Ops エージェントを使って Compute Engine 上の NVIDIA GPU をモニタリングする
Google Cloud Japan Team
※この投稿は米国時間 2023 年 9 月 23 日に、Google Cloud blog に投稿されたものの抄訳です。
商品のレコメンデーション、科学技術計算、ゲーミングなどの用途に AI や ML を使用する企業は、多くの場合、必要なコンピューティング パフォーマンスを得るために、Google Cloud 上で NVIDIA GPU を利用します。このようなワークロードの動作を理解して ML の開発プロセスを最適化するためには、GPU パフォーマンス指標のモニタリングが欠かせません。こうしたニーズに応えるため、Ops エージェントで Compute Engine VM 上の NVIDIA GPU 指標を収集できるようにしました。
Cloud Ops エージェントは Google 推奨の Compute Engine 向けテレメトリー ソリューションで、VM インスタンスをモニタリングしてキュレートしたデータを出力します。NVIDIA Management Library(NVML)の基本的な指標はもちろん、NVIDIA Data Center GPU Manager(DCGM)の詳細なプロファイリング指標も収集するため、NVIDIA GPU とアクセラレーション ワークロードについて詳しく把握することを可能にします。
Ops エージェントでは以下のことが可能です。
- GPU 指標や設定不要のダッシュボードによって、GPU フリートの状態を可視化する
- 使用率が低い GPU を特定してワークロードを統合し、費用を最適化する
- 傾向を見極めてスケーリングを計画し、GPU 容量の拡張や、既存 GPU のアップグレードを行うタイミングを判断する
- 処理能力やメモリを多く消費している GPU プロセス(ML モデル)を特定する
- DCGM プロファイリング指標に基づき、GPU 内のボトルネックやパフォーマンスの問題を特定する
- GPU 指標に基づいてアラートを送信する
基本的な GPU 指標はすぐに収集可能
