ログ分析の向上におすすめする 5 つの手段
Google Cloud Japan Team
※この投稿は米国時間 2019 年 12 月 6 日に、Google Cloud blog に投稿されたものの抄訳です。
Stackdriver Logging は Google Cloud の運用管理ツールセットの 1 つで、大規模なログ管理や分析に適しており、ハイブリッド クラウド環境のトラブルシューティングやアプリケーションの分析情報の取得などにご利用いただけます。ただし、マシンが生成するデータを大量に使用すると、ログの検索が難しくなることがあります。
Google が Stackdriver Logging ユーザーの協力を得て長年取り組んできた、必要な値をログから引き出す簡単かつ最適な方法がようやく形になりました。Google が収集した、ログ分析の効率向上やすばやいトラブルシューティングに役立つヒントを紹介します。これには検索内容の保存、クエリ ライブラリ、BigQuery へのログのエクスポート時のパーティション分割テーブルのサポートなど、
ログからすばやく簡単に値を引き出せるようになった新機能が含まれています。
1. 高度なクエリ言語を活用する
Stackdriver ログを検索する場合、デフォルトの基本モードでは、プルダウン メニューを使用してリソース、ログ、重大度を選択します。この方法で極めて簡単にログの使用を開始できますが、ユーザーの大半はより複雑なクエリを実行できる高度なフィルタを使うようになっていきます。次に例を示します。
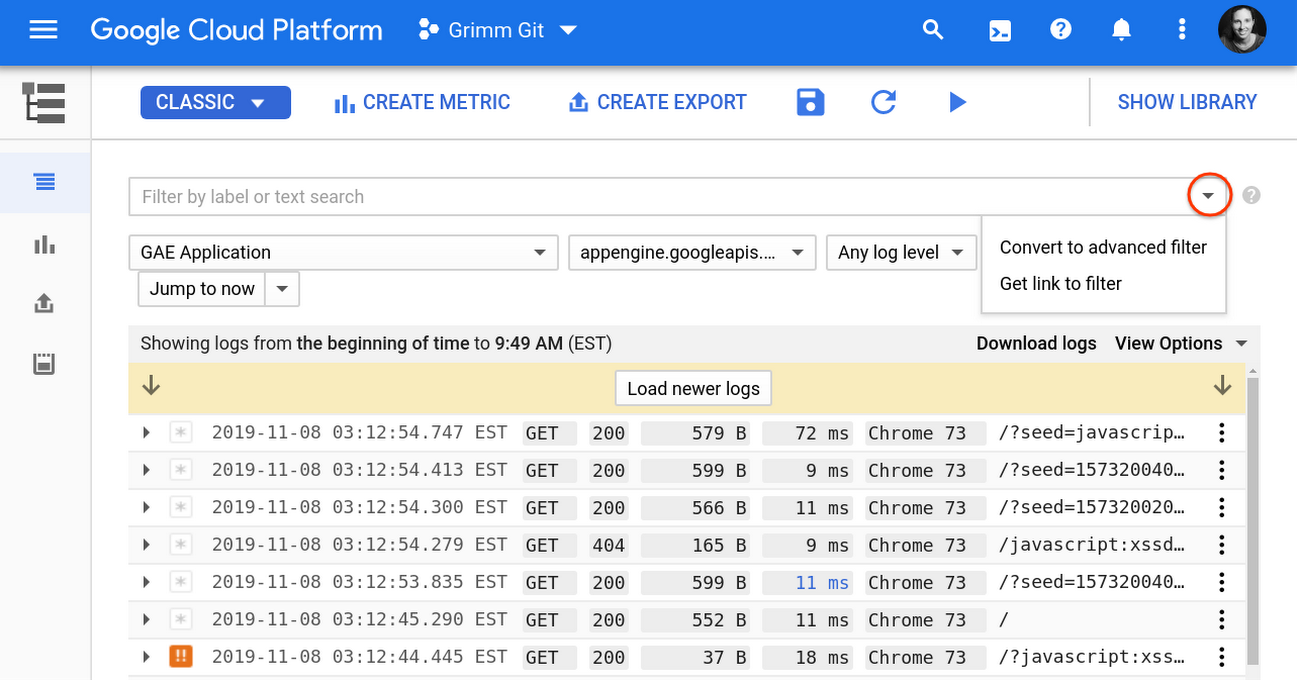
