BigQuery Write API 特集: Write API の概要
Google Cloud Japan Team
※この投稿は米国時間 2022 年 2 月 2 日に、Google Cloud blog に投稿されたものの抄訳です。
2021 年に一般提供が開始された Google BigQuery Write API は、1 つの統合型 API で高性能なバッチ処理とストリーミングを実現する、BigQuery の推奨データ取り込みパスです。提供開始以来、パフォーマンスとユーザビリティを向上させるために数多くの機能や改善が追加され、より簡単にデータを BigQuery に直接取り込めるようになりました。統合型ということで、次のような優れた機能もあります。
Google Cloud Storage ではステージングせずにデータを BigQuery に直接取り込むことができるため、ワークフローを簡素化できます。
データをストリーム処理してすぐに読み込めるため、低レイテンシでレスポンスの早いデータ アプリケーションを作成できます。
1 回限りの配信を保証することで、重複除去のカスタム ロジックを作成する必要がなくなります。
行バッチレベルのトランザクションがサポートされ、安全な再試行とスキーマ更新の検出が可能になります。
この最初の投稿では、こうした新機能を掘り下げ、BigQuery Write API と BigQuery の他のデータ取り込み方法との比較や、すぐに利用する方法について説明します。
BigQuery へのデータの取り込み
BigQuery のマネージド ストレージにデータを取り込む方法は複数あります。具体的な取り込み方法は、ワークロードによって異なります。一般に、バッチ レイテンシが問題にならない 1 回限りの読み込みジョブや繰り返しのバッチジョブには、BigQuery Data Transfer Service または BigQuery 読み込みジョブを使用できます。それ以外の場合は、BigQuery Write API でデータを取り込むことをおすすめします。
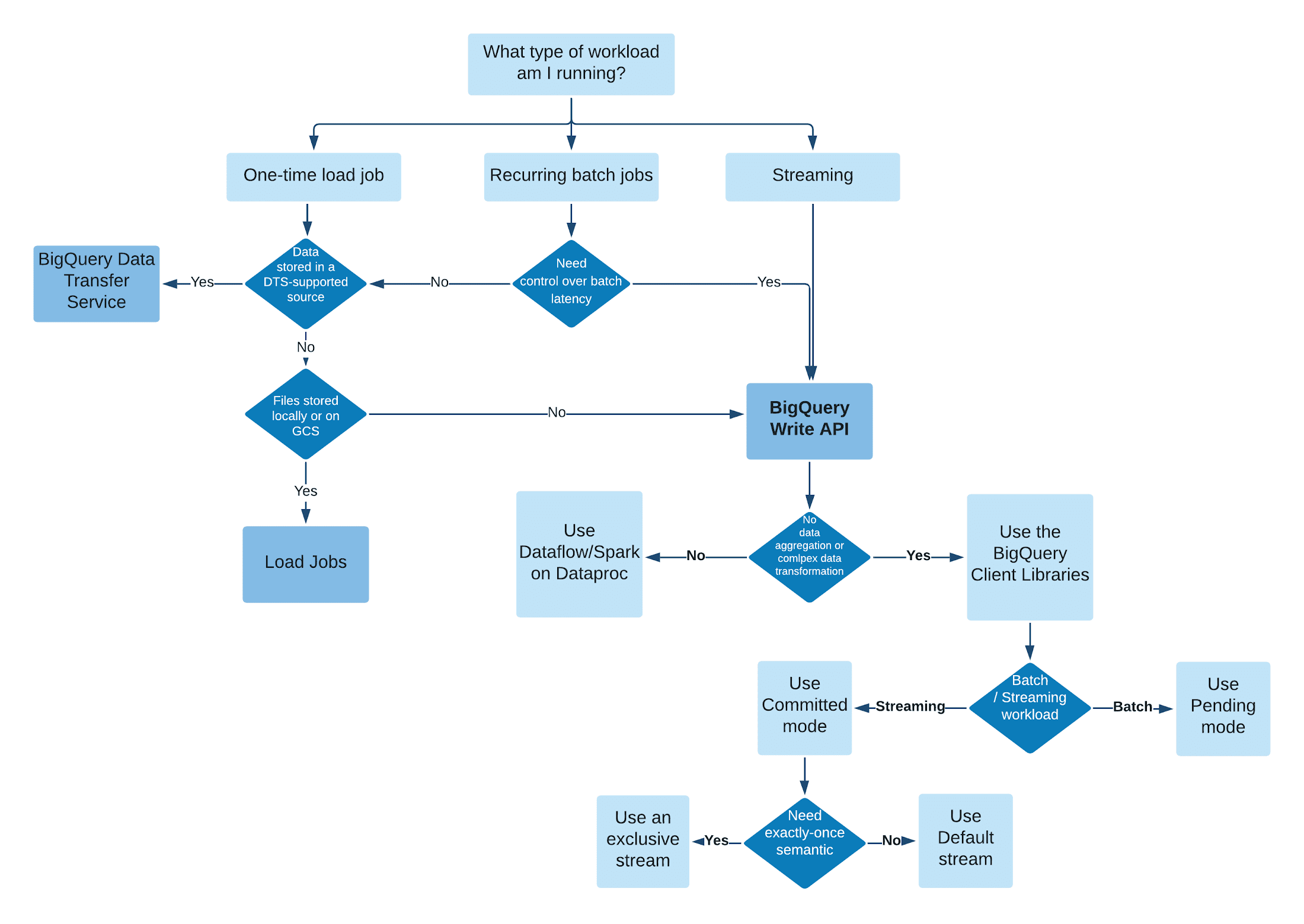
BigQuery Write API 登場前は、BigQuery にデータを取り込むには BigQuery 読み込みジョブまたは従来型のストリーミング API という 2 つの方法がありました。
読み込み
BigQuery 読み込みジョブは主に、Google Cloud Storage から BigQuery にデータを取り込む、バッチのみのワークロードに適しています。BigQuery Data Transfer Service は内部で読み込みジョブを使用していますが、Google Cloud Storage 以外の他のソースからデータを転送したり、スケジュールに沿ってバッチ読み込みを実行したりできます。ただし、読み込みジョブはバッチモードの挿入であるため、ジョブの実行に時間がかかることがあり、取り込みパフォーマンスは割り当てられたコンピューティング リソースに比例します(BigQuery Reservation をご覧ください)。つまり、読み込みジョブでは、データソースから BigQuery に低レイテンシで直接データを取り込むことはできません。
BigQuery の読み込みジョブと比較して、BigQuery Write API には次のような特長があります。
ストリーム レベル トランザクション: 1 つのストリームに 1 回しか commit できないため、安全に再試行できます。
ワークフローの簡素化: BigQuery ストレージに直接書き込むことにより、Google Cloud Storage にデータをエクスポートしてから BigQuery に読み込む必要がなくなります。
SLO: BigQuery Write API には、Query Jobs や従来型のストリーミング API など、他の既存の BigQuery API と同程度の SLO があります。
従来型のストリーミング API
