Google の Vertex AI Vizier を使用したアプリケーションの最適化
Google Cloud Japan Team
※この投稿は米国時間 2022 年 1 月 27 日に、Google Cloud blog に投稿されたものの抄訳です。
世界中の企業は、人工知能(AI)や機械学習(ML)のイノベーションの恩恵を受け続けています。F5 では、データ セキュリティ、不正行為の検出、bot 攻撃防止などの質を向上させるために、AI / ML を有効に活用しています。このようなビジネス プロセスにおける AI / ML のメリットは明確で、さらに F5 では、ソフトウェア アプリケーションの最適化にも AI / ML を活用しています。
より良いソフトウェア エンジニアリングに向けた AI / ML の活用は、まだ始まったばかりです。AI 支援によるコード補完、ノーコード / ローコード型プラットフォームの自動コード生成といったユースケースは見られますが、ソフトウェア アプリケーションのアーキテクチャ自体の最適化に対して AI / ML の幅広い活用は行われていません。このブログでは、Google の Vertex AI Vizier を用いたブラックボックス最適化によるデータ パイプラインのワークロードの最適化について説明します。
パフォーマンスの最適化
現在、ソフトウェアの最適化は、ソフトウェア コードにおけるパフォーマンスのボトルネックを特定するためにプロファイラを使用して行う、反復的なほぼ手動のプロセスです。プロファイラは、ソフトウェアのパフォーマンスを測定してレポートを生成し、デベロッパーはそれを確認してコードをさらに最適化します。この手動によるアプローチの欠点は、最適化がデベロッパーの経験に委ねられ、そのため非常に主観的であるという点です。手動によるアプローチは時間がかかり、包括的ではなく、エラーが発生しがちで、人間のバイアスに影響されやすいものです。さらに、クラウド ネイティブ アプリケーションの分散性により、手動による最適化プロセスはさらに複雑なものとなっています。