高度なクエリモードに備わった便利なツールには次のものがあります。
比較演算子:
= # equal
!= # not equal
> < >= <= # numeric ordering
: # "has" matches any substring in the log entry fieldブール演算子: デフォルトでは複数の句が AND で結合されていますが、OR や NOT ももちろん使用できます(必ず大文字を使用してください)
関数: ネットワーク ログを分析するには、次の例のように ip_in_net() がおすすめです
ip_in_net(jsonPayload.realClientIP, "10.1.2.0/24")
ワンポイント: ログのフルネーム、期間、インデックス フィールドを含めて、検索結果の高速化を図ります。
パフォーマンスの高速化に関するさまざまなヒントをご覧ください。
新しいクエリ ライブラリ: Google Cloud に携わるエキスパートを対象に、Kubernetes、セキュリティ、ネットワーク ログなどのユースケースごとに最も一般的に使われている高度なクエリは何かというアンケートを取りました。Google のドキュメントで新しいサンプルクエリ ライブラリをご覧ください。他にも確認したいことがございましたら、サンプルクエリ ページ上部の [フィードバックを送信] ボタンをクリックして、お知らせください。
2. 検索結果をカスタマイズする
ログ分析で特に重要になる特定のフィールドが、ログエントリの中に埋もれていることがよくあります。フィールドをクリックして [概要行にフィールドを追加] を選択すれば、検索結果をカスタマイズしてこのフィールドを含めることができます。もちろん手動でフィールドを追加、削除、再編成したり、[表示設定] で幅の上限を切り替えたりすることも可能です。この構成を使えば、必要な文脈だけを要約して取り出せるので、トラブルシューティングが劇的にスピードアップします。こちらの例をご覧ください。
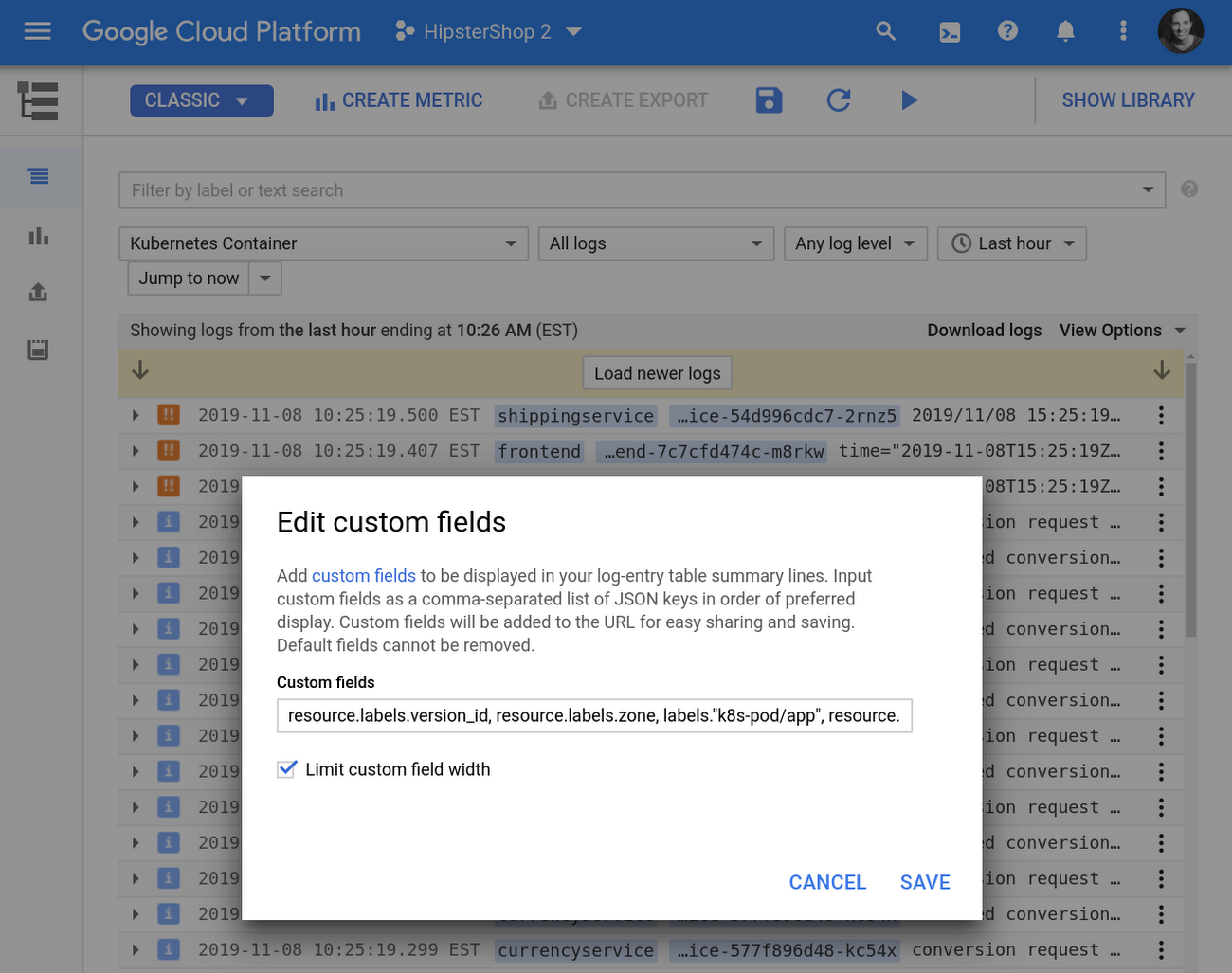
3. よく使う検索やカスタム検索結果を個人の検索ライブラリに保存する
同じ検索を何度も使用するので、次回の検索で使用できるようにカスタム フィールド構成を保存したいというご意見がよく寄せられます。これを受けて最近 Google では、ご自身のライブラリ内のカスタム フィールドを含む検索内容を保存できる新機能の提供を始めました。
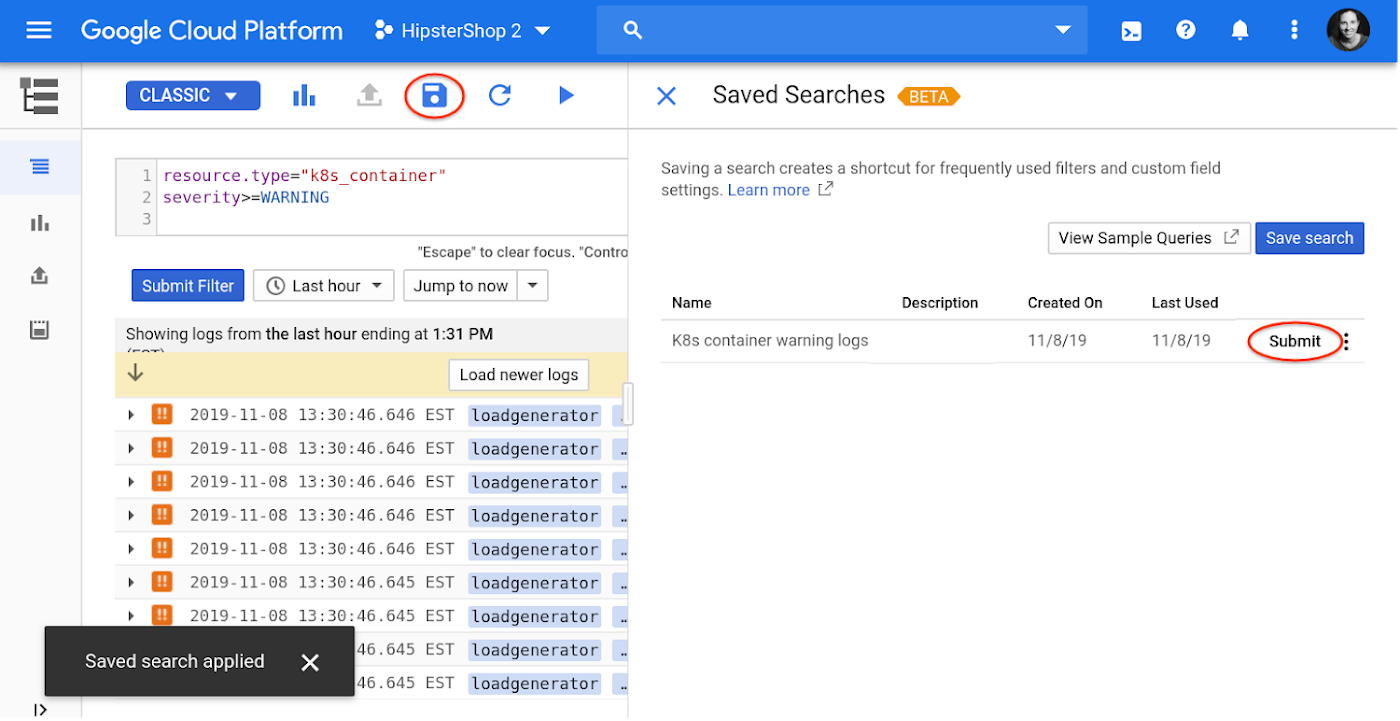
[送信] の横にあるセレクタをクリックしてから [プレビュー] をクリックすると、プロジェクトへのアクセス権を持つユーザーと保存した検索を共有できます。コピーリンクをクリックしてフィルタし、チームと共有します。この機能は現在ベータ版でのご提供となっております。すばやいログ分析の実現に向けて、今後も引き続きクエリ ライブラリ機能の開発に取り組んでいきます。
4. ダッシュボードやアラート機能にログベースの指標を使用する
