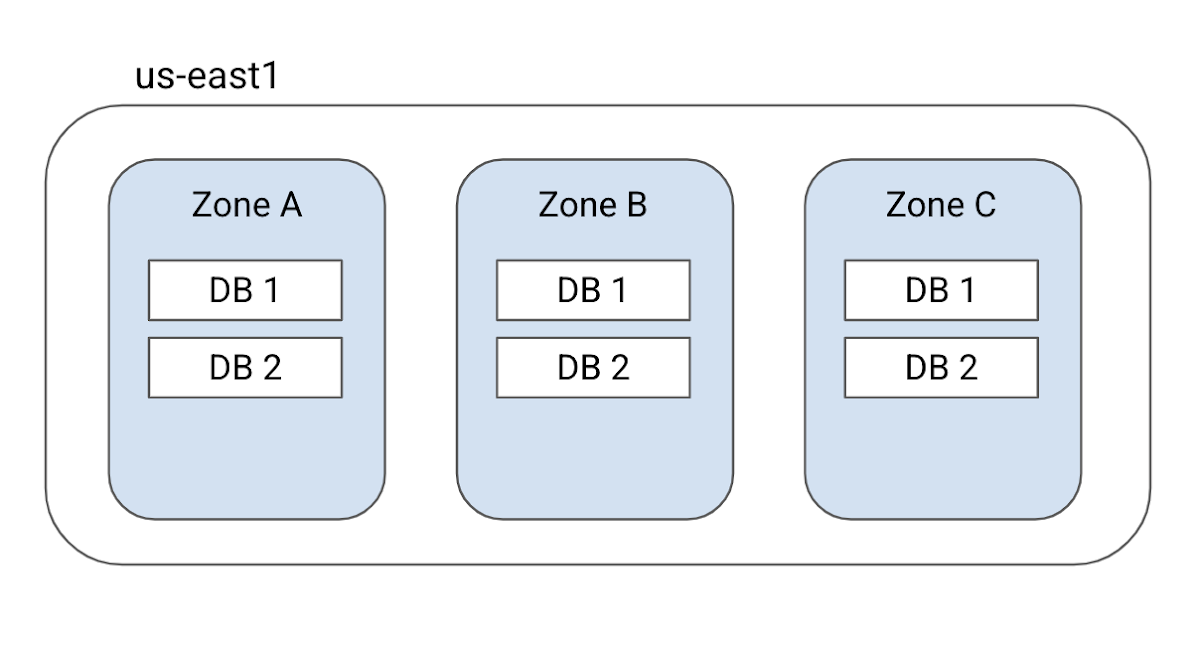
各レプリカにはデータベースの完全なコピーが含まれ、読み取り / 書き込みリクエストと読み取り専用リクエストを処理できます。データの強整合性を実現するため、Cloud Spanner は Paxos ベースの同期レプリケーション スキーマを使用しています。このスキーマでは、書き込みリクエストごとにレプリカが採決(確認)を行います。レプリカの過半数(クォーラムと呼びます)が書き込みの commit に同意すると、書き込みが commit されます。
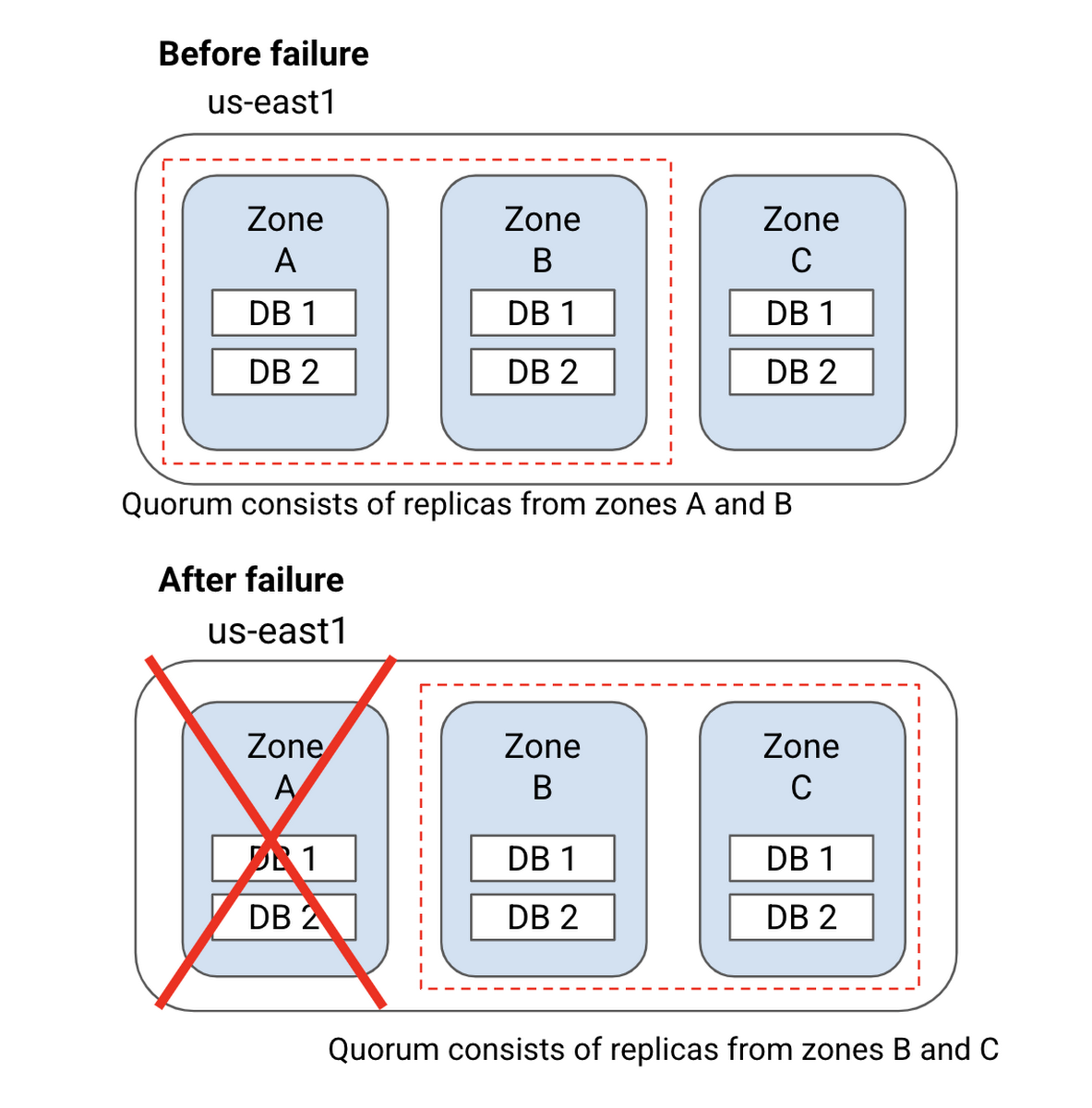
シングル リージョン インスタンスの場合、3 個中 2 個のレプリカが書き込みの commit に同意する必要があります。このため、この種のインスタンスはゾーン障害への耐性を備えています。
マルチリージョン インスタンス
マルチリージョン構成では、Cloud Spanner はデータのレプリカを少なくとも 5 個作成し、3 つ以上のリージョンに分散させます。そのうち 2 つのリージョンに、それぞれ 2 個の読み取り / 書き込みレプリカが 2 つのゾーンに分散する形で配置されます。3 つ目のリージョンには「ウィットネス レプリカ」という特殊なレプリカが 1 つ置かれます。下の図は nam3 マルチリージョン構成の例です。us-east4 リージョンと us-east1 リージョンにレプリカが 2 個ずつあり、us-central1 リージョンにウィットネス レプリカがあります。
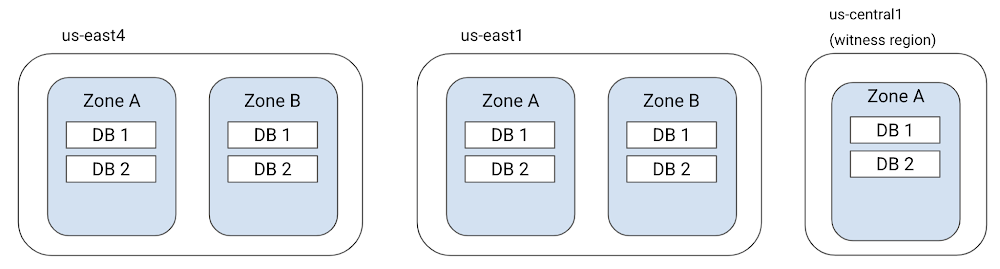
