VM のモニタリングとトラブルシューティングを「コンテキスト内」で行い、問題を迅速に解決
Google Cloud Japan Team
※この投稿は米国時間 2021 年 8 月 13 日に、Google Cloud blog に投稿されたものの抄訳です。
本番環境の仮想マシン(VM)で問題が発生した場合、そのトラブルシューティングは複雑になりがちであり、多くの場合、インフラストラクチャ、アプリケーション指標、未加工のログなど、複数のデータポイントやシグナルを関連付けることが必要になります。さらに、エンドユーザーがレイテンシ、ダウンタイム、エラーなどの問題に直面し、デベロッパーがその問題の根本原因を分析する場合、さまざまなツールや UI などを切り替えなくてはならず、分析作業が遅れてしまうこともあります。必要なデータへのアクセス、修正のデプロイ、修正の検証など、各作業の時間を短縮することで、組織はコストを削減し、ユーザーからの信頼を維持できます。
本日は、Compute Engineの UI ベースのツールである「コンテキスト内」セットの一般提供を発表いたします。この強化されたセットを使用することで、Compute Engine のユーザーはトラブルシューティングをより簡単かつ直感的に行えるようになります。デベロッパーは、Google Console から任意の VM をクリックして、事前構築済みの豊富な可視化機能にアクセスできます。この機能により、CPU、ディスク、メモリ、ネットワーク、ライブプロセスに関連する一般的なシナリオや問題を分析できます。これらすべてのデータに 1 つのロケーションからアクセスできるため、一定の期間内のシグナルを簡単に関連付けることができます。
より多くの運用データを VM に取り込む
上位レベルの指標のコレクションは Compute Engine コンソールのページでいつでも利用できます。しかし、お客様のフィードバックにより、それでも各種ツール間を移動しないと根本原因を適切に分析できないことがわかりました。たとえば、CPU 使用率が特定の時間帯にピークを迎えていることを確認するのは足がかりになるかもしれませんが、使用率を押し上げている原因は何であるかをもっと深く分析しないと問題の解決には至りません。さらに、このデータをプロセスや、入出力の待機時間、ユーザー空間、カーネル空間などのシグナルと関連付ける必要があります。