あまり使用されていませんが、より包括的なアプローチとして、パフォーマンス テストとブラックボックス最適化のアルゴリズムを利用する別のタイプのパフォーマンス エンジニアリングがあります。具体的には、多くのパラメータを持つ複雑なシステムの運用コストを最適化することを目指しています。因果関係のプロファイリングなど、テストベースのパフォーマンスを最適化する手法は他にもありますが、この投稿では扱いません。
図 1 に示すように、パフォーマンスを最適化するためのプロセスは、反復的で自動化されています。一連の制御された試行をシステムに対して行い、最適化されるシステムを特徴づける費用関数の値を検討します。新たなパラメータの候補が生成され、改善点が少なすぎて試行を行う価値がなくなるまで行われます。このプロセスの詳細は後ほど説明します。
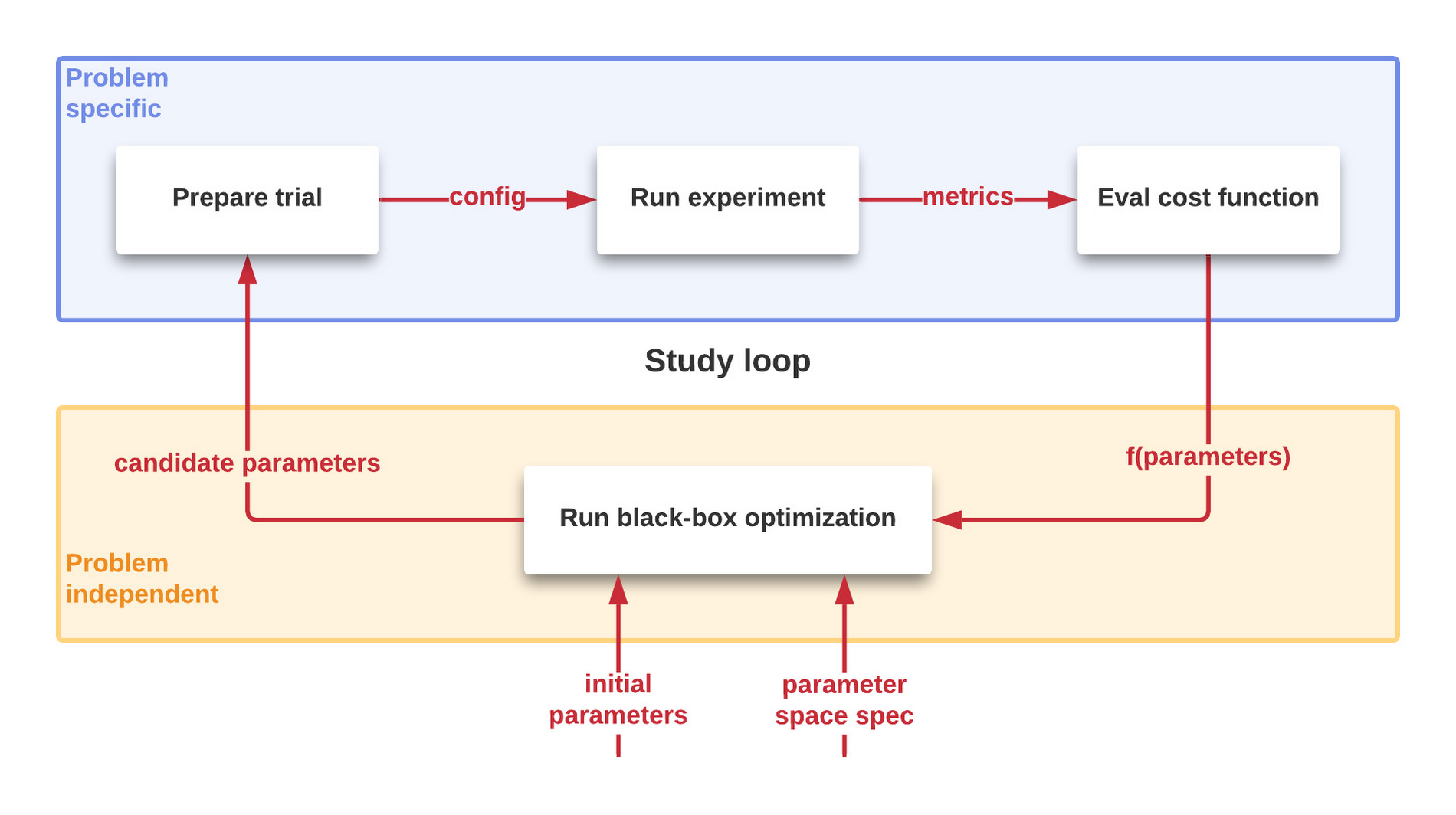
問題は何ですか?
まず、経験から得たヒントを活用し、このディスカッションを行うための架空のステージを設定しましょう。
目標は、Pub/Sub から BigQuery にデータを取得する効率的な方法を構築することです。Google Cloud は、フルマネージドのデータ処理サービスである Dataflow を提供しています。これは他の複数のリアルタイム ストリーミングのニーズに使用するさまざまなデータ処理パターンを実行します。処理と変換のこのユースケースでは、簡略化されたカスタム ストリーム プロセッサを活用して、BQ の「列」指向(一種の「E(t)LT」モデル)のメリットを受ける選択をしました。
調査の設定を図 2 に詳しく示します。中央にあるノートブックは、「最適化の対象となるシステム」を調査するためのオーケストレーターの役割を担っています。主な目標(および関係するコンポーネント)は以下の通りです。
再現性: プロセスの自動化に加えて、Pub/Sub スナップショットを使用して、ストリーム プロセッサにフィードするために特別に作成されたサブスクリプションを初期化し、各テストで同じ条件を再現します。