ウィットネス レプリカはデータベースの完全なコピーを格納しません。しかし、書き込みの commit を決める採決には参加します。ウィットネス レプリカがあると、完全なレプリカを必須の要素としなくても、書き込みクォーラムを確保しやすくなります。ウィットネス レプリカの有用性を理解するため、リージョン障害への耐性が必要なデータベースを例として考えてみましょう。データベースには 2 つのリージョンからのアプリケーション トラフィックがあるものとします。2 つのリージョンにだけレプリカがあり、第 3 のリージョンがない場合、どちらかのリージョンが使用できなくなると、過半数のクォーラムを形成するのが不可能になります。こうした事態を回避するために、3 つ目のリージョンにウィットネス レプリカを配置します。
通常、ウィットネス レプリカのリージョンには、2 つある書き込み / 読み取りリージョンのどちらか一方と近いリージョンを使います。そうすることで、ウィットネス リージョンとその近くのリージョンで過半数のクォーラムを形成し、すばやく書き込みを commit できます。ただし、例外も生じ得ます。一部の Cloud Spanner 構成では、2 つの書き込み / 読み取りリージョンが互いに近く(クォーラムを形成)、比較するとウィットネス リージョンがわずかに遠いことがあります。ウィットネス レプリカはデータベースの完全なコピーを保持しないため、読み取りリクエストを処理することはできません。
どのような意思決定でもそうであるように、シングル リージョン インスタンスかマルチリージョン インスタンスかの選択にもトレードオフが伴います。マルチリージョン インスタンスを使用すれば、高可用性(99.999% の可用性)とグローバルなスケーラビリティが実現します。しかし、書き込みレイテンシの増大という代償があります。書き込みのたびに 2 つのリージョンのレプリカでクォーラムを形成する必要があるため、シングル リージョン インスタンスと比べると書き込みのレイテンシが大きくなります。