このことを念頭に置いて、Google は Compute Engine ページにさまざまな指標、チャート、可視化機能を新たに追加しました。これらのほとんどは設定に時間が一切かかりません。新しく追加された一部の機能には、Google Cloud の Ops エージェント(または現在使用している従来のエージェント)から提供される詳細な指標が入力されます。Ops エージェントは、Terraform、Puppet、Ansible、インストール スクリプトを使用して簡単にインストールできます。
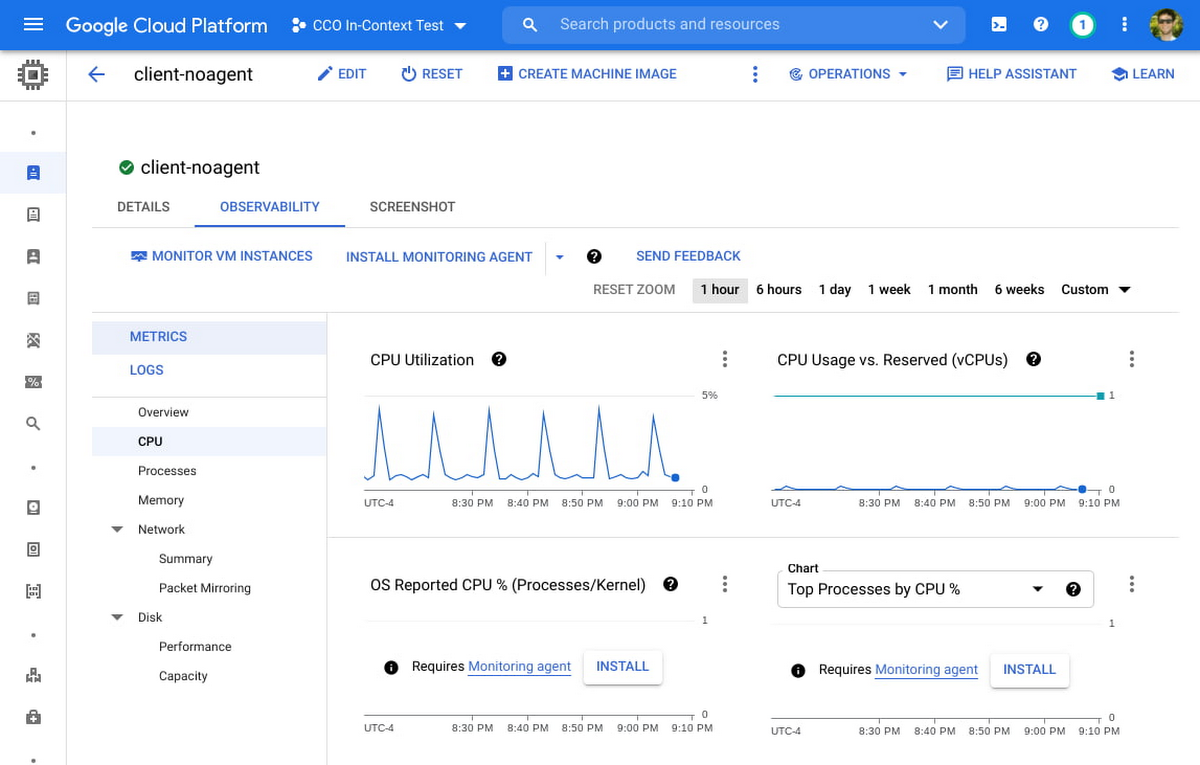
Ops エージェントの指標を利用する新しいチャートには、OS から報告される CPU 使用率、メモリ使用率、ユーザー別のメモリ内訳、カーネル、ディスク キャッシュ、I/O レイテンシ、ディスク使用率、キューの長さ、プロセス指標などが含まれます。
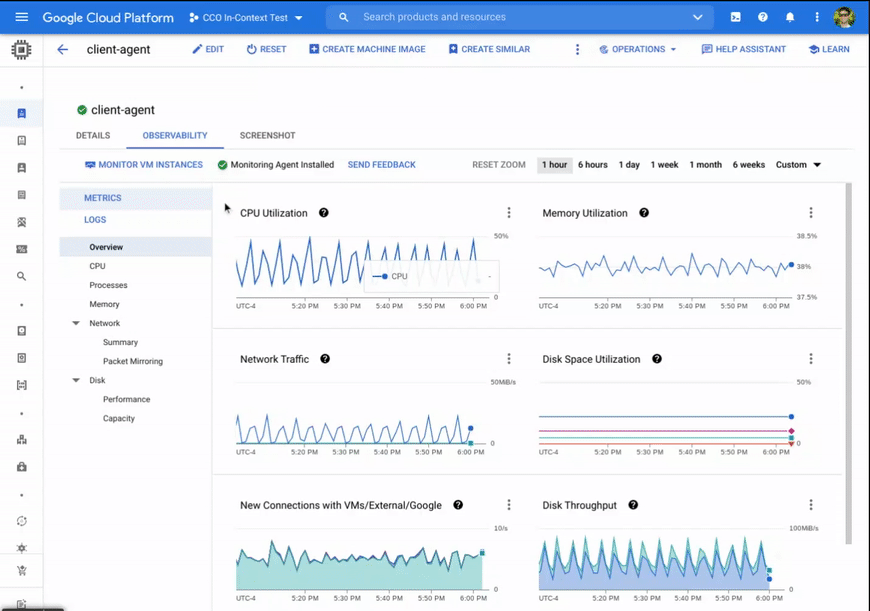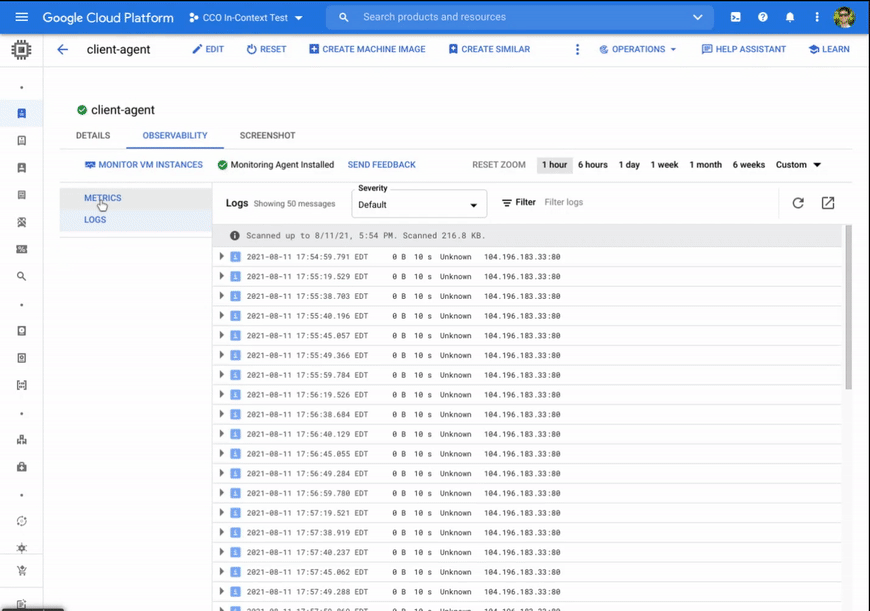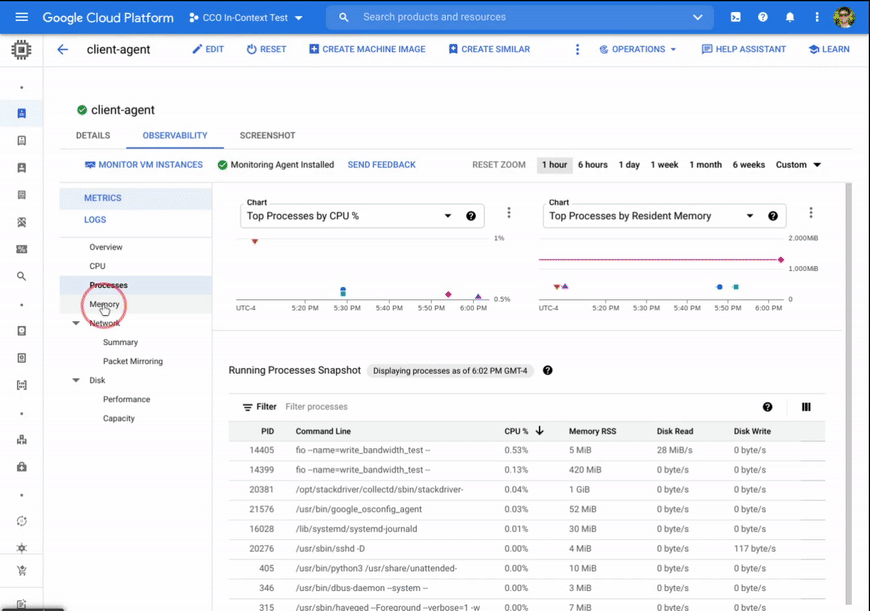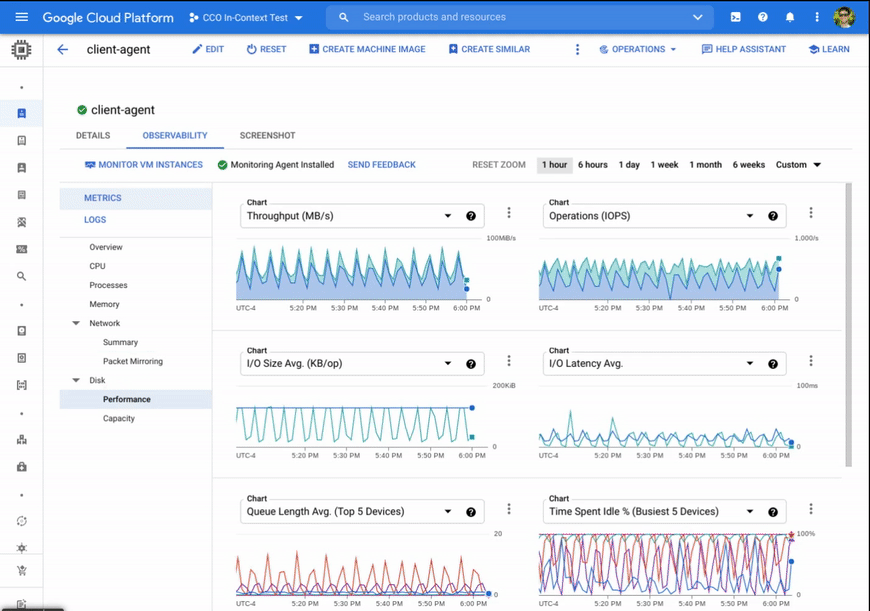
あらゆるニーズにたった一つで対応できるようなトラブルシューティングはありませんが、この強化されたオブザーバビリティ ツールのセットを使用することで、以下のシナリオをより迅速かつ直感的に実行できます。
指標とログでネットワークの変化を特定する。ネットワーク トラフィック内の予期しない増加、ネットワークのパケットサイズ、新規ネットワーク接続の急増を重要度別にログと比較することで、デベロッパーはトラフィックの増加と重大なログエラーの関連性を特定できます。さらにツールのログのセクションに移動すると、重要なログだけをすばやくフィルタし、ログメッセージのサンプルを開いて、タイムアウト メッセージや負荷の増加によるエラーに関する詳細なログを確認できます。また、対象の VM のみにフィルタしたログ エクスプローラへのディープリンクによって、Compute Engine と Cloud Logging の間を迅速かつシームレスに移動できます。
