Automate annotations for Vertex AI text datasets with Cloud Vision API and BigQuery

Mohammad Al-Ansari
Customer Engineer, Infrastructure Modernization (GCloud Customers)
Automate Vertex AI entity extraction dataset annotations with Cloud Vision API and BigQuery
One of the main challenges machine learning practitioners face is the availability of annotated training datasets or a lack thereof. In many cases, practitioners may have access to existing datasets that have been manually extracted, which they can use to accelerate their model training.
In this post, we demonstrate how Google Cloud AI/ML products can be used to train a text entity extraction model for patent application PDFs. We use BigQuery, Vision API, and Jupyter Notebook to automatically annotate an existing dataset used for model training. Although we won’t go into the details of each step, you can check the complete version in this Jupyter Notebook, which is released as part of the Vertex AI Samples GitHub repository.
The sample dataset
The dataset used in this example is the Patent PDF Samples with Extracted Structured Data from the BigQuery public datasets. It contains links to PDFs from the first page of a subset of US and EU patents stored in Google Cloud Storage. The dataset also contains labels for multiple patent entities including the application number, patent inventor, and publication date. This provides the ideal dataset to use for our next step.
Preprocessing PDF documents using Cloud Vision API
Today, Vertex AI AutoML entity extraction supports only text data for training datasets. Our first step in using the PDF files is to convert them to text format. Cloud Vision API offers a text detection feature that uses Optical Character Recognition (OCR) to detect and extract text out of PDF and TIFF files. It offers a batch operation mode that allows us to process multiple files at once.
Preparing the training dataset
Vertex AI offers multiple ways to upload our training dataset. The most convenient choice in our case is to include annotations as part of the import process using an import file. The import file follows a specific format that specifies the content and the list of annotations for each label we want to train.
To generate the annotations, we are going to query the existing data stored in BigQuery and find the location of extracted entities in each file. If an entity has multiple occurrences in the text, all of the occurrences are included in the annotations. We will then export the annotations in JSON Lines format to a file in Google Cloud Storage and use that file in our model training. We can also review the annotated dataset in the Google Cloud Console to ensure the accuracy of the annotations.
Training the model
Once the import file is ready, we can then create a new text dataset in Vertex AI, and use that dataset to train a new entity extraction model. In a few hours, a model is ready for deployment and testing.
Evaluating the model
Once the model training is completed, you can review the model’s evaluation results in the Google Cloud Console. Click here to learn more about how to evaluate Vertex AI AutoML models.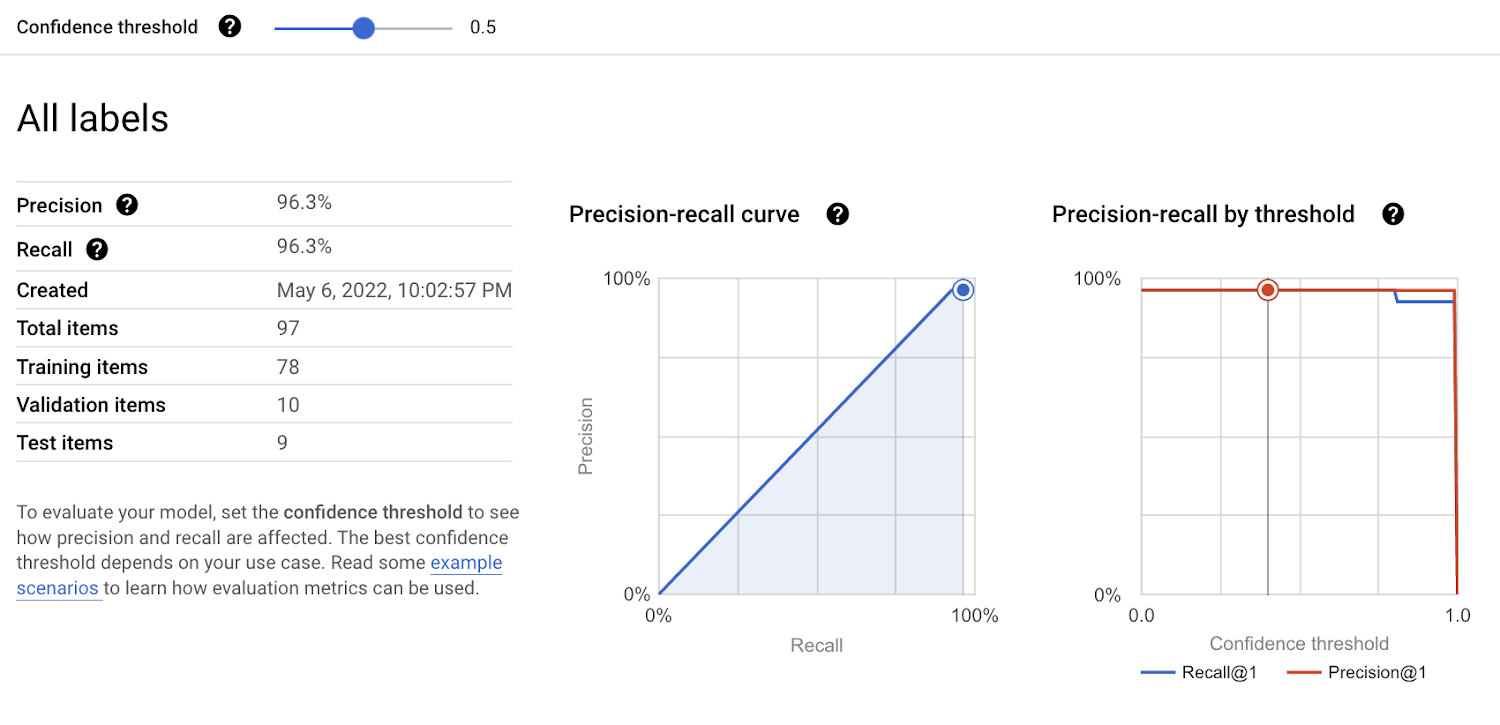
Putting it all together
The diagram below shows the various components used to build the complete solution and how they interact with each other.