下の表は、リージョン構成とマルチリージョン構成の違いをまとめたものです。
リージョン | マルチリージョン |
データは 1 つの地理的場所に保存される | データは複数の地理的場所にレプリケートされる |
1 つのリージョンに存在するアプリケーション、または地域的なデータ ガバナンス要件があるアプリケーションに最適 | 複数の地域をまたいで読み取りをスケールする必要があるアプリケーションに最適 |
ゾーン障害への耐性あり | リージョン障害への耐性あり |
リージョン内での読み取りおよび書き込みレイテンシが小さい | 書き込みレイテンシが大きい。複数地域からの読み取りのレイテンシが小さい |
99.99% の可用性 | 99.999% の可用性 |
続いて、マルチリージョン構成の有用なオプションを見ていきます。そのためにまず、Spanner のレプリケーションの仕組みを確認しましょう。
レプリケーションとリーダー レプリカ
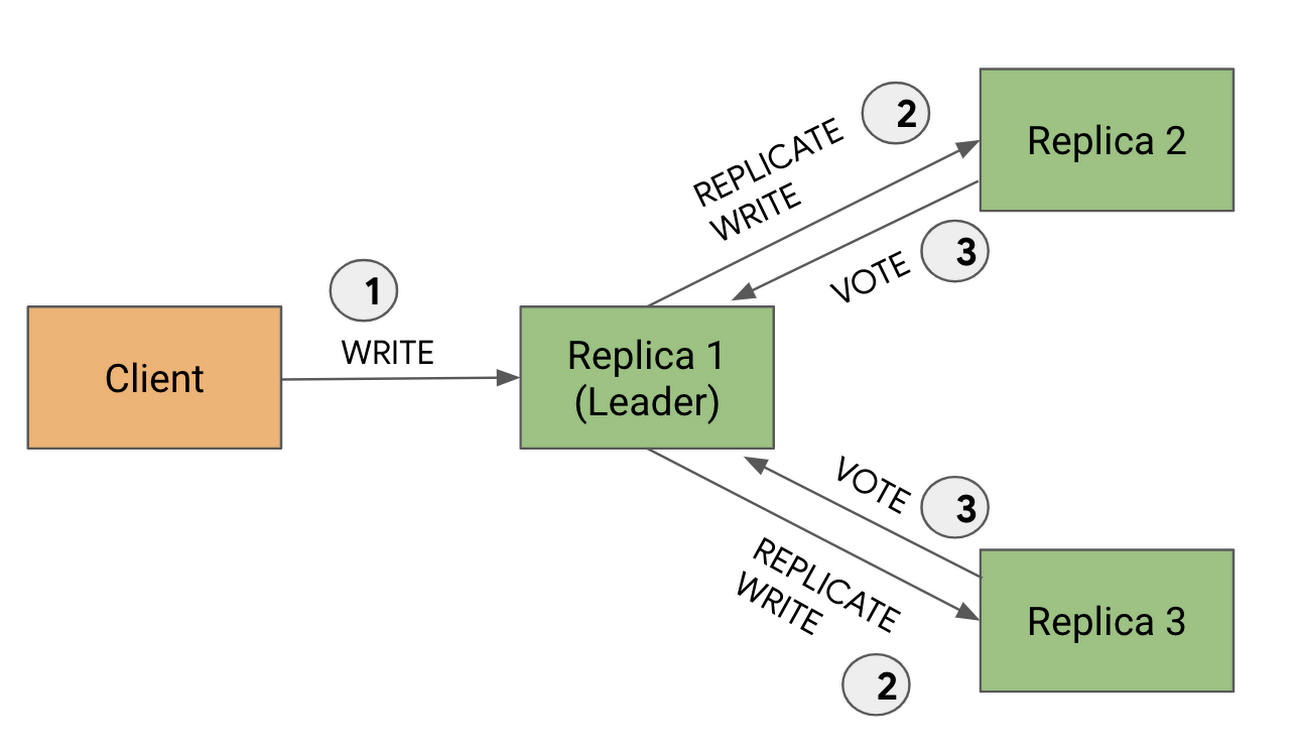
Cloud Spanner は、データを「スプリット」と呼ばれるチャンクに分割します。個々のスプリットが複数のコピー(レプリカ)を持ちます。強整合性を確保するため、これらのレプリカの中から(Paxos を使用して)1 つが選出され、スプリットのリーダーとして機能します。
