Kubernetes Engine の Cloud Console ダッシュボードを正式リリース
Google Cloud Japan Team
Google Kubernetes Engine を管理する主な方法としては、kubectl コマンドライン インターフェースと、ウェブ ベースのダッシュボードである Cloud Console の 2 つがあります。このうち、Kubernetes Engine 用の Cloud Console は正式リリース(GA)されており、アプリの状態を把握したり、トラブルや問題点を解決したりするのに役立つ新しい機能を備えています。
アプリのトラブルシューティング
これらの新機能を見ていくにあたって、Kubernetes Engine 上の環境を管理、運用している DevOps 管理者の Alice を紹介しましょう。Alice は Cloud Console にログインし、アプリの状態を監視しています。Alice はまず、どのクラスタでアプリが動いているかに関係なく、すべてのアプリの状態を表示する Workloads ビューを開きます。彼女のチームは、異なる環境ごとに異なるクラスタを作成しているので、このビューは Alice にとって特に便利です。
Alice は、下の例に示すように、フロントエンドの 1 つに問題を見つけます。ステータス欄が赤くなっているところです。
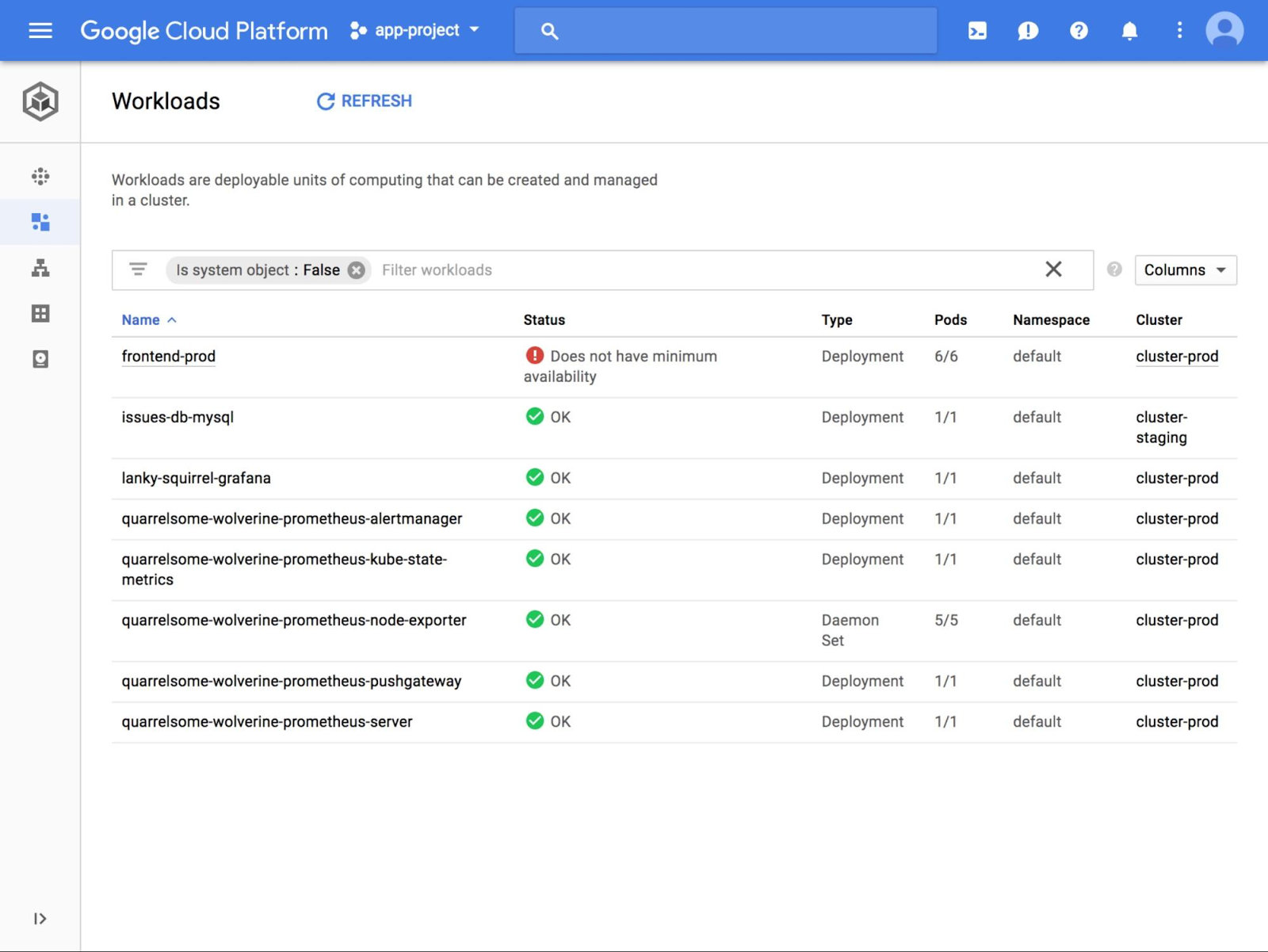
ワークロードの名前をクリックすると、デバッグの出発点となる詳細ビューが表示されます。Alice は、CPU、メモリ、ディスクの使用状況を示したグラフをチェックし、リソース利用の急激なスパイクを見つけました。
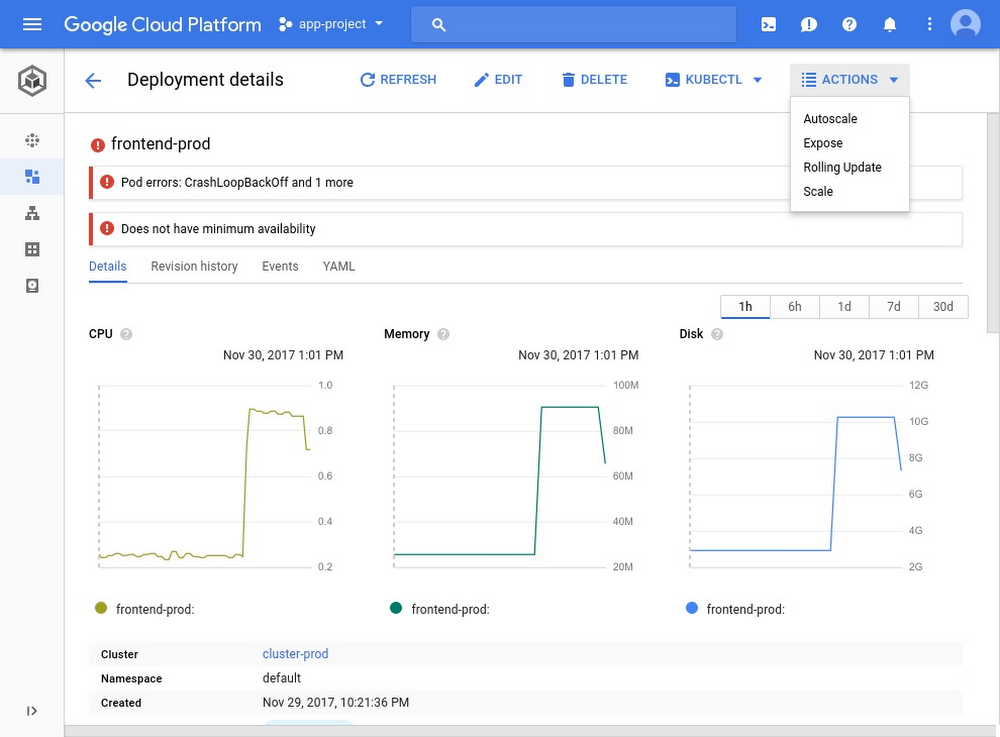
根本原因の調査に入る前に、Alice は Horizontal Pod Autoscaler をオンにして、アプリの障害を緩和することにします。自動スケーリング機能は Cloud Console の上部のメニューで操作できます。彼女は、レプリカの上限を 15 に増やし、自動スケーリングを有効にしました。
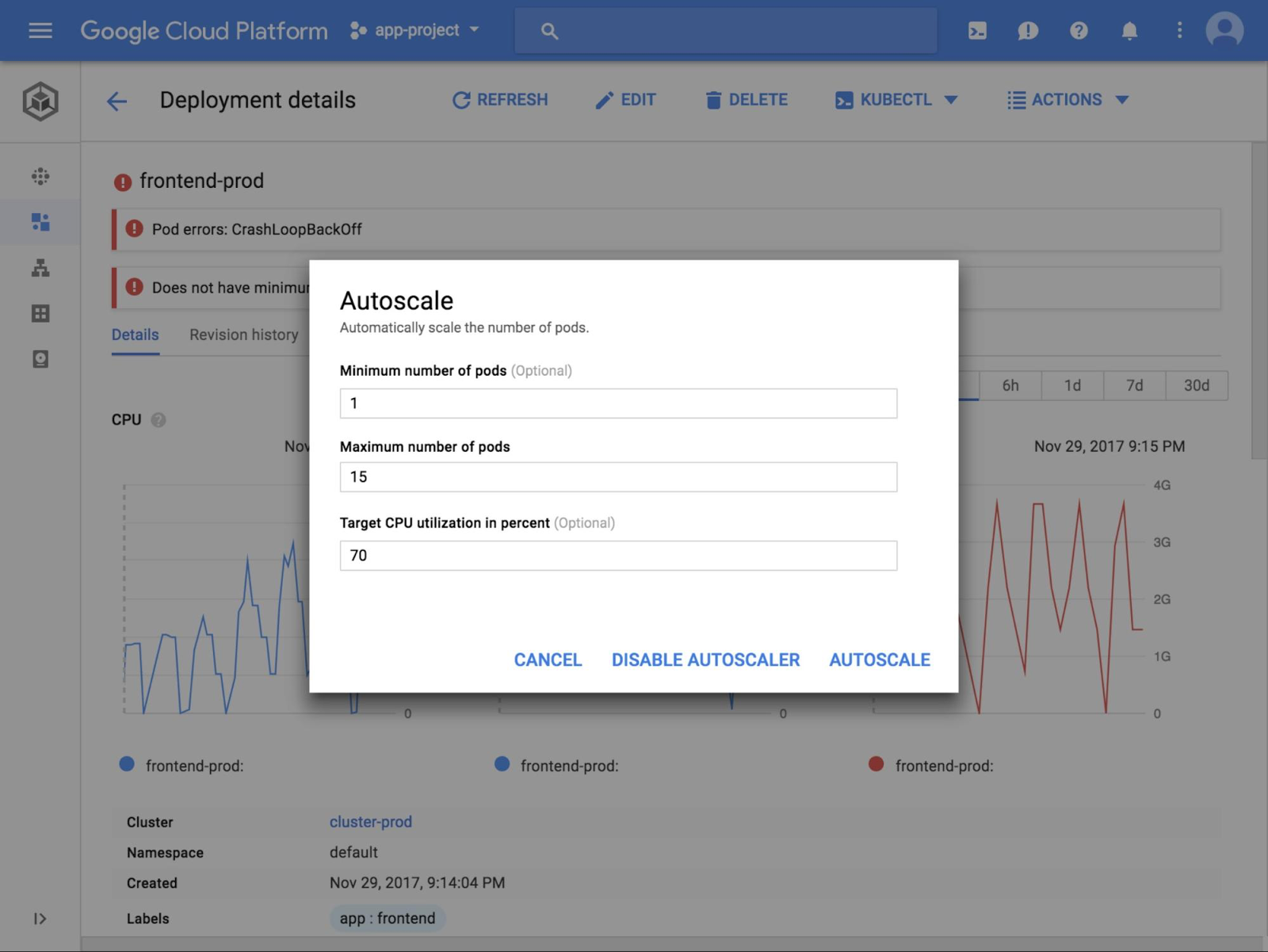
サービスがスケールアップし、ユーザーのトラフィックを再び処理できるようになったので、Alice は CPU の使用率が急上昇した根本原因を調べることにしました。