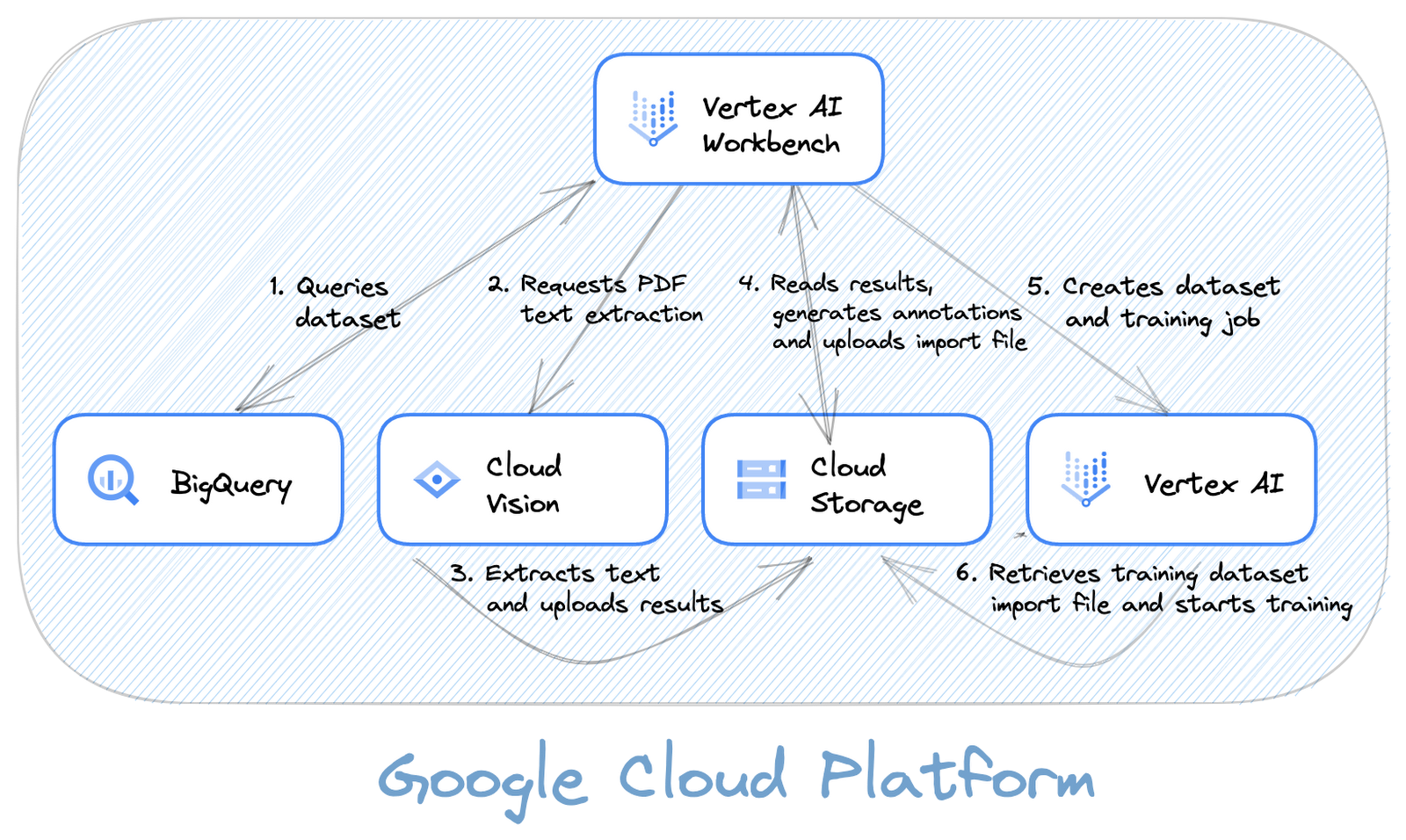
Note: This diagram was created using the free Google Cloud Architecture Diagramming Tool, which makes it easy to document your Google Cloud architecture. Check it out and begin using it for your own project!
Summary
In this post, we've learned how to train a Vertex AI text entity extraction model by using BigQuery and Vision API to annotate ground truth data. By using this approach, it is easier for you to replicate this solution and leverage existing datasets to accelerate your AI/ML journey.
Next Steps
You can try this solution by using this Jupyter Notebook. You can run this notebook on your machine, in Colab or in Vertex AI Workbench. You can also check out the Vertex AI Samples GitHub repository for more examples on developing and managing machine learning workflows using Google Cloud Vertex AI.
And if you’d like to review more of the latest tool set from Google Cloud for ML practitioners, you can watch recordings of the second Google Cloud Applied ML Summit. Catch up on the latest product announcements, insights from experts, and customer stories that can help you grow your skills at the pace of innovation.
We wish you a happy machine learning journey!
Special thanks to Karl Weinmeister, Andrew Ferlitsch and Daniel Wang for their help in reviewing this post’s content, and to Terrie Pugh for her editorial support. You rock!