スプリットのリーダー レプリカは、書き込みの処理を担当します。クライアントのすべての書き込みリクエストは、まずリーダーに送信されます。そこで書き込みがログに保存されてから、他の投票レプリカに送信されます。各レプリカは書き込みを完了した後、リーダーにレスポンスを返し、リーダーが書き込みを commit する必要があるかどうかについて投票します。投票レプリカの過半数が書き込みの commit に同意すると、リーダーは書き込みを commit されたものとみなします。
推奨のリーダー リージョン
マルチリージョン インスタンスでは、スプリットは複数のリージョンにレプリケートされます。複数のリージョンからランダムにスプリットのリーダーを選出すると、アプリケーションのパフォーマンス、特に書き込みトラフィックへの影響が懸念され、強力な読み取りトラフィックにもある程度の影響を与えかねません。たとえば、us-east4 にアプリケーションがあるとします。同じリージョン(us-east4)にリーダーがあるスプリットではアプリケーションのレイテンシに問題がなくても、違うリージョン(us-east1 など)にリーダーがあるスプリットではアプリケーションのレイテンシが大きくなります。
レイテンシの予測可能性を高め、パフォーマンスを適切に制御するため、Cloud Spanner のマルチリージョン インスタンスにはデフォルト(推奨)のリーダー リージョンがあります。Cloud Spanner は、データベースのリーダー レプリカを可能な限りデフォルトのリーダー リージョンに配置します。レイテンシを最小限に抑えるため、アプリケーションの書き込みはデフォルトのリーダー リージョンと同じか近いリージョンで行うことをおすすめします。
リージョン障害の対処
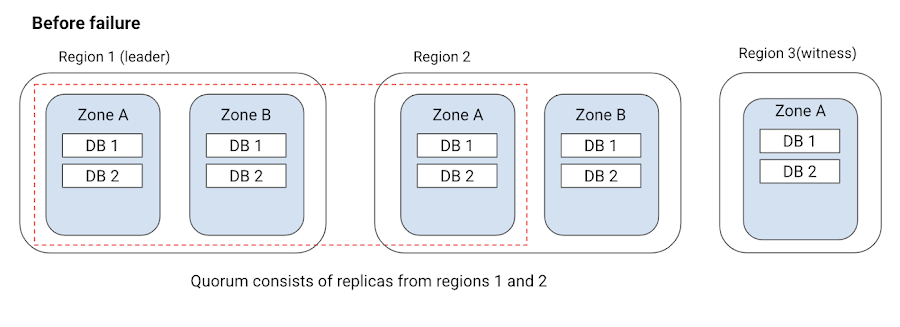
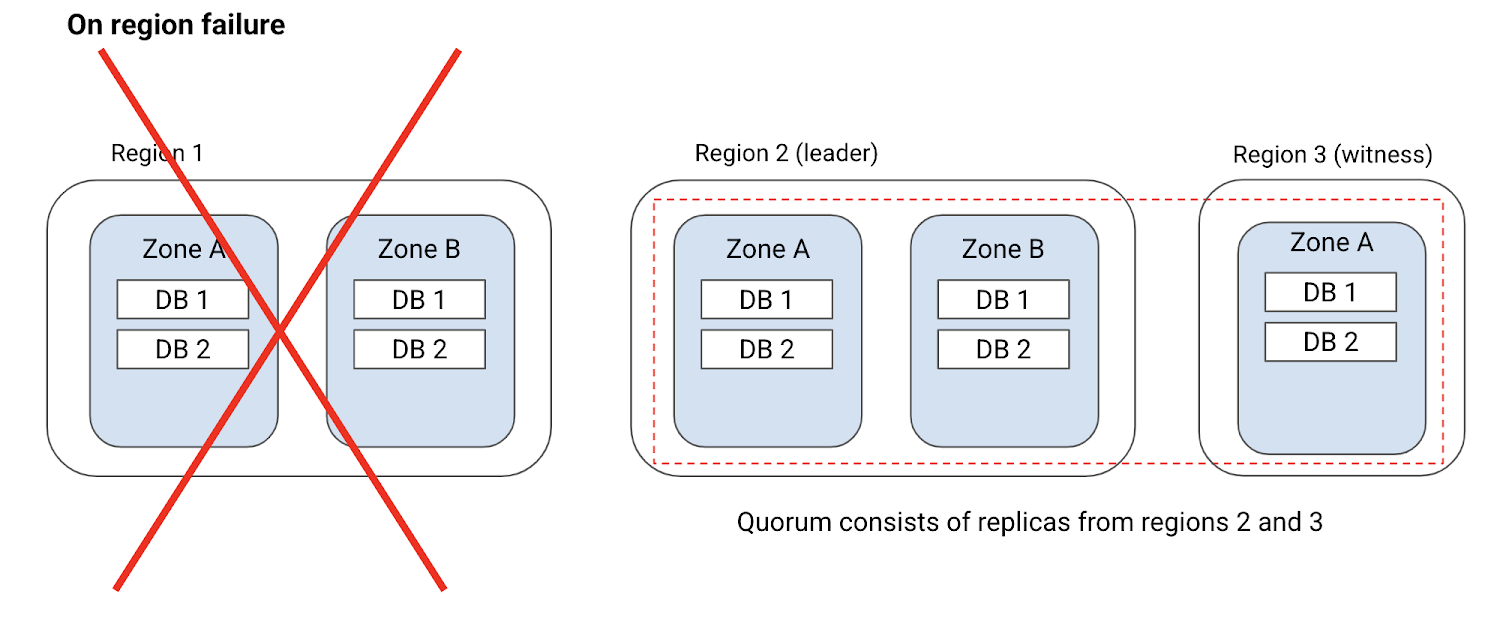