高度なクエリを扱えるようになると、ログベースの指標を使うリアルタイム モニタリングというさらにレベルの高い分析を行うことができるようになります。たとえば、組織外部のメールアドレスにアクセス権が付与されるたびにアラートを受け取りたい場合、「my-org.com」ドメインに名前のない人にアクセス権を付与する Cloud Resource Manager SetIamPolicy の呼び出しにある監査ログに一致する指標を作成できます。
resource.type="project" logName="projects/[PROJECT_ID]/logs/cloudaudit.googleapis.com%2Factivity"
protoPayload.serviceName="cloudresourcemanager.googleapis.com"
protoPayload.methodName="SetIamPolicy"
protoPayload.serviceData.policyDelta.bindingDeltas.member:*
(NOT protoPayload.serviceData.policyDelta.bindingDeltas.member:"@my-org.com")フィルタを設定したら、[指標を作成] をクリックして名前を付けます。
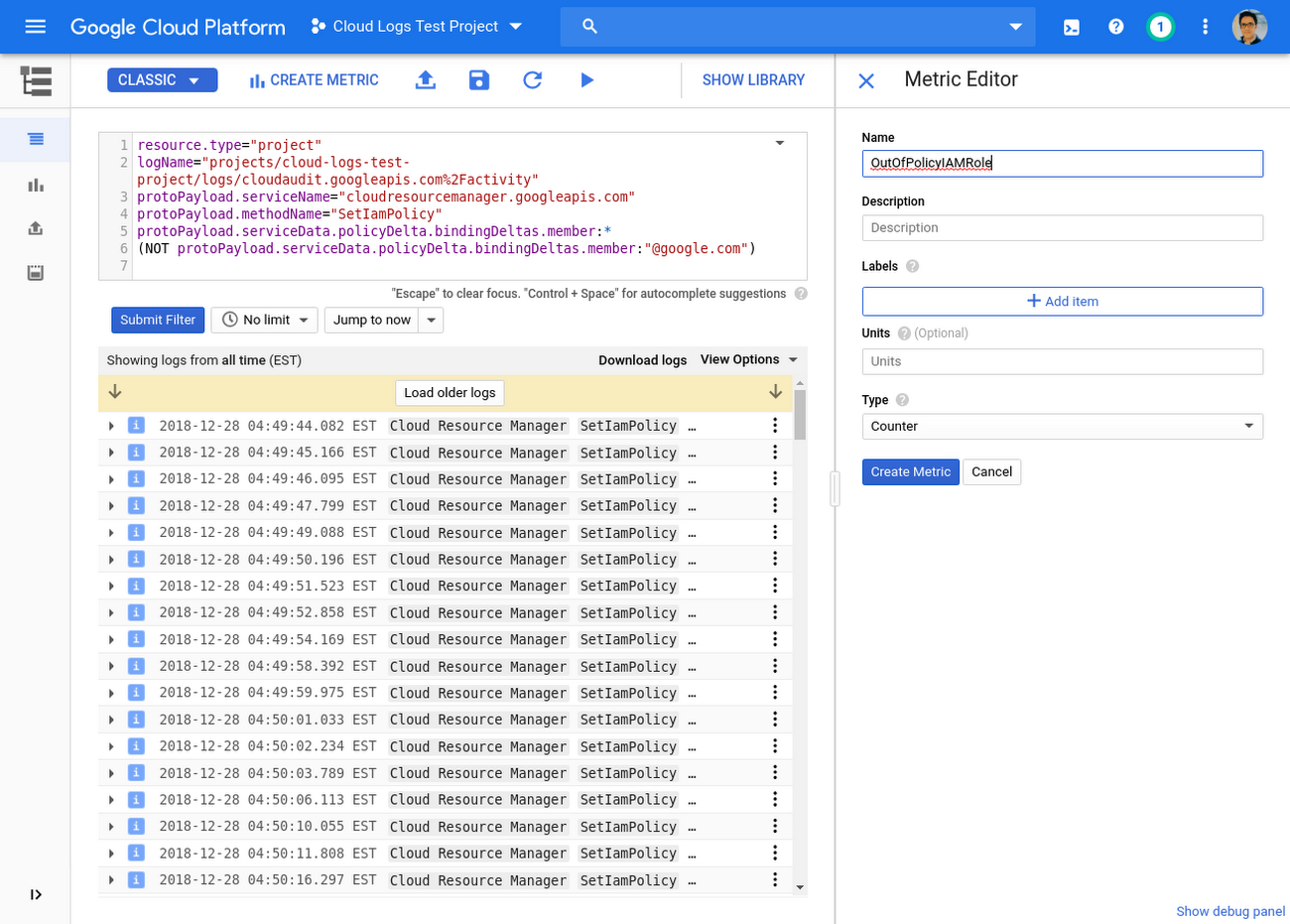
一致するログを受け取った場合にアラートを表示するには、新たに作成したユーザー定義指標の横のその他メニューから [指標に基づいて通知を作成する] を選択します。こうすると、Stackdriver Monitoring で新しいアラート ポリシーが開きます。アグリゲータを [合計] に変更し、[最新の値] のしきい値を 0 に変更すれば、ログが一致するたびにアラートが表示されるようになります。指標では指標作成後のログエントリのみをカウントするので、データがなくても心配する必要はありません。