従来型のストリーミング API では、非常に低いレイテンシでリアルタイムにデータを取り込むことができましたが、ユーザーが挿入ステータスを追跡する必要があり、再試行するとレコードが重複するおそれがありました。
従来型のストリーミング API と比較して、BigQuery Write API には次のような特長があります。
書き込みのべき等性: 従来型のストリーミング API は、ベストエフォート型の重複除去をわずかな期間(数分程度)しかサポートしません。しかし BigQuery Write API では、同じストリーム上の特定のオフセットで 1 回しか追加が行われないようになるため、書き込みのべき等性が保証されます。
高スループット: デフォルトの割り当てが、従来型のストリーミング API(1 GB/秒)と比較して Write API では 3 倍(3 GB/秒)になっており、データの取り込みにおけるスループットが向上します。追加の割り当てはリクエストに応じてプロビジョニングできます。
低コスト: 従来型のストリーミング API と比較して、1 GB あたりのコストが 50% 削減されます。
また、Write API はバッチ処理とストリーミング処理の統合をサポートしているため、すべてのワークロードを大規模に処理するために別々の API を使用する必要がなくなります。
新しいストリーミング バックエンドによるバッチ処理とストリーミング処理の統合型 API
Write API は新しいストリーミング バックエンドを基盤にしているため、以前のバックエンドと比較してより大きなスループットを処理でき、データの信頼性も向上しています。新しいバックエンドは BigQuery を支えるエクサバイト規模の構造化ストレージ システムであり、GCP のすべての分析エンジンでスケーラブルなストリーミング分析を行うためのストリーム ベースの処理をサポートするように構築されています。バッチモード処理向けに最適化された前身のバックエンドとは異なり、新しいストリーミング バックエンドはストリーミングを最上級のワークロードとして扱い、高スループットのリアルタイム ストリーミングと処理をサポートします。1 回限りのセマンティクスと、クエリに対する即時のデータ利用が可能なストリーム指向のストレージです。
BigQuery Write API の始め方
StreamWriter を作成し、append メソッドを呼び出すことで、BigQuery Write API を使用した高スループットのデータ ストリーミングを開始できます。Java でバイナリ形式のデータをネットワーク経由で送信する例を次に示します。
データが Protobuf 形式で保存されていない場合は、クライアント ライブラリの JsonStreamWriter(Java で提供中)を使用して、JSON データを直接 BigQuery にストリーミングできます。また、この例ではデフォルトのストリームを使用しているため、1 回以上の(1 回限りではない)セマンティクスが提供されます。Dataflow とクライアント ライブラリで 1 回限りのセマンティクスを実現する方法については、今後の投稿でご紹介します。
次のステップ
この記事では、BigQuery へのデータ取り込みパスにおける BigQuery Write API の位置付け、BigQuery Write API が高速かつ低価格である理由、BigQuery Write API の始め方について説明しました。今後の投稿では、BigQuery Write API をデータ パイプラインに簡単に組み込む方法、API を使用するうえで重要な新しいコンセプト、そして新機能を取り上げます。
今後の情報にご注目ください。ご精読ありがとうございました。質問やチャットをご希望の場合は、Twitter または LinkedIn でご連絡ください。
この投稿に協力してくれた Gaurav Saxena、Yiru Tang、Pavan Edara、Veronica Wasson の各氏に感謝します。
- Developer Relations エンジニア Stephanie Wang