スケーラビリティ: Vertex AI Workbench は、最適化プロセス全体を迅速に行うため、異なる入力パラメータで複数のテストを並行して行う一連の自動化された手順を実装しています。
デバッグ可能性: すべてのテストにおいて、調査および試行の ID は、ストリーム プロセッサによって生成される各ログおよび指標のラベルとして体系的に挿入されます。こうすることでテストが失敗したときや、予期しない結果が出たときに、その原因を簡単に突き止め、分析し、把握できます。
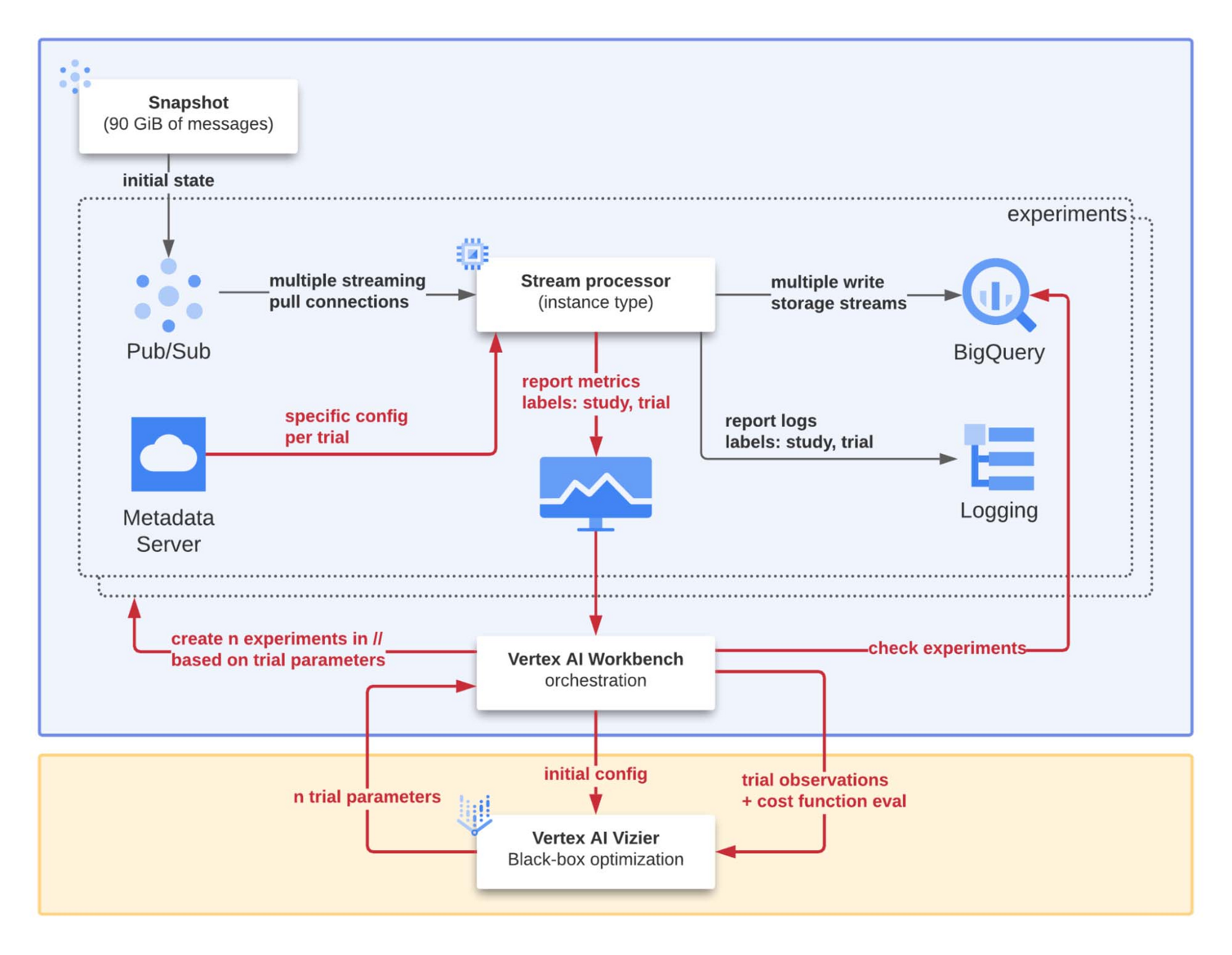
Pub/Sub から BigQuery へ効率的にデータを移動させるために、当社はコードを設計、開発しました。そして、可能な限り効率を高めるように改良したいと思っています。当社が所有するプログラムを実行することで簡単にキャプチャできるパフォーマンス指標に基づいて最適化したいと考えているのです。現在の課題は、最良のバリアントをどのように選択するかということです。
当然のことながら、これは最適化問題の一つです。最適化にはこの問題がつきものです。基本的にこれらの問題は、いくつかの制約下で目的関数を最適化(最小化または最大化)し、それが実現する最小値または最大値を求めるものです。これは、その広範にわたる適用範囲から、広く調査されてきた分野です。
一般的な形式は:
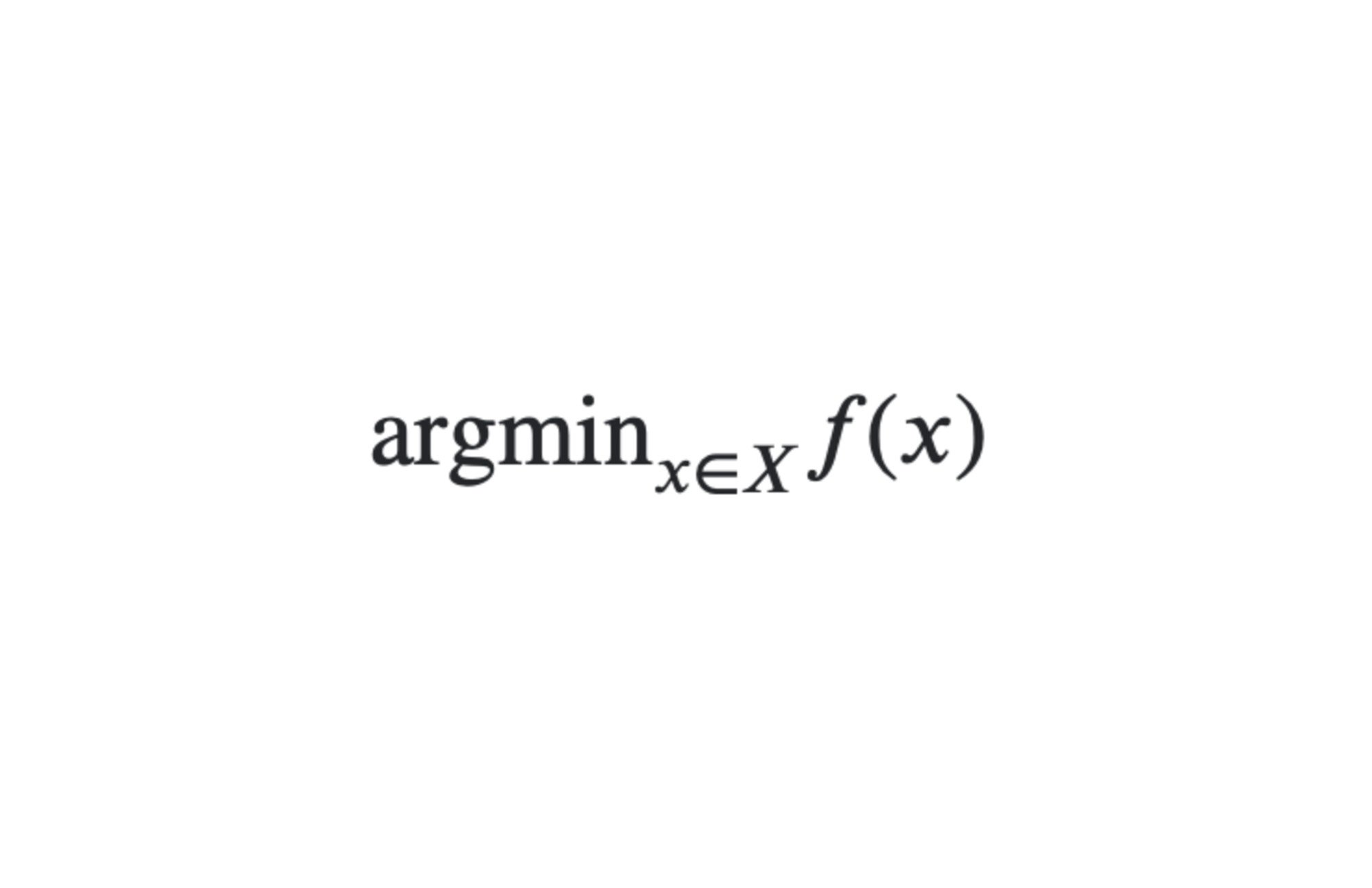
- これは、あるドメイン X の費用関数 f を最小化する x を求めたいという意味です。ここでは最小化の問題なので、この x を最小値と呼びます。最小値は必ず存在するとは限りませんし、存在する場合でも必ずしも一意ではありません。最適化問題はすべて同じではありません。連続および線形計画法は「簡単」で、凸最適化は比較的簡単ですが、組み合わせ最適化は難しくなります。これは、勾配を計算できる場合と同じように、部分的にでも最適化したい目的関数を記述できることが前提です。