NVIDIA GPU をお使いであれば、全 GPU デバイスとその実行プロセスの概要を出力する nvidia-smi コマンドについてご存知のことと思います。Ops エージェントは、NVML 内で nvidia-smi コマンドと同じ基盤 API を使用しており、そのような基本的な指標を特別な設定なしで収集することができます。収集可能な指標は以下のとおりです。
- GPU 使用率
- GPU メモリ使用量
- プロセスの最大 GPU メモリ使用量
- プロセスの全期間の GPU 使用率
プロセスの指標を使って、GPU 上で実行中のワークロードをトラッキングできます。
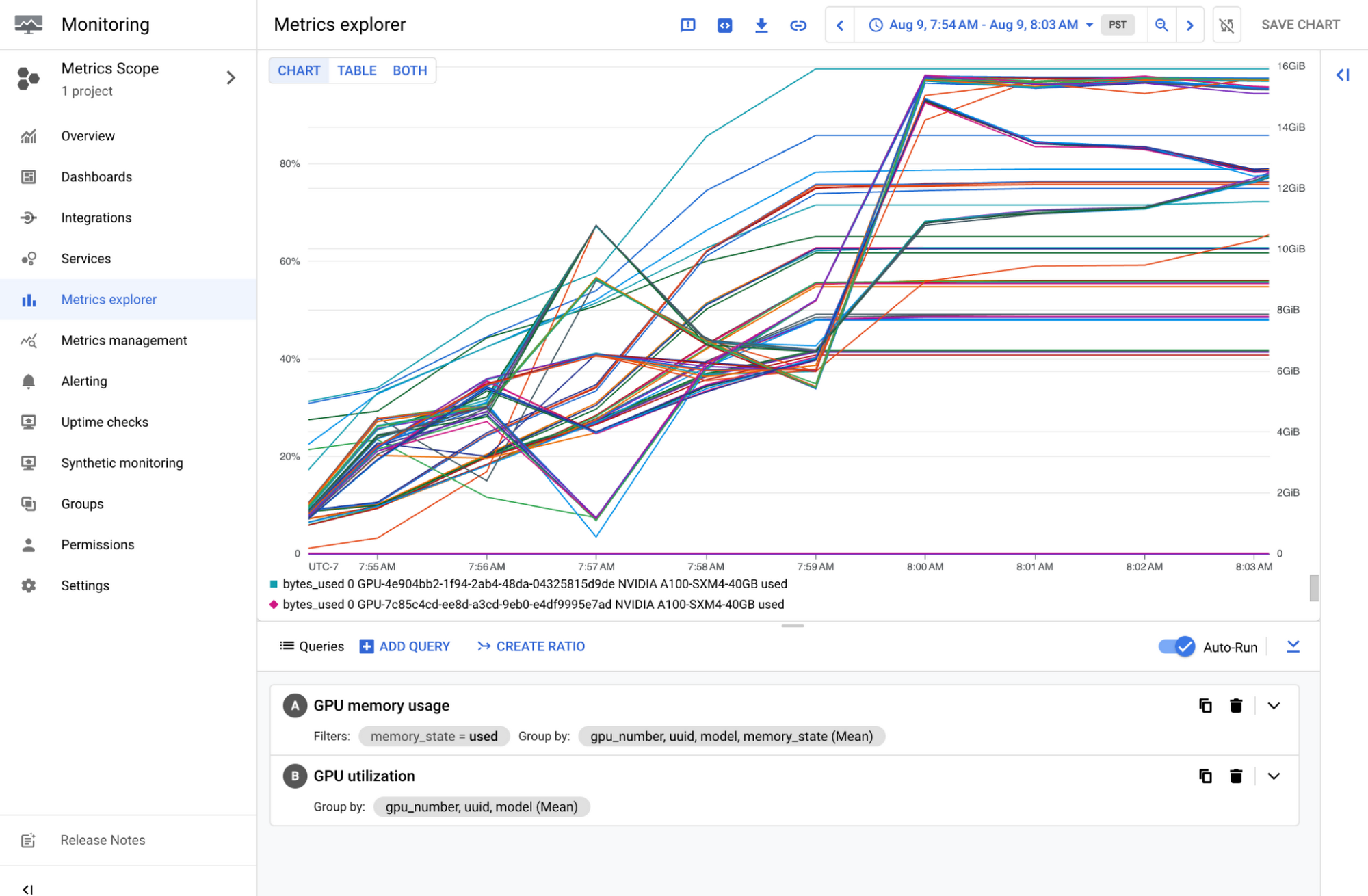
Cloud コンソールの Metrics Explorer で GPU メモリ使用量を確認
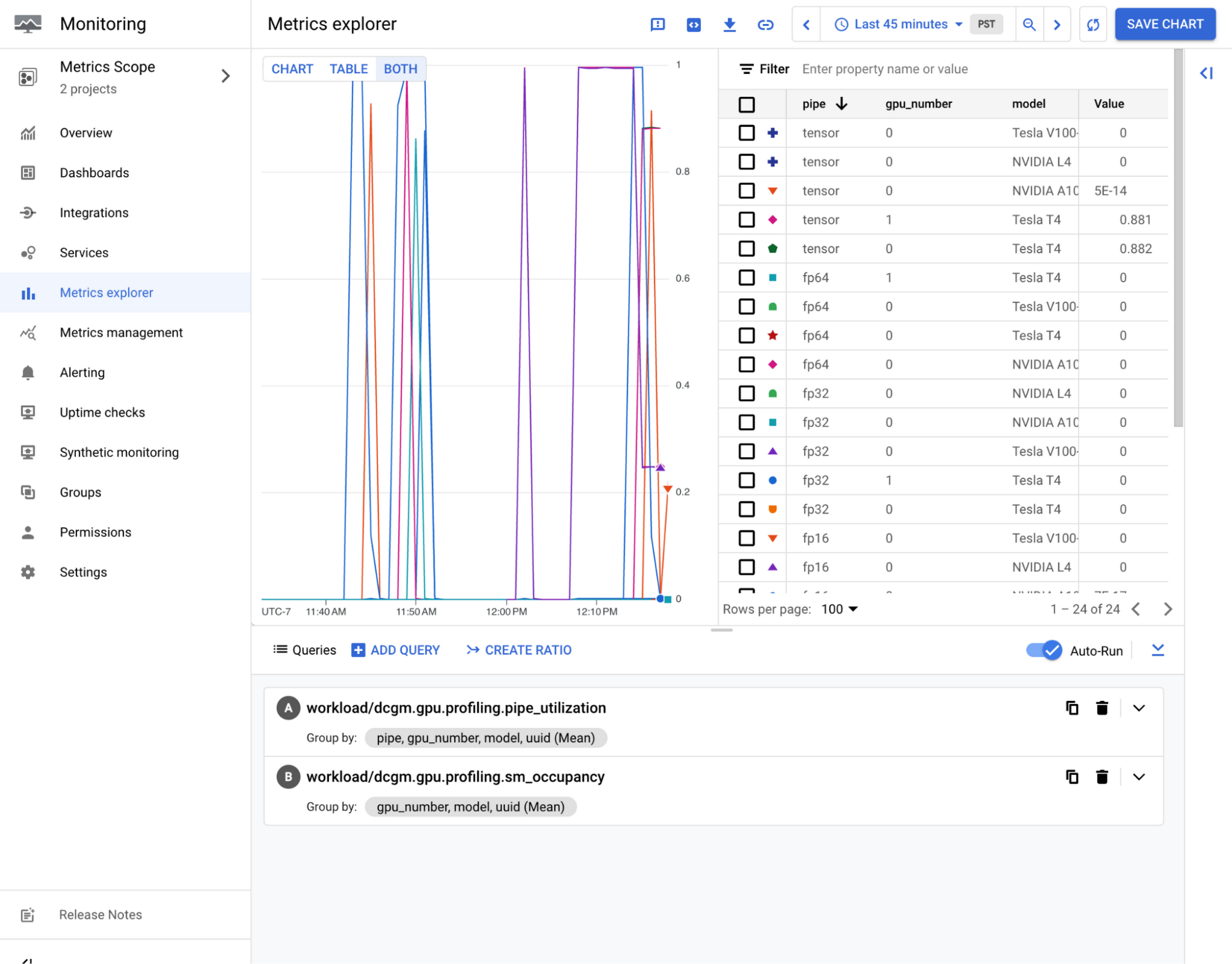
Cloud コンソールの Metrics Explorer で DCGM PCIe トラフィック レートを確認
GPU の状態を可視化する