まず、ポッドの 1 つを覗いてみると、その CPU 使用率が高くなっていることがわかりました。詳しく調べるため、Logs タブを開いて、問題を起こしているポッドの最近のログを見てみます。
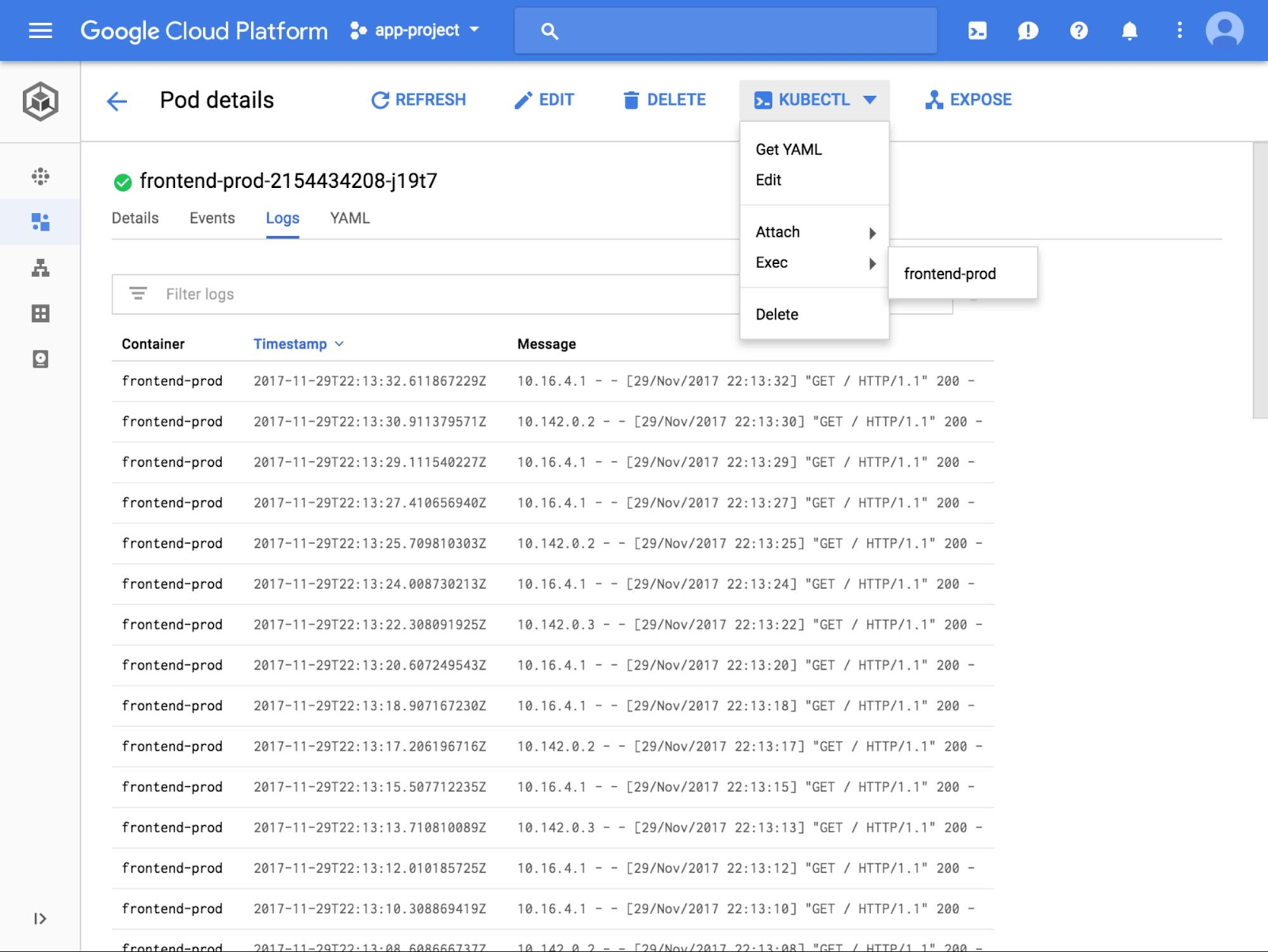
ログは、フロントエンドの http サーバーに問題があることを示していました。そこで Alice は、さらなるデバッグのために実行中のポッドに接続することにしました。Cloud Console から直接 Cloud Shell を開き、選択したポッドにアタッチします。正確なコマンド、適切な認証情報、kubectl コンテキストの設定などを覚えておく必要はありません。Cloud Shell をロードすると、正しいコマンドがすでに入力された状態になっているからです。

Linux の top コマンドを実行すると、CPU スパイクの犯人が http サーバー プロセスだということがわかりました。彼女は使い慣れたツールでコードを調査し、バグを見つけ、修正しました。