今回のケースの目的関数は、ある実行環境におけるプログラムのパフォーマンス(この時点ではまだ未定)です。これは f(x)=x2 とはかけ離れています。プログラムのパフォーマンスの分析式もなく、導関数もなく、関数が凸である保証もなく、評価にはコストがかかり、モニタリングにはノイズが入る可能性があります。このタイプの最適化は、目的関数をシンプルな数学用語で表現できないことから、「ブラックボックス最適化」と呼ばれています。とはいえ、最良の結果をもたらすパラメータの発見に対する関心は大きなものです。
このタイプの問題を手動で解決するのではなく、自動化する方法を探しているため、ブラックボックス最適化といくつかのツールの詳細を紹介する前に、現在の状況を具体的な最適化の問題に当てはめてみましょう。ことわざにもあるように「時は金なり」です。
最適化問題のフレーミング
問題には多くの変動要素がありますが、すべてが同じ性質ではありません。
目標
まず、目標です。今回のケースでは、Pub/Sub から BigQuery にデータを移動する際の 1 バイトあたりのコストを最小にするのが目標です。システムによって対象のドメインで直線的にスケーリングされると仮定すると、バイトあたりの処理コストはインスタンス数に依存せず、定義されたスループットに到達するためのコストを正確に推定できます。
実現方法
ある特定の実行環境(特定のマシンタイプ、ロケーション、プログラムの構成を考慮する)において、重要かつ既知の大量のデータに対してプログラムを実行し、処理にかかる時間を測定して、リソースのコストを計算します(以下で 「cost_dollar」と呼ばれる)。これが費用関数 f です。
前述したように、このシステムの費用関数を定義するシンプルな数式はなく、評価するには実際にプログラムを実行する必要があるため「コストがかかる」のです。
パラメータ空間
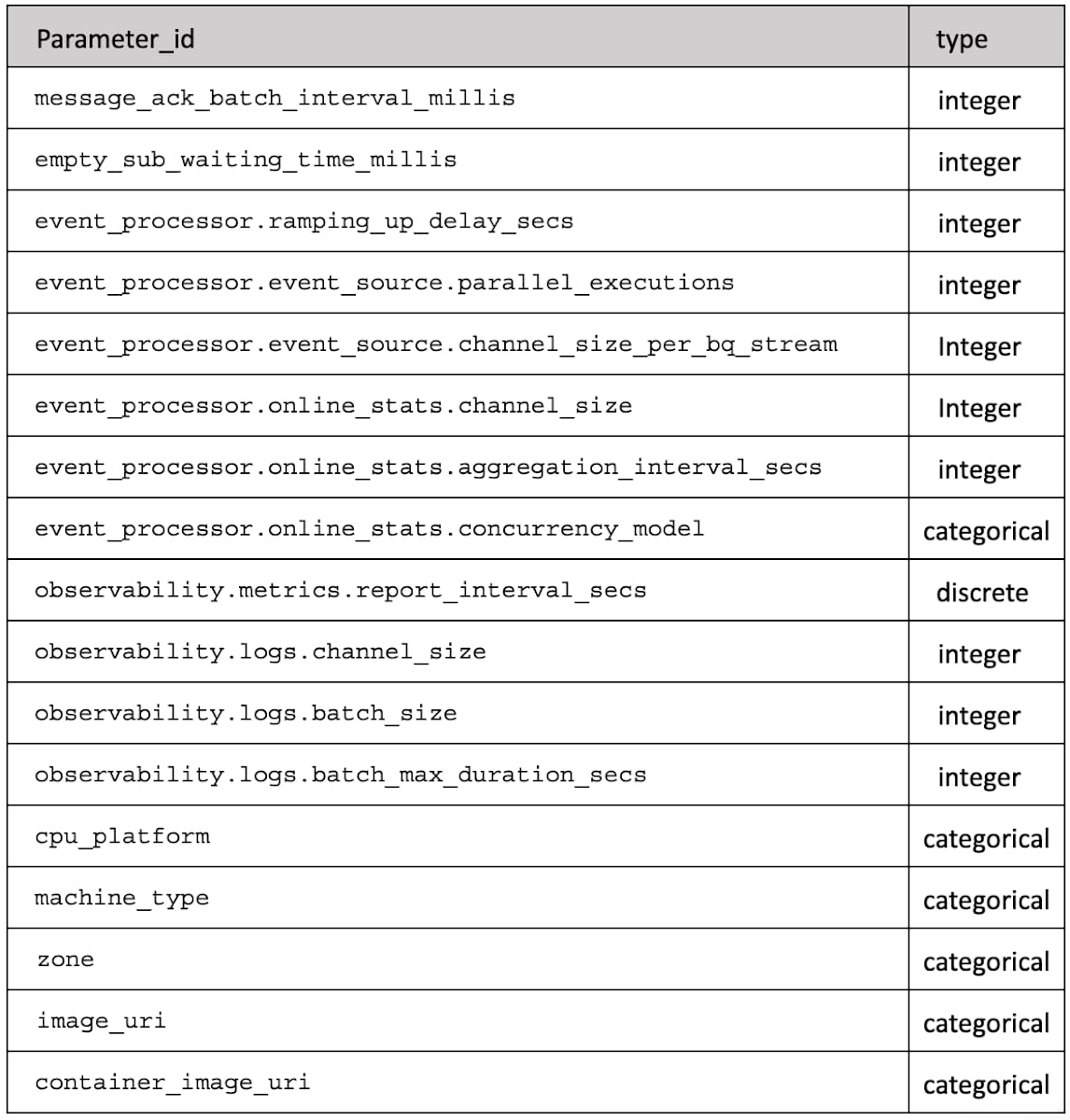