推奨のリーダー リージョンに障害が発生した場合や使用できなくなった場合、Cloud Spanner は別のリージョンにリーダーを移します。Cloud Spanner が、リーダーが使用できないことを検知し、新しいリーダーを選出するまでに数秒(10 秒未満)の遅延が生じる可能性があります。この間、アプリケーションの読み取りおよび書き込みレイテンシが大きくなることも考えられます。Cloud Spanner は断続的なエラーに対して頑健で、クライアント リクエストを透過的に再試行します。そのため、アプリケーションにダウンタイムが発生することはなく、レイテンシの一時的な増大だけで済みます。推奨のリーダー リージョンが復帰すると、リーダーは自動的にその推奨リージョンに戻ります。この際、アプリケーションにダウンタイムやレイテンシの影響はありません。
ゾーン障害の対処
推奨のリーダー リージョン内にある 1 つのゾーンが使用できなくなると、Cloud Spanner は推奨のリーダー リージョン内にあるもう 1 つのゾーンにすべてのリーダーを移し、推奨のリーダー設定を維持します。
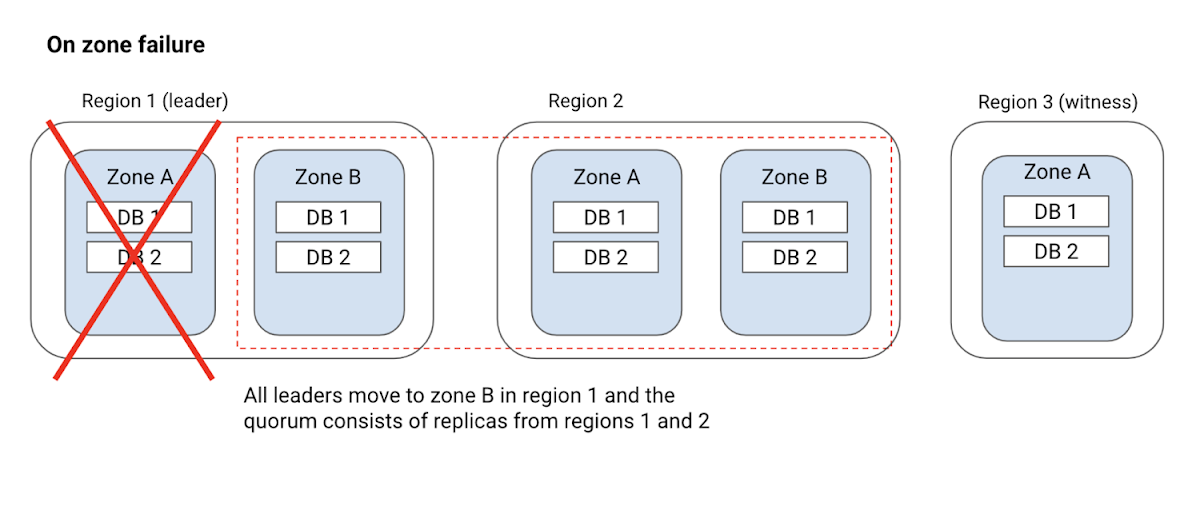
上の図のように、ゾーン A に障害が発生しても、リージョン 1 がリーダー リージョンであることは変わらず、すべてのリーダーがリージョン 1 のゾーン B に移動します。
読み取り専用レプリカ
Cloud Spanner のマルチリージョン構成の注目すべき点として、読み取り専用レプリカがサポートされていることが挙げられます。読み取り専用レプリカは、リモート リージョンの読み取りレイテンシを下げるのに役立ちます。たとえば、グローバルに分散した e コマース アプリケーションを考えてみてください。