Datasets for Google Cloud: Introducing our new reference architecture
Adler Santos
Engineering Lead, Datasets for Google Cloud
We are so excited by the announcement of Datasets for Google Cloud. In this blog post, I'd like to share more details about the new reference architecture that we built for a more streamlined data onboarding process for the Google Cloud Public Datasets Program.
Data onboarding: Enhancing the developer experience
For us, data onboarding isn't only about pulling, transforming, and storing data from pre-existing sources into their desired destinations. It's also about making the resulting data easier for analysis, and providing a better experience for developers tasked with building and maintaining data pipelines. The developer experience plays an increasingly vital role in the productivity of data engineering teams as they scale their efforts to hundreds or even thousands of data pipelines.
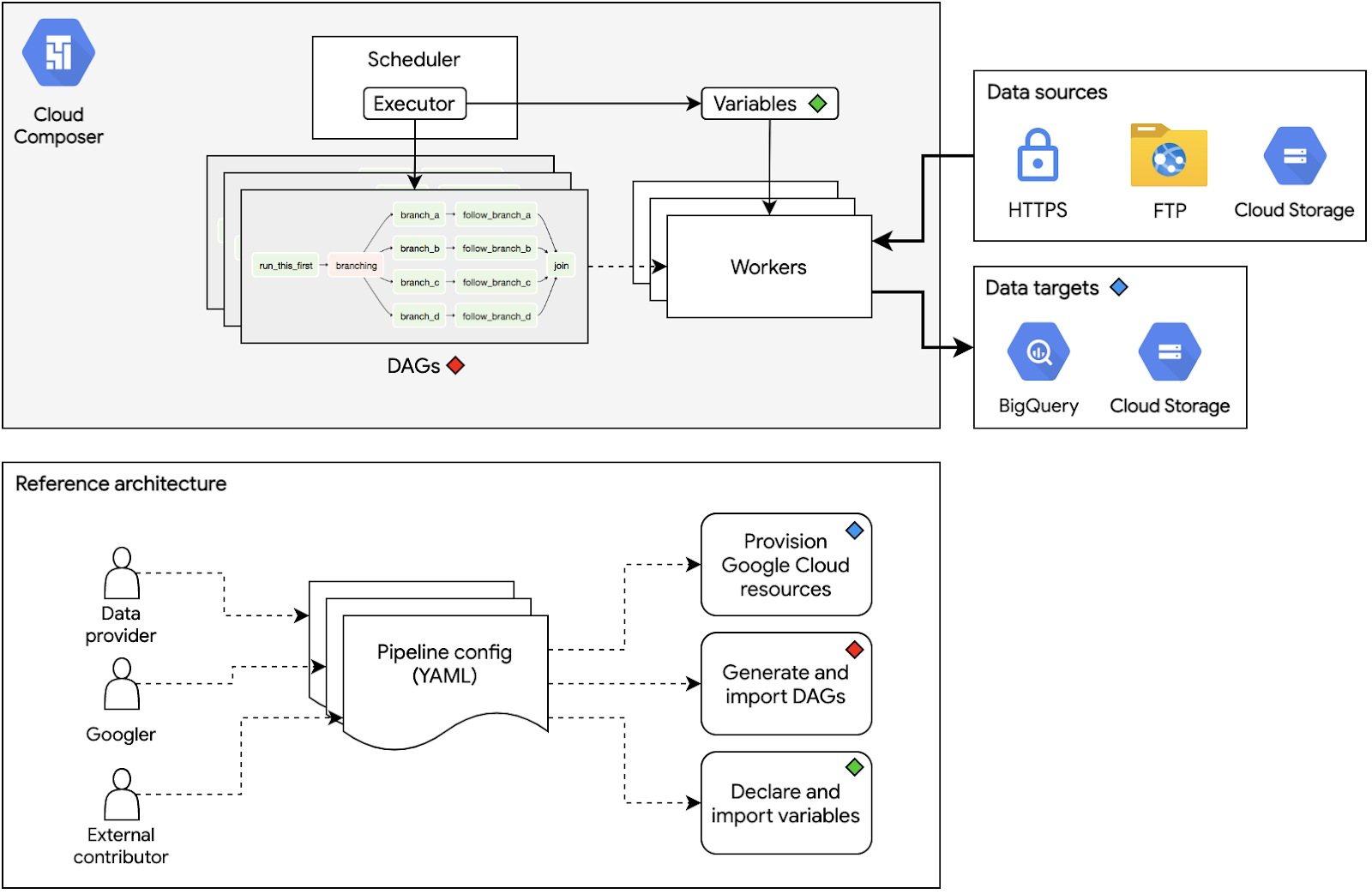
Our team uses Cloud Composer to manage and monitor data pipelines in a centralized and standardized way. Every data pipeline is represented as a directed acyclic graph (DAG), and every node (also known as a task) in a DAG is represented by an Apache Airflow operator. Each operator performs a single action: from simple actions such as transferring data to and from Cloud Storage, to more complex operations such as using a Google Kubernetes Engine cluster to apply custom data transforms on large datasets. The ability for data engineers to monitor the states of DAG executions and to visualize them as graphs of operations greatly improves comprehensibility and maintainability.
There are many components of a Cloud Composer environment that engineers must constantly manage to keep its pipelines operating like well-oiled machines: writing DAGs in a consistent and predictable manner; declaring, setting, and importing Airflow variables; and actuating other cloud resources that every pipeline relies on. Our new reference architecture aims to simplify all the work mentioned by using YAML configuration files to unify control of these components.
The benefits of open source
We have proudly made the decision to open source the new reference architecture for our public datasets. It can be found on GitHub under the Google Cloud Platform organization.
Open sourcing the data pipeline architecture that powers all of Google Cloud Public Datasets helps in three ways. First, it gives transparency to data consumers such as analysts and researchers about where the data was sourced and how it was derived. Second, it opens up the program to communities interested in making their datasets publicly available on Google Cloud. And third, it lets others use the architecture in their own way—for example, by using a private fork to onboard their own datasets for commercial use in their own Google Cloud accounts.
A framework for data engineering
One way to think of the new reference architecture is through an analogy with web frameworks. We think of web frameworks as tools to help with much of the heavy lifting required when building web applications. In the same way, our new reference architecture helps reduce overhead when developing and maintaining data pipelines.
Maxime Beauchemin, the creator of Airflow, coined the term Meta Data Engineering in his talk Advanced Data Engineering Patterns with Apache Airflow. Meta Data Engineering revolves around the concept of providing layers of abstraction on top of data engineering overhead. Being able to dynamically generate data pipelines based on a set of rules and conventions is one concrete way to accomplish such a concept. The new reference architecture does this, and our goal is for data engineering to adopt the benefits that web frameworks did for software engineering.
Conclusion
As we ramp up our efforts in migrating hundreds of our existing data pipelines to Google Cloud, we will keep expanding the space of possible reference patterns that this architecture can support. On top of that, we also plan to integrate the architecture with documentation sets such as data descriptions, policies, and example use cases. Including these will add greater value to the datasets—imagine bundling up data analysis and visualization as part of the onboarding process.
We're only scratching the surface when it comes to what the new reference architecture can potentially unlock for Datasets on Google Cloud. We invite everyone who's interested in collaborating with us in three ways by opening an issue on GitHub: send data onboarding requests, file a bug, or help us develop new features.




