Cloud Vision API と BigQuery で Vertex AI テキスト データセットのアノテーション付けを自動化

Google Cloud Japan Team
※この投稿は米国時間 2022 年 6 月 14 日に、Google Cloud blog に投稿されたものの抄訳です。
機械学習実務担当者が直面する主な課題の一つは、アノテーション付きトレーニング データセットが利用可能かどうかです。多くの場合、実務担当者は手動で抽出された既存のデータセットにアクセスし、それを使用してモデルのトレーニングを高速化できます。
この投稿では、特許出願 PDF のテキスト エンティティ抽出モデルのトレーニングに Google Cloud の人工知能(AI)/ 機械学習(ML)プロダクトを使用する方法について説明します。BigQuery、Vision API、Jupyter ノートブックを使用して、モデルのトレーニングに使用する既存のデータセットにアノテーションを自動的に付けます。各ステップの詳細については説明しませんが、こちらの Jupyter ノートブックで完全なバージョンを確認できます。これは Vertex AI Samples GitHub リポジトリの一部としてリリースされたものです。
サンプル データセット
この例で使用するデータセットは、BigQuery の一般公開データセットの Patent PDF Samples with Extracted Structured Data です。このデータセットには、Google Cloud Storage に保存された米国と EU の特許の一部を記載した最初のページの PDF へのリンクとともに、出願番号、特許発明者、公開日など、複数の特許エンティティのラベルが含まれています。これは次のステップで使用するのに理想的なデータセットです。
Cloud Vision API を使用した PDF ドキュメントの前処理
