Datasets for Google Cloud: 新しいリファレンス アーキテクチャのご紹介
Google Cloud Japan Team
※この投稿は米国時間 2021 年 5 月 21 日に、Google Cloud blog に投稿されたものの抄訳です。
Datasets for Google Cloud が発表されました。このブログ投稿では、Google Cloud 一般公開データセット プログラムの簡単なデータ オンボーディング プロセスのために構築した新しいリファレンス アーキテクチャについて詳しくご説明します。
データ オンボーディング: デベロッパー エクスペリエンスの向上
Google にとって、データ オンボーディングは既存の送信元から目的の宛先にデータを pull、変換、保存することにとどまりません。その結果得られたデータを分析しやすくし、データ パイプラインの構築と維持を担当するデベロッパー エクスペリエンスをより快適にすることも含まれます。デベロッパー エクスペリエンスは、データ エンジニアリング チームが数百から数千ものデータ パイプラインに業務を拡大するにつれて、チームの生産性においてますます重要な役割を担うようになりました。
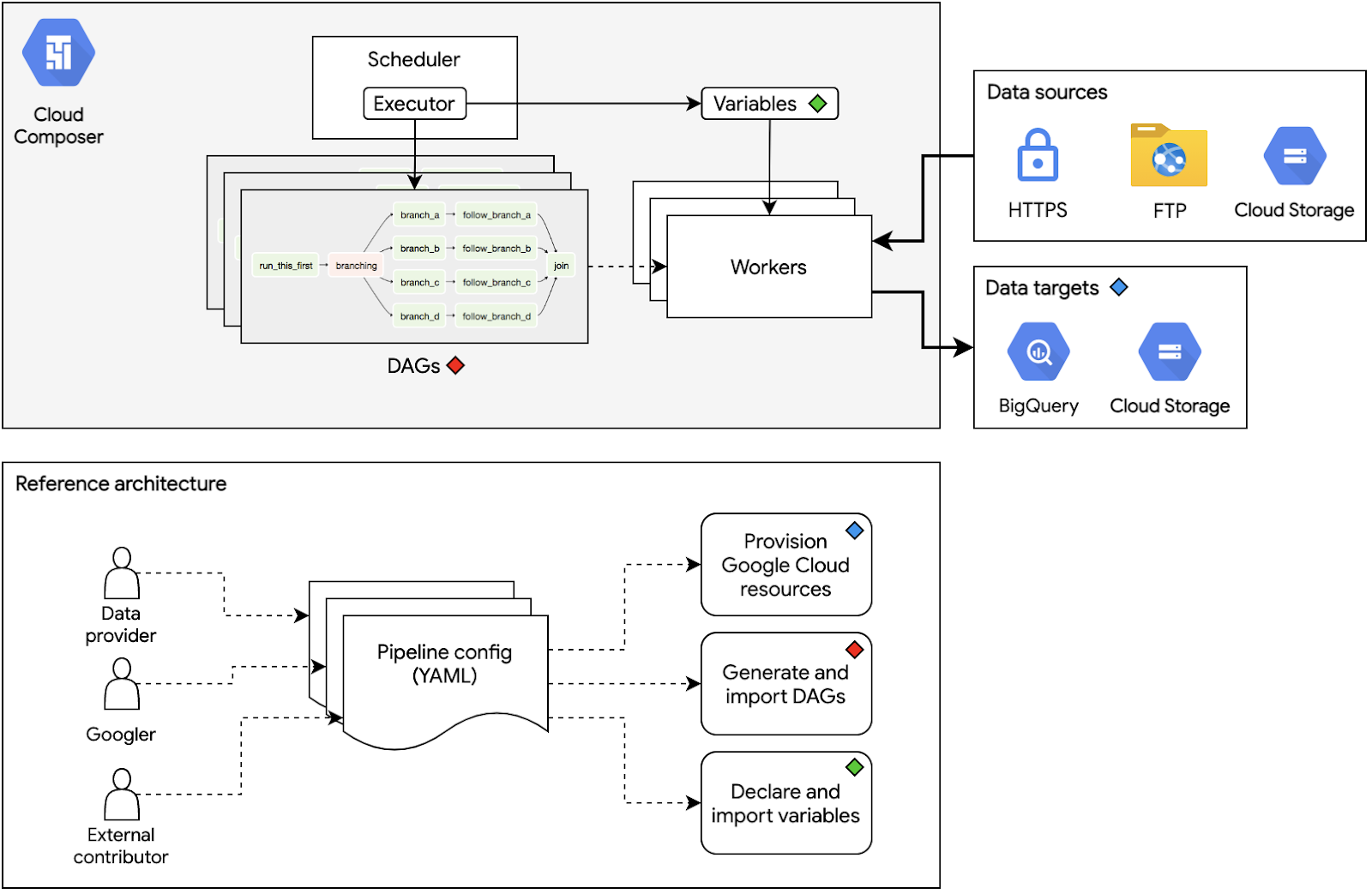
Google チームは Cloud Composer を利用し、標準化された一元的な方法でデータ パイプラインを管理、モニタリングします。すべてのデータ パイプラインは有向非巡回グラフ(DAG)で表され、DAG 内のすべてのノード(タスクとも呼ばれます)は Apache Airflow オペレータで表されます。各オペレータは 1 回の操作を実行します。たとえば、Cloud Storage との間でデータを転送するなどの単純な操作から、Google Kubernetes Engine クラスタを使用して大規模なデータセットにカスタムデータ変換を適用するなどの複雑な操作まで実行します。データ エンジニアが DAG 実行の状態をモニタリングし、操作のグラフとして可視化できれば、理解しやすさと保守性が大幅に向上します。
Cloud Composer 環境には数多くのコンポーネントがあり、十分に油を差した機械のごとくパイプラインの操作が継続できるようにエンジニアが常に管理する必要があります。コンポーネントの処理としては、一貫性のある予測可能な方法での DAG の作成や、Airflow 変数の宣言、設定、インポート、すべてのパイプラインが依存する他のクラウド リソースの操作などがあります。新しいリファレンス アーキテクチャの目的は、YAML 構成ファイルで各コンポーネントの管理を統合して、こうしたすべての処理を簡素化することです。
オープンソースのメリット
Google は、一般公開データセットの新しいリファレンス アーキテクチャをオープンソース化することに決定しました。詳しくは、GitHub の Google Cloud Platform 組織の下のディレクトリをご覧ください。