当社のシステムには数多くのノブがあります。プログラムには、調査を行う代替的な方法に対応する構成パラメータと、さまざまなキューのサイズやワーカーの数などを設定するサイズ設定パラメータがあります。実行環境では、VM 構成、マシンタイプ、OS イメージ、ロケーションなどさらに多くのパラメータを定義するので、パラメータの数が大きく変化するのは一般的なことです。今回のシナリオでは、12 個のパラメータがあります。
最終的に、パラメータ空間は表 1 によって記述され、これは各「parameter_id」について、値のタイプ(整数、個別、カテゴリ)を示します。
目標を明らかにして、特定されたパラメータのコレクションで指定した割り当ての評価方法を理解し、これらのパラメータのドメインを定義しました。これが、ブラックボックス最適化を行うために必要なことです。
アプローチ
ブラックボックス最適化に話を戻します。これは式がない関数の最小化 / 最大化を扱う問題だとすでに述べましたが、それでも評価することは可能です。必要なのはテストを行い、コストを算出することです。
問題は、テストの実施にはコストがかかること、そして、パラメータ空間を考慮すると、すべてを迅速に探索することは現実的な選択肢ではないということです。12 個ほどのパラメータにそれぞれ 3 つの値だけを選択したと仮定しても、312=531,441 とすでに大きな数字になります。個別に取得された各パラメータのサブセットから生成されたすべての組み合わせを体系的に探索するこの手法を、グリッド検索と呼びます。
その手法の代わりにサロゲート最適化の形式を使用します。目的関数に最適な表現がないこのような場合、実際の関数をモデル化した、優れたプロパティを持つサロゲート関数を導入することが有益な場合があります。「費用関数を最小化する」という問題だけではなく、「問題に関数を当てはめて、それを最小化する」という 2 つの問題があるのは確かです。しかし私たちは、測定の結果にモデルを当てはめ、このモデルを使ってテストを行う必要のある有望な候補を選択するという、次の段階に進むためのレシピを取得しました。テスト結果が出ると、改善点が少なすぎてテストを行う価値がなくなるまでモデルを改良し、新しい候補が生成されます。