使用率に影響を与えるプロセスを特定する: CPU やメモリの使用率が高い時間と上位のプロセスを比較することで、オペレーターはどのプロセスがリソースを大幅に消費しているかを特定できます(プロセスはコマンドラインまたは PID で表示)。特定したプロセスは、完全にリファクタリングまたは停止するか、コンピューティングやメモリの要件により適したマシンで実行するという方法で対処できます。その他にも、継続時間が短いプロセスが数多く存在する場合があります。そういったプロセスは、プロセス スナップショットには表示されませんが、プロセス作成レートのチャートにはレートの急増という形で示されます。そのため、プロセス作成レートのチャートを確認することで、リファクタリングを行いプロセス継続時間をより効率的に分配するという判断を行えるようになります。
ワークロードに適したディスクサイズを選択する: 「1 秒あたりの IOPS のピーク値」が横ばいになり始めていることにデベロッパーが気付くことがあります。これはディスクがパフォーマンスの上限に達しつつあるサインです。また、「I/O レイテンシの平均」が増加している場合、I/O スロットリングが発生している可能性があります。最終的に、ストレージ タイプ別に IOPS のピーク値を分析すると、ほとんどの IOPS ピークが Persistent Disk SSD で発生していることがわかるかもしれません。こうした分析により、ディスクのサイズを増やし、ブロック ストレージのパフォーマンス上限を引き上げるという判断を行えるようになります。
セキュリティ運用とデータ主権: オペレーターは業務の一環として、外部データアクセスに対してセキュリティ プロトコルを適用したり、特定のリージョンにデータを保存してプライバシーや規制に遵守するために技術的なアーキテクチャを作成したりすることがあります。オペレーターは、ネットワーク サマリーを使用して、VM で接続が確立され、主に同一のプロジェクト内の VM および Google サービスにトラフィックが送信されているか、接続および上り / 下り(内向き / 外向き)のトラフィックが外部で発生している可能性があるかどうかを一目で判断できます。同様に、新しい接続が確立されているか、もしくはトラフィックが異なるリージョンやゾーンに送信されているかも判断できます。これにより、リージョン間のデータ転送をブロックする新しいプロトコルを作成するという判断もできます。