新しいコードの準備が整ったので、Alice はローリング アップデートのために再び UI を開きます。UI の先頭にはローリング アップデート アクションが表示されており、彼女はイメージ バージョンをアップデートしました。すると、Cloud Console がローリング アップデートを開始します。画面にはその進捗状況が表示され、アップデート中に発生する可能性のある問題がハイライト表示されます。
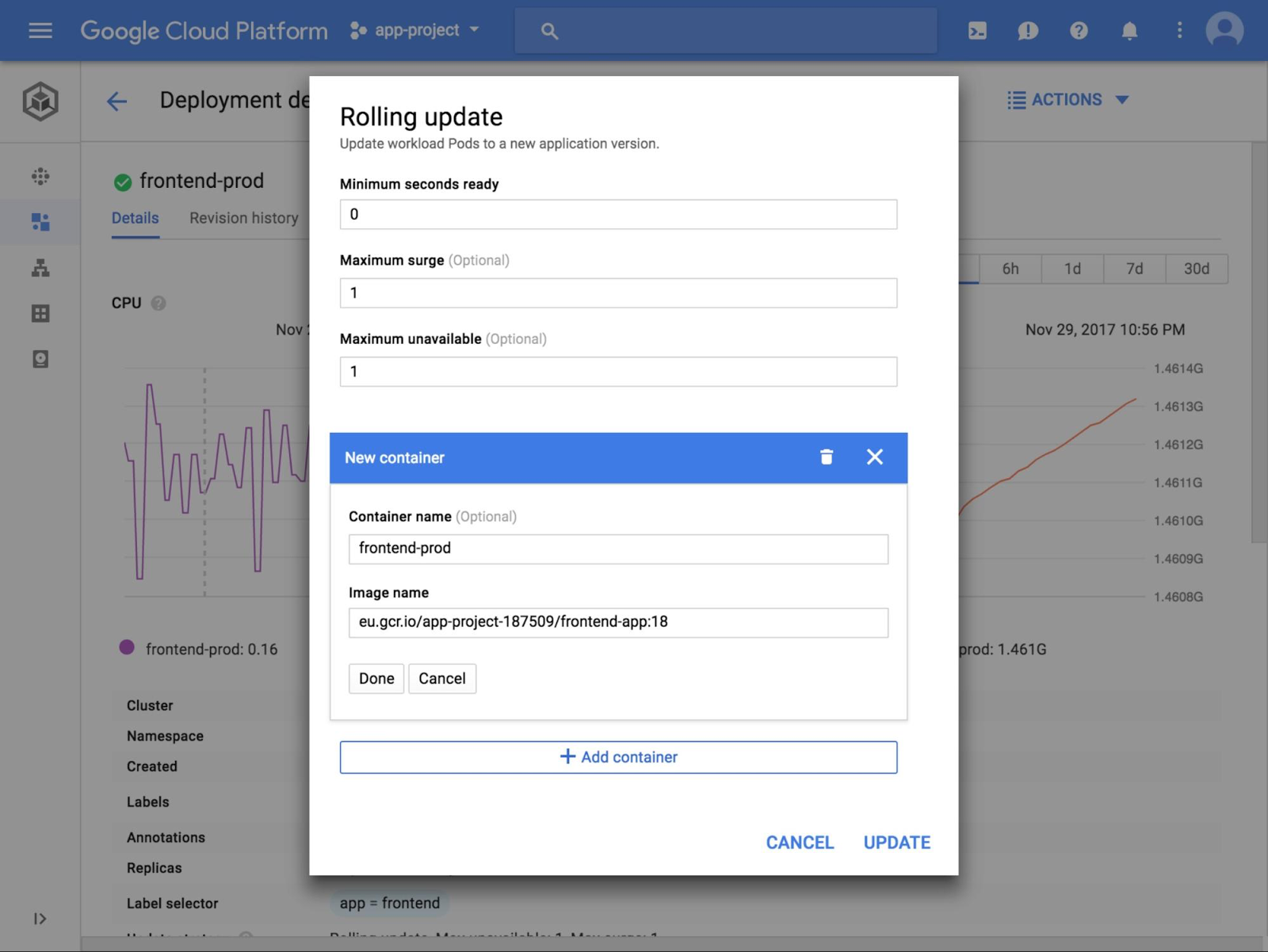

Alice は、フロントエンド デプロイのリソース使用状況を示すグラフ、ステータス、ログをチェックし、正しく動作していることを確認しました。他のクラスタのフロントエンド デプロイについても同様にローリング アップデートを実行でき、その際、コンテキストを切り替えて新しい認証情報を入力する必要はありません。
ちなみに、Kubernetes Engine の Cloud Console には Kubernetes 管理者の日常業務を支援する機能も含まれています。たとえば、Kubernetes オブジェクトを書き換える YAML エディタ、ポッドやロード バランサといった関連リソースのデータを集計するサービス可視化ツールなどです。これらの機能の詳細は Kubernetes Engine ダッシュボードのドキュメントをご覧ください。
