Vertex Pipelines コードを管理するためのベスト プラクティス
Google Cloud Japan Team
※この投稿は米国時間 2022 年 11 月 10 日に、Google Cloud blog に投稿されたものの抄訳です。
機械学習(ML)ワークフローの合理化とスケーリングに ML パイプラインを使用する組織が増えています。しかし、組織内に複数の ML プロジェクトがあり、パイプラインの開発段階がそれぞれ異なる場合、パイプラインの管理は簡単ではありません。これを解決するには、DevOps のコンセプトを構築し、ML 特有の問題に適用する方法が必要です。この記事では、ML パイプラインのコードベースを管理するベスト プラクティスをご紹介します。
ここに挙げるガイダンスは、Google Cloud の主要ユーザーやパートナーとの協力に基づいています。過去に見てきたパイプライン実装パターンに基づいて、いくつかベスト プラクティスをご紹介しますが、もちろん問題の解決策は各企業の要因によって異なります。したがってお手本を示すことを目的とはしていません。そのことを踏まえつつ、ML パイプラインの開発ライフサイクルについて掘り下げ、どう管理すべきか検討してみましょう。
パイプライン コードの管理
どんなソフトウェアシステムでも、開発者は本番環境システムの安定性を維持したまま、コードで実験と反復処理を実行できる必要があります。また、DevOps のベスト プラクティスでは、システムはデプロイ前に徹底的にテストを重ね、デプロイはできるだけ自動化します。ML のパイプラインも例外ではありません。
Vertex AI で ML パイプラインを実行する標準的なプロセスは次のようになります。
Kubeflow Pipelines または TFX DSL(ドメイン専用の言語)を使用し、Python でパイプライン コードを記述する
KFP または TFX ライブラリを使用し、JSON 形式にパイプライン定義をコンパイルする
コンパイルしたパイプライン定義を Vertex AI API に送信し、すぐに実行する
上記の手順を信頼性の高い本番環境システムに効果的にパッケージ化し、しかも ML 担当者がパイプライン開発で実験や反復処理を実行できるようにするには、どうすればよいでしょうか?
ステップ 1: パイプライン コードを書く
どんなソフトウェア システムでも、バージョン管理システム(git など)を使用してソースコードを管理する必要があるでしょう。そのほかにも検討すべき点がいくつかあります。
コードの再利用
Kubeflow Pipelines は基本的にモジュール型のため、各コンポーネントの再利用によって ML パイプライン開発にかかる時間を短縮できます。既存のコンポーネントはすべて Google Cloud ライブラリと KFP ライブラリでご覧いただけます。
KFP のカスタム コンポーネントを作成する場合は、必ず組織と共有してください。バージョン管理や参照が簡単にできるよう、別のリポジトリに移動することをおすすめします。またはオープンソース コミュニティにぜひ公開してください。Google Cloud ライブラリと Kubeflow Pipelines プロジェクトはいずれも、新規または改良したパイプライン コンポーネントによる貢献を歓迎します。
テスト
どんな本番環境システムでも、特に後で変更を加えた場合には、システムの信頼性を確保するために自動テストの設定をおすすめします。pull リクエスト(PR)を開くときは必ず、CI パイプラインを使用してカスタム コンポーネントの単体テストを実行します。ML パイプラインのエンドツーエンド テストには時間がかかるため、PR を開く(または開いた PR に次の commit を push する)たびにテストを実行するよう設定することはおすすめしません。開いた PR でそのようなテストを実行するときには手動での承認を必要とするか、デプロイするコードを専用のテスト環境にマージした場合のみ実行してください。
ステップ 2: パイプラインをコンパイルする
他のソフトウェア システムと同様、ML パイプラインをコンパイルするときは CI / CD パイプライン(Google Cloud Build など)を使用し、必要に応じて KFP または TFX ライブラリを使用します。ML パイプラインをコンパイルした後、コンパイルしたパイプラインを環境(テスト/本番)に公開します。Vertex AI SDK では、Google Cloud Storage(GCS)に保存したコンパイル済みのパイプラインを参照できるため、GCS は CD パイプラインの最後にコンパイル済みのパイプラインを公開するのに最適な場所となります。またはコンパイルしたパイプラインを Artifact Registry に Vertex AI Pipeline テンプレートとして公開してもかまいません。