Google Cloud のオペレーション スイートの他のプロダクトも併用すれば、Ops エージェントで取得した GPU 指標に対してクエリを実行したり、可視化したりすることも簡単です。たとえば、Metrics Explorer クエリビルダーまたは PromQL を使って、クエリやカスタム チャートを作成し、ダッシュボードに追加できます。また、NVIDIA GPU Monitoring ダッシュボードには、GKE GPU ノードと Compute Engine GPU VM の両方から収集した GPU 指標を使用して、GPU フリート全体の情報が一括表示されます。このダッシュボードを独自のプロジェクトにインポートする方法については、ドキュメントをご覧ください。なお、Cloud Monitoring と DCGM を統合している場合は、DCGM 指標の収集が始まると同時に DCGM ダッシュボードが自動的にプロジェクトに追加され、GPU プロファイリング指標に焦点を絞ったビューが提供されます。
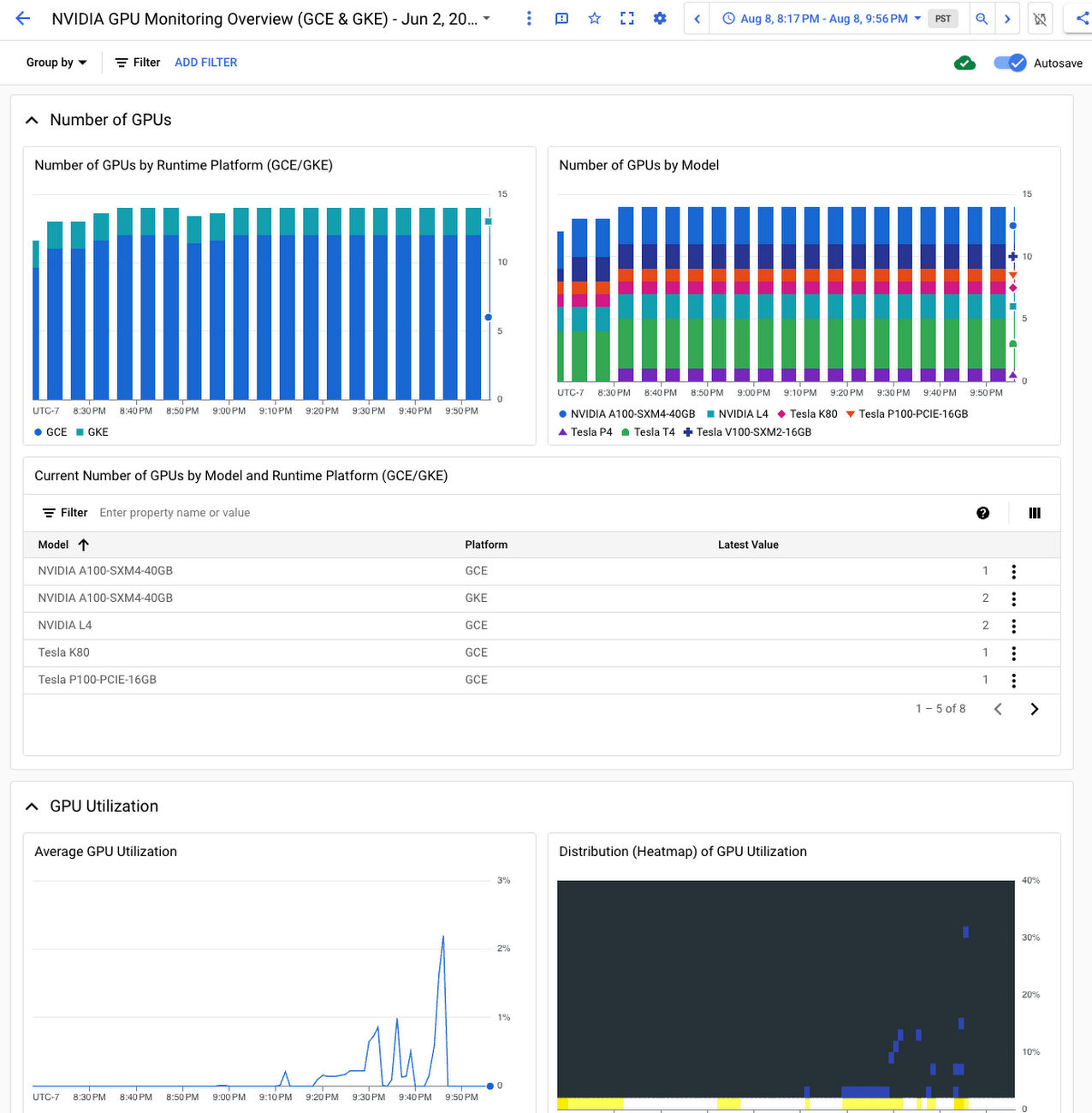
NVIDIA GPU Monitoring Overview ダッシュボードで GPU フリートをモニタリング