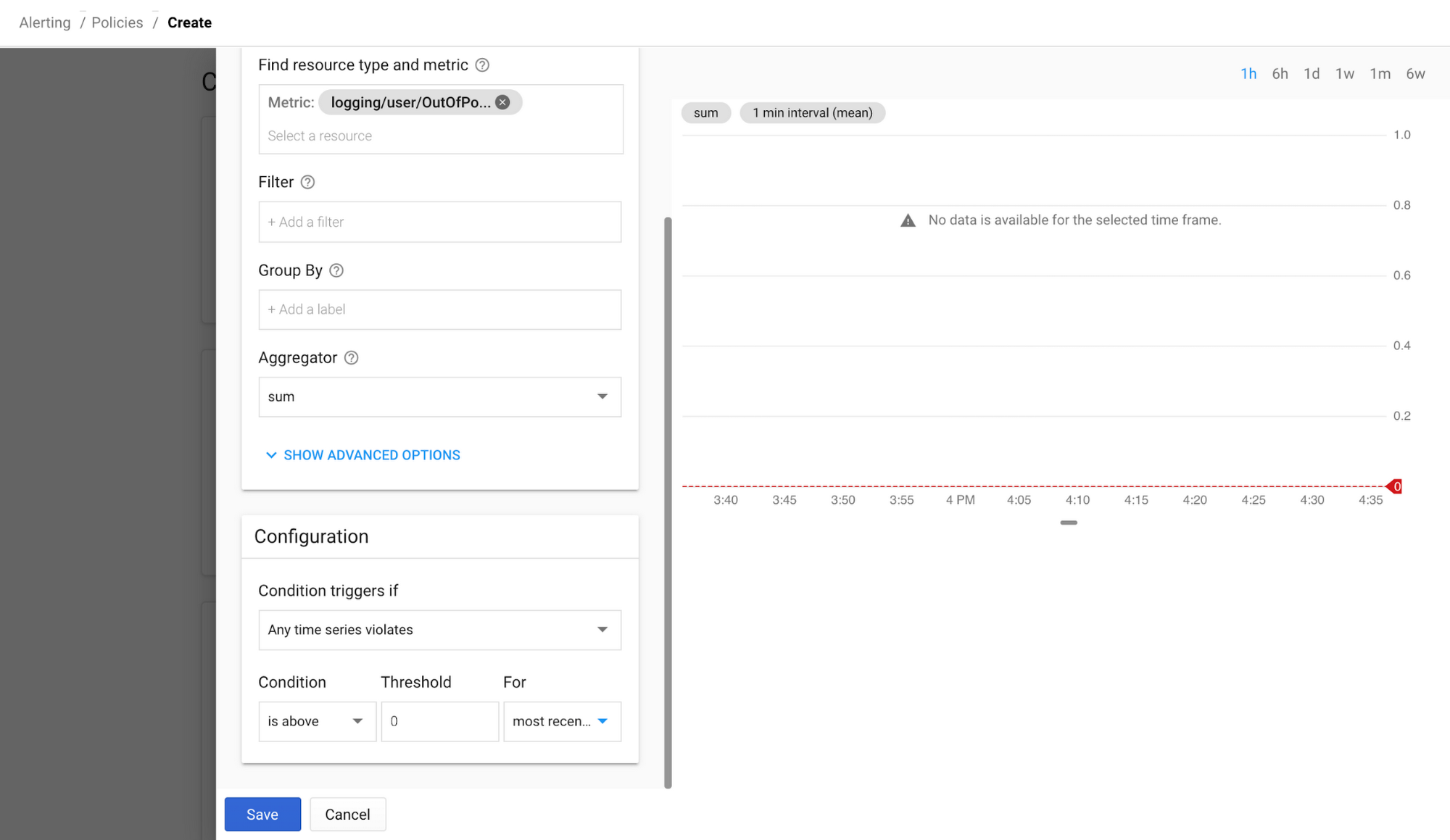
また、メールアドレス、Slack チャンネル、SMS、PagerDuty のアカウントと名前を追加して、アラート ポリシーを保存することも可能です。こうした指標をカスタム指標やシステム指標とともにダッシュボードに追加することもできます。
5. パーティション分割テーブルを使って BigQuery のログで使う SQL クエリの高速化を図る
Stackdriver Logging ではログシンクを使って BigQuery にログを送信して SQL を使う高度な分析を実行する、あるいは Cloud Billing などの他のデータソースと結合する、といった操作に対応しています。パーティション分割テーブルに対応していれば、BigQuery で数日分のログを分析するのがより簡単になるというご意見をいただき、こちらの分割テーブル機能を最近追加しました。これで BigQuery のログで使う SQL クエリが簡略化されます。
ログを BigQuery にエクスポートできるシンクを作成する場合、日付別テーブルまたはパーティション分割テーブルを使用できます。デフォルトでは、接尾辞としてテーブル名に _YYYYMMDD が追加された日付別テーブルが選択されており、ログエントリのタイムスタンプに基づいて日次テーブルが作成されます。日付別テーブルの場合、クエリのオーバーヘッドを増やす原因になりうる次のような欠点があります。