Google Cloud の Vertex AI Vizier は、このようなタイプの最適化をサービスとして提供しています。さらに詳細な背景について知りたい場合は、ガウス過程(GP)最適化を利用しているため、十分な解説がされている Google Vizier: ブラックボックス最適化サービスの記事をご覧ください。
入力パラメータの組み合わせを変えて、148 通りのテストを実施しました。そこから何を学んだのでしょうか?
調査結果
この議論のポイントは、コストを最小にするために使用したパラメータの詳細を正確に述べることではありません。使用しているプログラムや設定など、ほとんどが異なるので、応用の利く知識ではないからです。しかし、この手法の可能性を考えてみると、今回のケースでは、148 回のテストを行って、最初に推測した構成での費用関数は、1 回の実施あたり $0.0780 でしたが、最適なパラメータでは、$0.0443 となり、43% のコスト削減を実現しました。当然のことながら、ここでは「machine_type」パラメータが大きな役割を果たしますが、最良の結果を示したものと同じマシンタイプであっても、費用関数の(探索)部分は 1 回の実施あたり $0.0443 と $0.0531 の間で、16% の変動があります。
図 3 は、最も有望なテストの実施内容を表しています。最後の 2 つを除くすべての軸は、パラメータに対応しています。最後の 2 つはそれぞれ、目標である「cost_dollar」と、実施が完了したかどうかを表しています。線は実施内容を表し、それらに対応する各軸の値を結んでいます。
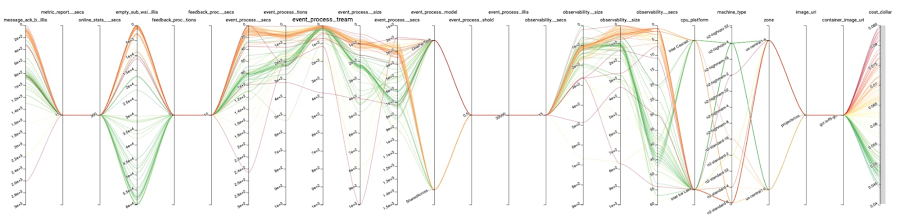
結論として、この調査は、介入をほとんどしなくても大幅なコスト改善が実現できることを明らかにしました。次のセクションでは、その点について掘り下げてみましょう。
手法に関する学習
この手法の最大の利点の一つは、最初の作業で適切な設定を行えば自動で実行されるので、人の介入がほとんど必要ないということです。