北米、アジア、欧州の複数のリージョンで読み取り / 書き込みレプリカを使用すると、大陸をまたいでレプリケートされるため、書き込みレイテンシが非常に大きくなります。これを回避するため、読み取り / 書き込みレプリカを 1 つの大陸、たとえば北米のリージョンに制限し、読み取り専用レプリカを欧州とアジアに追加します。読み取り専用レプリカは書き込みの採決には参加しないため、書き込みレイテンシは小さくなります。同時に、読み取り専用レプリカによって、欧州とアジアでの読み取りレイテンシを小さくすることもできます。
強力な読み取りとステイル読み取り
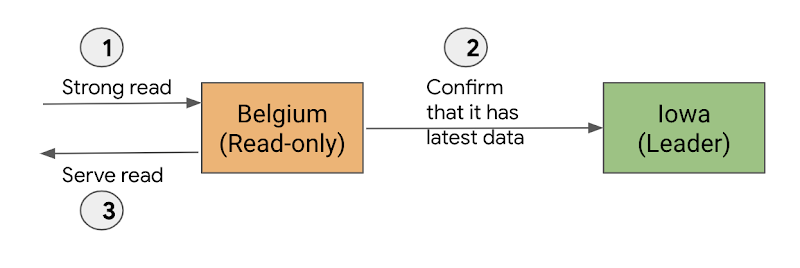
Cloud Spanner での読み取りは、デフォルトでは常に最新データの読み取りです。このような読み取りは「強力な読み取り」と呼ばれ、読み取りの開始時までに commit されたすべてのデータを確実に参照できます。強力な読み取りはすべてのレプリカが実行できます。ただし、読み取りを実行するにあたり、レプリカはリーダーと通信して自身のデータが最新であることを確認しなければならない場合があります。そのため、リーダーと異なるリージョンにあるレプリカが強力な読み取りを実行すると、レイテンシが大きくなる可能性があります。レプリカは多くの場合、自身のデータが最新であり、読み取りを実行できる状態であることを自身の内部状態から認識します。しかし、認識できなかった場合はリーダーと通信し、データが最新になるまで待機してから、読み取りを実行します。
レイテンシの影響を受けやすいものの、データが最新でなくても許容できるアプリケーションには、ステイル読み取りが適しています。この読み取りは過去のタイムスタンプで実行されます。タイムスタンプの時点にまで追いついている、最も近いレプリカによって実行されます。