UNION 演算子を使ってパーティション分割をシミュレーションする必要があるため、数日分のクエリ処理を行うとなると難しくなります。
BigQuery は日付別テーブルごとにスキーマとメタデータのコピーを保持する必要があります。
BigQuery がクエリを実行したテーブルごとに権限を確認しなければならない場合があります。
ログシンクを作成する場合、これからは [パーティション分割テーブルを使用する] オプションを選択して BigQuery のパーティション分割テーブルを使用すれば、日付別テーブルにまつわる問題を解消できます。
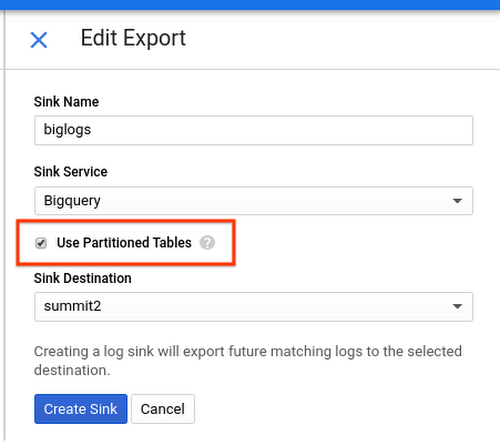
パーティション分割テーブルに配信されたログは、ログエントリのタイムスタンプ フィールドを使用して適切なパーティションに書き込まれます。このような取り込み時間パーティション分割テーブルのクエリは _PARTITIONTIME または _PARTITIONDATE という名前の擬似列の述部フィルタを指定して、スキャンするログの量を制限できます。WHERE フィルタを使用して、次のように日付の範囲を指定することもできます。
WHERE _PARTITIONTIME BETWEEN TIMESTAMP("20191101") AND TIMESTAMP("20191105")
詳しくはパーティション分割テーブルのクエリをご覧ください。
こちらの Stackdriver Logging の詳細もご覧ください。またぜひ、Google のエンジニアおよびプロダクト管理チームと直接対話していただけるグループにご参加ください。
- by Mary Koes, プロダクト マネージャー