ブラックボックス最適化では、f(x) の評価は x にのみ依存し、同時に進行している他のことには依存しないと仮定しています。
f(x) に関する異なる評価間の相互関係を望んではいません。
Vizier の主なアプリケーションの一つに、ディープ ラーニング モデルのハイパー パラメータの最適化があります。そのトレーニングと評価にはコストは別として基本的に副作用がありません。前述しましたが、ブラックボックス最適化の手法は評価にコストがかかることを前提に、最適なパラメータを見つけるために必要な実施回数を減らすように設計されています。今回のシナリオでは、データをある場所から別の場所に移動させるという、明確な副作用があります。
つまり、パフォーマンス テストからすべての副作用を確実に取り除けば、日々の作業は楽になるはずです。ブラックボックス最適化の手法はこのニーズに適合し、特に Vizier が有効です。これは、シナリオの実行を、隔離された環境を設定、破棄するためのロジックでラップすることによって実現できます。これにより、このまったく新しいシステムは、基本的に副作用がありません。
このようなテストの実施に関するいくつかの知識は、強調する価値があると思います。
最初に単一の値があってもすべてをパラメータ化: 別の値が必要になった場合でも、簡単に追加できます。最悪の事態が起きても、値がデータと一緒に記録されるため、必要に応じて異なるテスト間で簡単に比較できます。
テストの実施とその他の要因を分離: その他の要因がパラメータ化されておらず目標に影響を与える場合、測定結果のノイズは大きくなり、最適化プロセスが次にどこを探索するか決定するのが難しくなります。
同時の実施を隔離: 複数のテストを同時に行うことができます。
堅牢な実行: パラメータのすべての組み合わせが実行可能なものとは限りません。Vizier は、そのような内容に関するレポートをサポートしています。