現在、Vertex AI AutoML エンティティ抽出機能は、トレーニング データセットのテキストデータのみをサポートしています。PDF ファイルを使用するための最初のステップは、PDF ファイルをテキスト形式に変換することです。Cloud Vision API には、光学式文字認識(OCR)で PDF ファイルと TIFF ファイルのテキストを検出して抽出するテキスト検出機能があります。バッチ オペレーション モードがあるので、一度に複数のファイルを処理できます。
トレーニング データセットの準備
Vertex AI には、トレーニング データセットをアップロードする方法が複数あります。この場合に最も便利なのは、インポート ファイルを使用してインポート プロセスにアノテーションを含める方法です。インポート ファイルでは、特定の形式に従って、内容と、トレーニング対象の各ラベルのアノテーションのリストを指定します。
アノテーションを生成するために、BigQuery に保存された既存のデータに対してクエリを実行し、各ファイルの抽出エンティティの場所を見つけます。あるエンティティがテキスト内に複数回出現する場合、そのすべてがアノテーションに含まれます。その後、JSON Lines 形式のアノテーションを Google Cloud Storage のファイルにエクスポートし、そのファイルをモデルのトレーニングで使用します。Google Cloud コンソールでアノテーション付きデータセットを見直して、アノテーションが正確かどうかを確認することもできます。
モデルのトレーニング
インポート ファイルの準備ができたら、Vertex AI で新しいテキスト データセットを作成し、そのデータセットを使用して新しいエンティティ抽出モデルをトレーニングできます。数時間で、モデルはデプロイとテストができる状態になります。
モデルの評価
モデルのトレーニングが完了すると、Google Cloud コンソールでモデルの評価結果を確認できます。Vertex AI AutoML モデルの評価方法の詳細については、こちらをクリックしてください。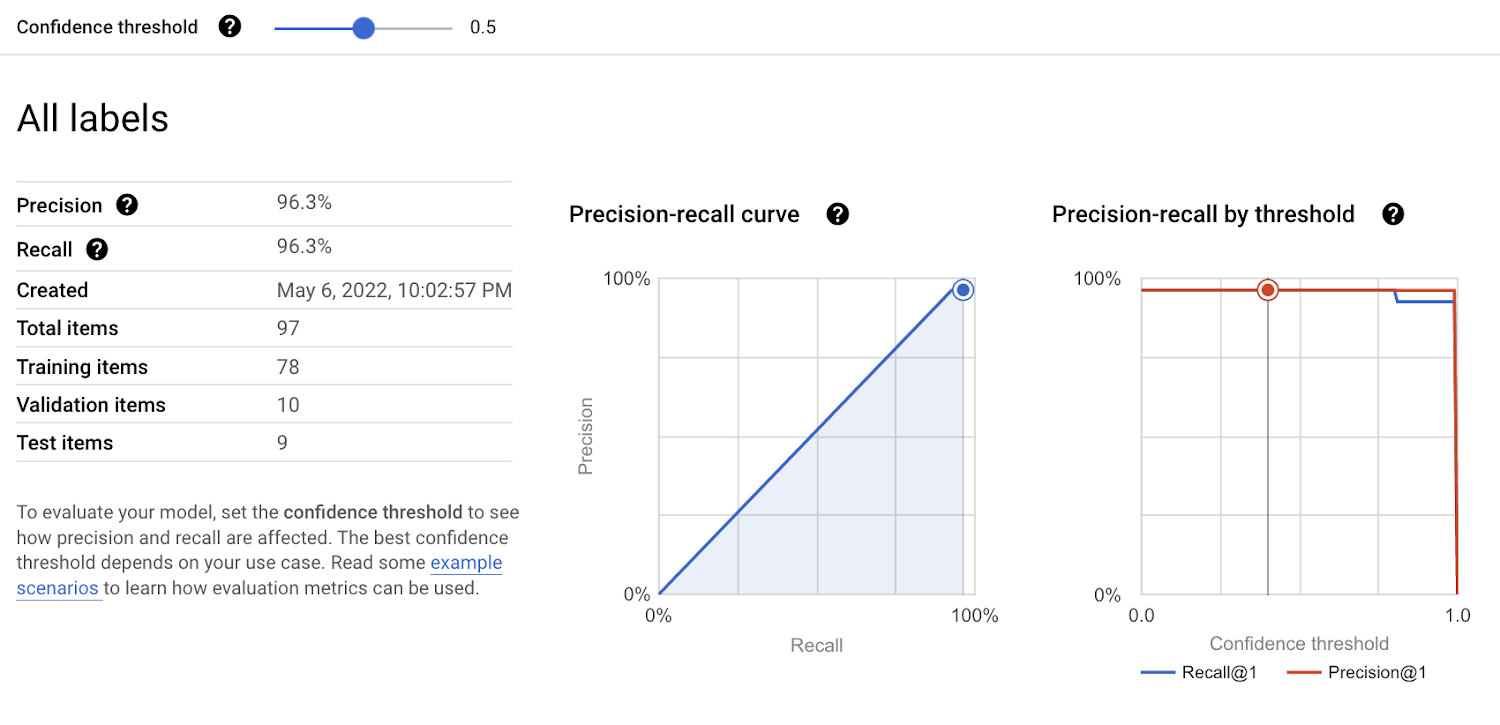
すべてを組み合わせる
下の図は、ソリューション全体の構築に使用するさまざまなコンポーネントと、それらの相互関係を示しています。