Kubernetes Engine クラスタの管理
Kubernetes Engine の新しい Cloud Console ではクラスタ管理者向けの機能も強化されています。Alice と同じ会社で働く Bob は、問題となったアプリが稼働しているクラスタの管理を任されています。クラスタのノード リストをチェックした Bob は、すべてのノードがリソースを使い切る寸前になっており、他のワークロードをスケジューリングする余力がクラスタにないことに気づきました。
彼はノードの 1 つをクリックし、そこにスケジューリングされているポッドで起きていることを調べます。すると、Alice が Horizontal Pod Autoscaler をオンにしたために、フロントエンド ポッドの複数のレプリカがクラスタ内のすべてのスペースを占領していることがわかりました。
そこで Bob は、Cloud Console から直接クラスタを編集して、クラスタの自動スケーリングをオンにします。これで、クラスタのスケールアップから数分後に再びすべてが動作するようになりました。
以上は、Kubernetes Engine の Cloud Console ダッシュボードでできることのほんの一部です。Cloud Console にログインし、Kubernetes Engine タブをクリックするだけで、ダッシュボードを開くことができます。UI の右上隅にあるフィードバック ボタンをクリックして、ぜひ感想をお聞かせください。
編集部注 : 米国時間の 12 月 6 日~ 8 日、テキサス州オースティンで #KubeCon カンファレンスが開催され、Kubernetes コミュニティが一堂に会しました。期間中、Google Cloud チームもプレゼンテーションやワークショップなどさまざまなイベントを催しました。
* この投稿は米国時間 12 月 5 日、Google Kubernetes Engine の Product Manager である Maks Osowski によって投稿されたもの(投稿はこちら)の抄訳です。
- By Maks Osowski, product manager, Google Kubernetes Engine