十分な実施回数: Vizier は、以前の実施結果を活用して、次に何を探索するかを決定します。また、測定値を指定することなく、一度に複数のテストを行うように要求できます。これは、同時にテストを開始するのに便利です。さらに私たちの経験では、特定の極値を正確に特定するための探索を始める前に、広い対象範囲やパラメータ空間があるかを最初に確認するのにも便利です。たとえば、この投稿で先ほど説明した一連のテストの実施では、「n2-highcpu-4」は 107 回目の実施まで試行されませんでした。
ツールは現在も利用可能: Vizier は、サービスとして提供されている一例です。ブラックボックス最適化を行うための Python ライブラリも多数ご用意しています。
ノブに時間をかけたくない、マシンにおまかせしたい方は、間違いなくご活用いただけると思います。
まとめと次のステップ
ML のハイパー パラメータの調整は、ブラックボックス最適化でしか行なえません。Google の Vertex AI Vizier は、より応用範囲の広いブラックボックス最適化サービスです。また、本質的に未知の、あるいは相互関係の記述が困難な多くのパラメータによって特徴付けられる複雑なシステムのエンジニアリングにも最適なツールであると確信しています。小規模なシステムであれば、手動または系統的にパラメータを探索できるかもしれませんが、この投稿でお伝えしたポイントは、それを自動化できるということです。
パフォーマンスの最適化は、すべてのものが変化し続け、新しいオプションや新しい使用パターンが登場するので継続的に発生する課題です。
この投稿で紹介した設定は、比較的シンプルで非常に静的なものです。多腕バンディットのようなソフトウェア エンジニアリングの観点から調査する価値のある継続的なオンライン最適化に適した設定の拡張機能があります。
ウィリアム ギブソンの言葉を引用すると、アプリケーション最適化の「未来はすでにここにあるのに、ただ十分に行き渡っていないだけだ」としたらどうでしょう?
すごいと思いませんか?F5 の AI、データグループが採用します!
参照
- F5 シニア アーキテクト Sebastien Soudan 氏
- F5 上級エンジニア Laurent Querel 氏