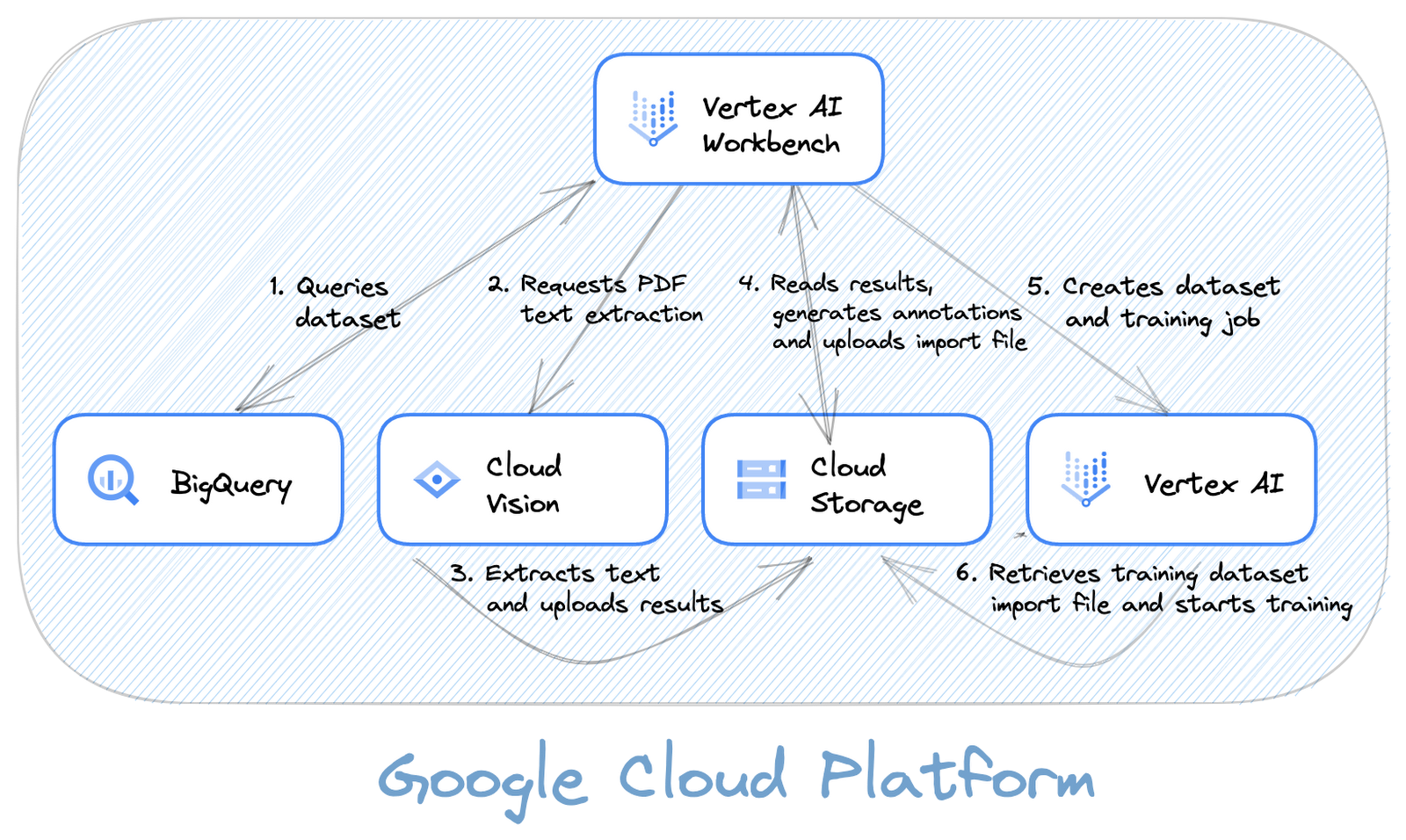
注: この図は無料の Google Cloud Architecture Diagramming Tool で作成しました。このツールを使用すると、Google Cloud アーキテクチャを簡単に文書化できます。ぜひこのツールをチェックして、ご自分のプロジェクトで使用してみてください。
まとめ
この投稿では、BigQuery と Vision API を使用してグラウンド トゥルース データにアノテーションを付け、Vertex AI テキスト エンティティ抽出モデルをトレーニングする方法について説明しました。この方法を使用することで、このソリューションを複製し、既存のデータセットを活用して AI / ML のプロセスを高速化することが簡単になります。
次のステップ
このソリューションは、こちらの Jupyter ノートブックを使用して試してみることができます。このノートブックは、ご利用のマシンで、Colab または Vertex AI Workbench から実行できます。Vertex AI Samples GitHub リポジトリにアクセスして、Google Cloud Vertex AI を使用した機械学習ワークフローの開発と管理の他の例を確認することもできます。
Google Cloud が提供する他の ML 実務担当者向け最新ツールについては、第 2 回 Google Cloud Applied ML Summit の録画をご視聴ください。最新のプロダクトのお知らせ、エキスパートからのインサイト、イノベーションのスピードに後れを取らないスキルアップに役立つ導入事例をご確認いただけます。
皆様の機械学習のプロセスが順調に進むことを願っています。
この投稿の内容の確認を手伝ってくれた Karl Weinmeister、Andrew Ferlitsch、Daniel Wang、編集をサポートしてくれた Terrie Pugh に心から感謝します。とても助かりました!
- インフラストラクチャ モダナイゼーション(GCloud カスタマー)担当カスタマー エンジニア Mohammad Al-Ansari