pull リクエスト チェック(CI)の一環として ML パイプラインをコンパイルするのもよいでしょう。短時間でコンパイルできるため、パイプラインに構文エラーがないか簡単にチェックできます。
ステップ 3: コンパイルしたパイプラインを Vertex AI API に送信する
ML パイプラインを送信して Vertex で実行するには Google Cloud Vertex AI SDK(Python)を使用する必要があります。そしてコンパイル済みの ML パイプラインを CI / CD の一部として実行するには、Python ML パイプラインとコンパイル コードを Vertex AI SDK を使用する「トリガー」コードと分離する必要があります。
「トリガー」コードを、固定スケジュールで(ML モデルを毎週再トレーニングしたい場合など)、あるいは所定のイベント(BigQuery に新しいデータが到着したときなど)があったときに実行するのもおすすめです。Cloud Build でも Cloud Functions でもこれは可能であり、どちらの方法にも利点があります。すでに CI / CD パイプラインに Cloud Build を使用している場合は Cloud Build を使用したいかもしれませんが、その場合は「トリガー」コードを入れるコンテナを自分でビルドする必要があります。Cloud Function ならコード自体をデプロイするだけで、GCP が Cloud Function にパッケージ化してくれます。
どちらも固定スケジュール(Cloud Scheduler + Pub/Sub)で、または Pub/Sub イベントからトリガーできます。Cloud Build のほうが Cloud Build トリガー内で変数置換を使用して Pub/Sub イベントを解釈できるため、イベントからのトリガーに柔軟性があります。Python コードで Pub/Sub イベントを解釈する必要はありません。この場合、さまざまな Cloud Build トリガーを設定し、同じ Python コードで異なるイベントに対応して ML パイプラインを開始できます。
単に Vertex AI パイプラインをスケジュールしたい場合は、Cloud Function や他の「トリガー」コードを使わず、Datatonic のオープンソース Terraform モジュールで Cloud Scheduler のジョブを作成することも可能です。
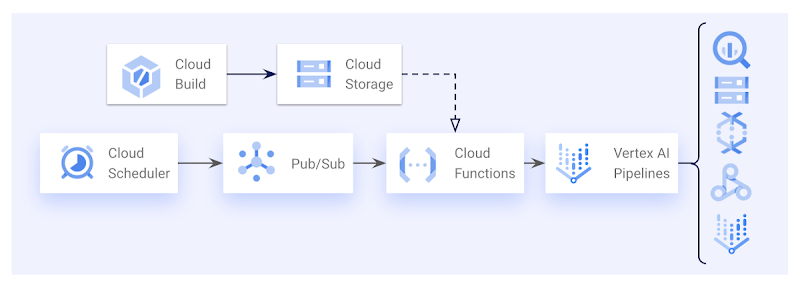
Cloud Scheduler、Pub/Sub、Cloud Function を使用し、スケジュールに応じて Vertex AI Pipelines をトリガーするアーキテクチャの例。
Vertex AI クイックスタート テンプレートのご紹介
Datatonic は、Google の Vertex AI プロダクト チームとのパートナーシップにより、AI のユースケースを Vertex AI Pipelines で本番環境に移行するためのオープンソース テンプレートを開発しました。これには以下が含まれます。
XGBoost と Tensorflow のフレームワーク(フレームワークはさらに追加予定)を使用し、トレーニングとバッチ スコアリングに対応する ML パイプラインの例
KFP コンポーネントの単体テストを実行する CI / CD パイプライン(Google Cloud Build を使用)、エンドツーエンドのパイプライン テスト、ML パイプラインのコンパイルと環境への公開
Google Cloud Function として簡単にデプロイできるパイプライン トリガー コード
Terraform を使用し、Infrastructure-as-Code としてデプロイするコードの例
開発サイクルの時間を短縮するメイク スクリプト
このテンプレートは、新しい ML のユースケースを概念実証(POC)から本番運用に導くコードベースの出発点となります。13 を超える国の何百人ものデータ サイエンティストが概念実証(POC)から本番運用までの期間を 5 か月から 4 週間に短縮した、Vodafone によるテンプレートの使用事例をご覧ください。まずは、GitHub のリポジトリを確認し、README の説明をお読みください。
Vertex AI が初めてで、もっと詳しく知りたい方は、以下のリソースをご利用いただけます。
最後に、皆様のフィードバックをお待ちしています。Vertex AI に関するフィードバックがございましたら、Vertex AI サポート ページからお寄せください。パイプライン テンプレートに関するフィードバックがございましたら、GitHub リポジトリに問題を提出してください。本ブログ投稿に関するご意見も大歓迎です。
このたびの機会をくれた Sara Robinson に心より感謝します。
- カスタマー エンジニア Ivan Nardini- Datatonic、プリンシパル MLOps エンジニア Jonny Browning