ステイル読み取りの値は 15 秒にすることをおすすめします。この値は、リーダーが通常 10 秒ごとにレプリカを更新し、信頼できる最新のタイムスタンプを付与することに基づいています。ステイルネスの値が 15 秒あれば、レプリカは内部状態から自身のデータが最新で読み取りを行えるかどうかを認識でき、リーダーと通信することなく直ちに読み取りを処理できる可能性が高くなります。この値は 15 秒未満に設定することもできます。ただし、その場合の一部の読み取りでは、レプリカが自身のデータが最新かどうかを認識できず、リーダーに問い合わせることになるため、読み取りレイテンシの増大につながることが予想されます。

まとめ
強力な読み込み | ステイル読み取り |
リージョン間の読み取りのレイテンシが大きい | 低レイテンシ |
確実に最新データを提供 | 読み取りデータが最新でない可能性あり |
書き込みを読み取る必要があるアプリケーションには必須 | 最新でないデータを許容でき、レイテンシの影響を受けやすいアプリケーションに最適 |
終わりに
Cloud Spanner は強整合性と高可用性を両立しているだけでなく、インスタンス構成、レプリカの種類、読み取りの種類(強力な読み取りとステイル読み取り)に選択の幅があり、アプリケーションのレイテンシや障害に対する復元力の要件に応じた使用が可能です。それぞれのオプションの特長を把握して最適な構成を選択するうえで、このブログ投稿が参考になれば幸いです。
まずは Cloud Spanner インスタンスを GCP アカウントまたは Spanner Qwiklab で作成し、新しいクエリ体験をお試しください。
-Cloud Spanner ソフトウェア エンジニアリング マネージャー Neha Deodhar