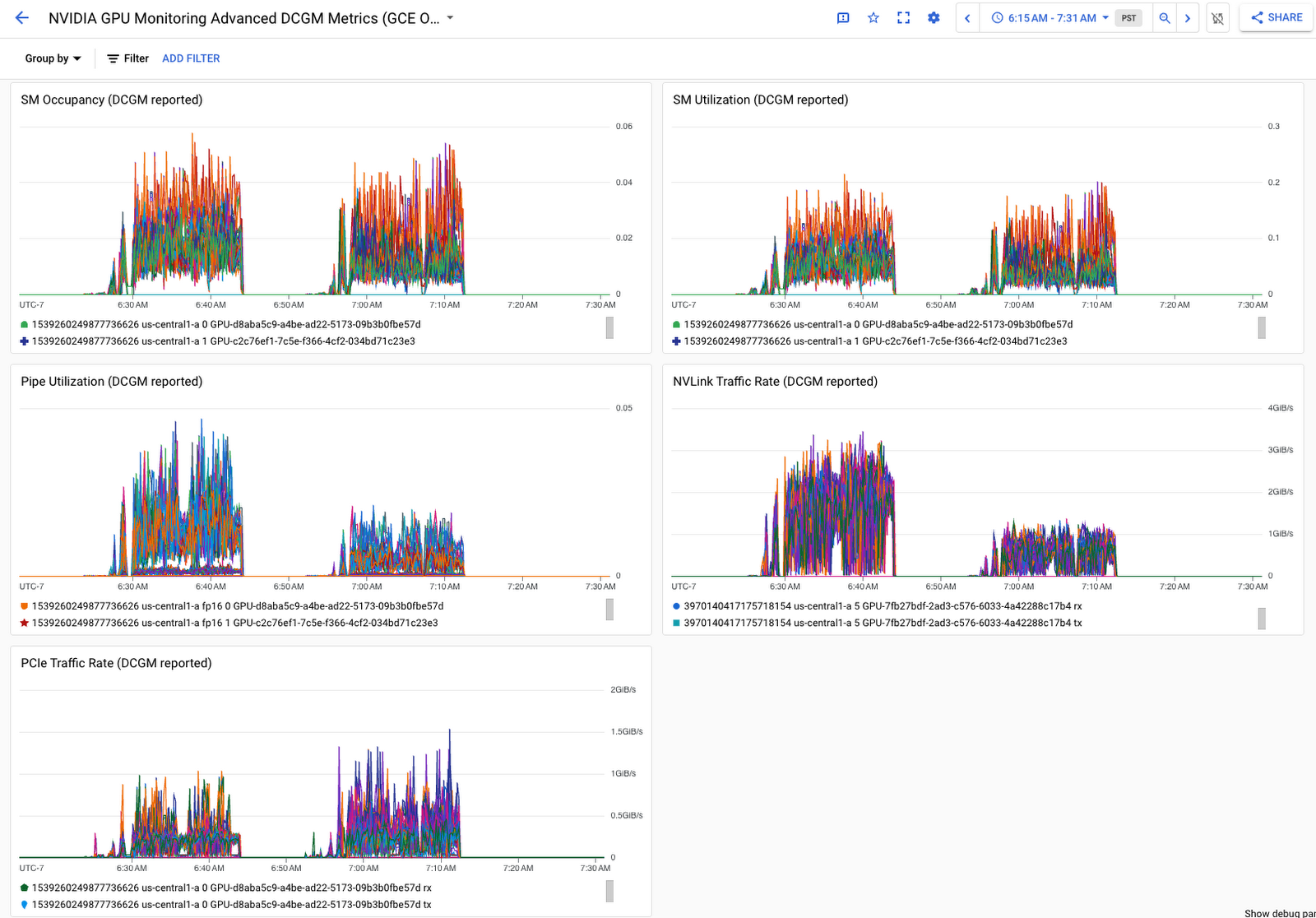
DCGM インテグレーション ダッシュボードで GPU 詳細指標を確認
VM のモニタリング、ロギング、トレース用の単一の統合型エージェント
Ops エージェントは豊富な機能を備えた統合型のテレメトリー エージェントです。直感的な設定インターフェースを使って、GPU の可視化のほかにも以下のようなことを行えます。
- ホストの指標(CPU、メモリ、プロセスなどの指標)を自動収集する
- システムログ(Linux VM の syslog や、Windows VM の Windows イベントログなど)を自動収集する
- Prometheus 指標、OpenTelemetry Protocol(OTLP)指標とトレースをワークロードから収集する
- ロギング ファイル レシーバーを使用して、ML ワークロードのログファイルを Cloud Logging に取り込む
- 指標プロセッサを使用して、NVML 指標や DCGM 指標の収集間隔を変更したり、不要な指標を除外したりする。このような指標の除外や収集間隔の変更は、構成ファイルを使って簡単に行えます。