ネットワークの変更によりコストを最適化する: デベロッパーは、VM 間のトラフィックの大部分が同じリージョン内のトラフィックではなくリージョン間で送信されていることに気がつくかもしれません。このリージョン間のトラフィックは低速で、リージョン間のレートに基づいて課金されるため、デベロッパーは VM を再構成し、代わりに同じリージョン内の必要なデータのローカル レプリカと通信する方法を選択できます。これにより、レイテンシとコストの両方を抑えられます。
メモリのパフォーマンスを測定、調整する: メモリ使用率のデータを集めるために、ほとんどの VM ファミリーで Ops エージェントが必要とされます。上位のプロセスを対象にメモリ使用量を調査することで、デベロッパーはメモリリークを検出して、問題のあるプロセスを再構成または終了できます。さらに、メモリ使用量のタイプ別の内訳を調査すると、ディスク キャッシュ使用量がアプリケーションで使用されていないメモリ領域の使用量の上限に達しており、それがディスク レイテンシの増加と関連していることに気付くことがあるかもしれません。これにより、オペレーターはメモリ最適化 VM にアップサイズすることを選択でき、アプリケーションとディスク キャッシュの両方で十分なメモリを使用できます。
ここで紹介したものは、お客様のチームが新機能を活用できるユースケースのほんの一例です。これらを活用することで、トラブルシューティングにかかる時間を短縮し、コストを最適化して、Compute Engine の全体的なエクスペリエンスを向上できます。
使ってみる
開始するには、[Compute Engine] > [VM インスタンス] の順に移動し、対象の VM をクリックしてから [オブザーバビリティ] タブに移動します。これらのツールを使用して VM パフォーマンスに関する問題のトラブルシューティングを行う方法の詳細については、デベロッパー向けドキュメントで確認できます。また、新しいツールを最大限に活用するために Compute Engine VM にOps エージェントをインストールすることをおすすめします。何かご不明な点やフィードバックがございましたら、Google Cloud コミュニティの Cloud Operations ページのディスカッションにご参加ください。
-シニア プロダクト マネージャー Haskell Garon
-ソフトウェア エンジニア Dave Raffensberger