すべての Google Cloud 一般公開データセットを強化するデータ パイプラインのアーキテクチャをオープンソース化するメリットは、次の 3 つです。まず、アナリストや研究者などのデータ コンシューマに、データのソースと派生方法に関する透明性を提供します。次に、データセットを Google Cloud で一般公開することに関心のあるコミュニティにプログラムを開放します。最後に、他のユーザーが独自の方法でアーキテクチャを使用できます。たとえば、プライベート フォークを使用して、自身の Google Cloud アカウントで独自のデータセットを営利目的でオンボーディングします。
データ エンジニアリングのフレームワーク
新しいリファレンス アーキテクチャをとらえる方法として、ウェブ フレームワークとの類似性が挙げられます。ウェブ フレームワークは、ウェブ アプリケーションの構築時に必要な手間のかかる作業の大半を支援するツールと言えます。同様に、新しいリファレンス アーキテクチャはデータ パイプラインを開発し維持する際に、オーバーヘッドを削減できます。
Airflow の作成者である Maxime Beauchemin 氏は、講演 Advanced Data Engineering Patterns with Apache Airflow(Apache Airflow による高度なデータ エンジニアリング パターン)で、メタデータ エンジニアリングという用語を作り出しました。メタデータ エンジニアリングは、データ エンジニアリングのオーバーヘッドの上に抽象化レイヤを構築するという概念を中心に展開しています。一連のルールと規則に基づいてデータ パイプラインを動的に生成することは、そのような概念を実現できる具体的な方法の一つです。この処理を新しいリファレンス アーキテクチャが行います。Google の目標は、データ エンジニアリングが、ウェブ フレームワークがソフトウェア エンジニアリングに対して提供したメリットを導入することです。
まとめ
何百もの既存データ パイプラインを Google Cloud に移行する取り組みを強化しつつ、このアーキテクチャがサポートできるリファレンス パターンのスペースを拡大し続けてまいります。それに加え、データの説明、ポリシー、サンプル ユースケースなどのドキュメント セットとアーキテクチャを統合することも計画しています。これらを含めると、データセットの付加価値が増大します。オンボーディング プロセスの一部としてデータ分析と可視化を組み込んだ場合を考えてみてください。
新しいリファレンス アーキテクチャで引き出せる可能性がある Google Cloud 上のデータセットのメリットは、ごく一部にすぎません。また、GitHub で Issue を開くことにより、オンボーディングのリクエストを送信したり、バグを報告したり、新機能の開発を支援し、コラボレーションに参加することができます。ぜひご参加ください。
-Datasets for Google Cloud 担当エンジニアリング リード Adler Santos