これらの管理操作を単一のエージェントで行えるため、GPU VM を効果的に活用にすることに集中できます。
今すぐ使用を開始する
Google Cloud コンソールで VM を作成する際に、Ops エージェントをお試しいただけるよう、VM の新規作成時にワンクリックで Ops エージェントを追加するオプションをご用意しました。VM や Ops エージェントの大規模な管理方法を決定する前段階で、Ops エージェントをデフォルト構成でお試しいただけますので、どうぞご利用ください。
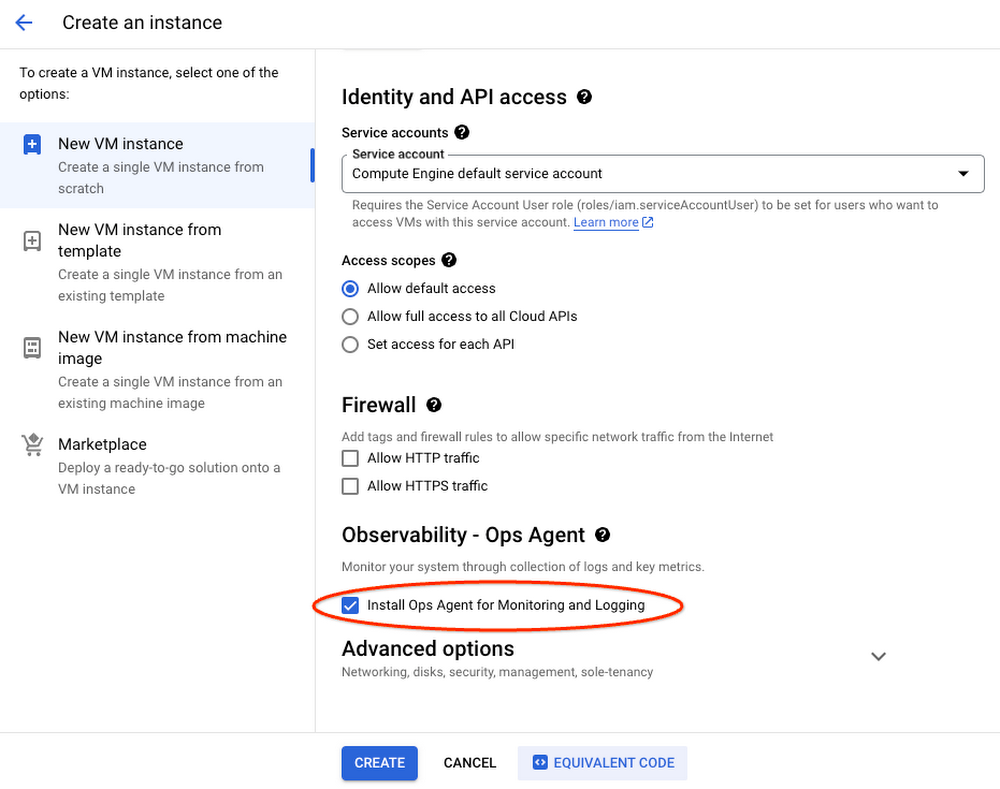
VM 作成時に Ops エージェントをインストールしてシームレスにモニタリング可能
Ops エージェントをインストールして、GPU インスタンスをモニタリングするために設定する方法については、ドキュメントをご覧ください。
ー ソフトウェア エンジニア Lujie Duan
ー AI アクセラレータ エクスペリエンス担当シニア ソフトウェア エンジニア Suffian Khan


