5 favorite tools for improved log analytics
Mary Koes
Product Manager, Google Cloud
Summit Tuladhar
Software Engineer
Stackdriver Logging, part of our set of operations management tools at Google Cloud, is designed to manage and analyze logs at scale to help you troubleshoot your hybrid cloud environment and gain insight from your applications. But the sheer volume of machine-generated data can pose a challenge when searching through logs.
Through our years of working with Stackdriver Logging users, we’ve identified the easiest ways and best practices to get the value you need from your logs. We’ve collected our favorite tips for more effective log analysis and fast troubleshooting, including a few new features to help you quickly and easily get value from your logs: saved searches, a query library, support for partition tables when exporting logs to BigQuery, and more.
1. Take advantage of the advanced query language
The default basic mode for searching Stackdriver logs is using the drop-down menus to select the resource, log, or severity level. Though this makes it incredibly easy to get started with your logs, most users gravitate toward the advanced filter to ask more complex queries, as shown here:
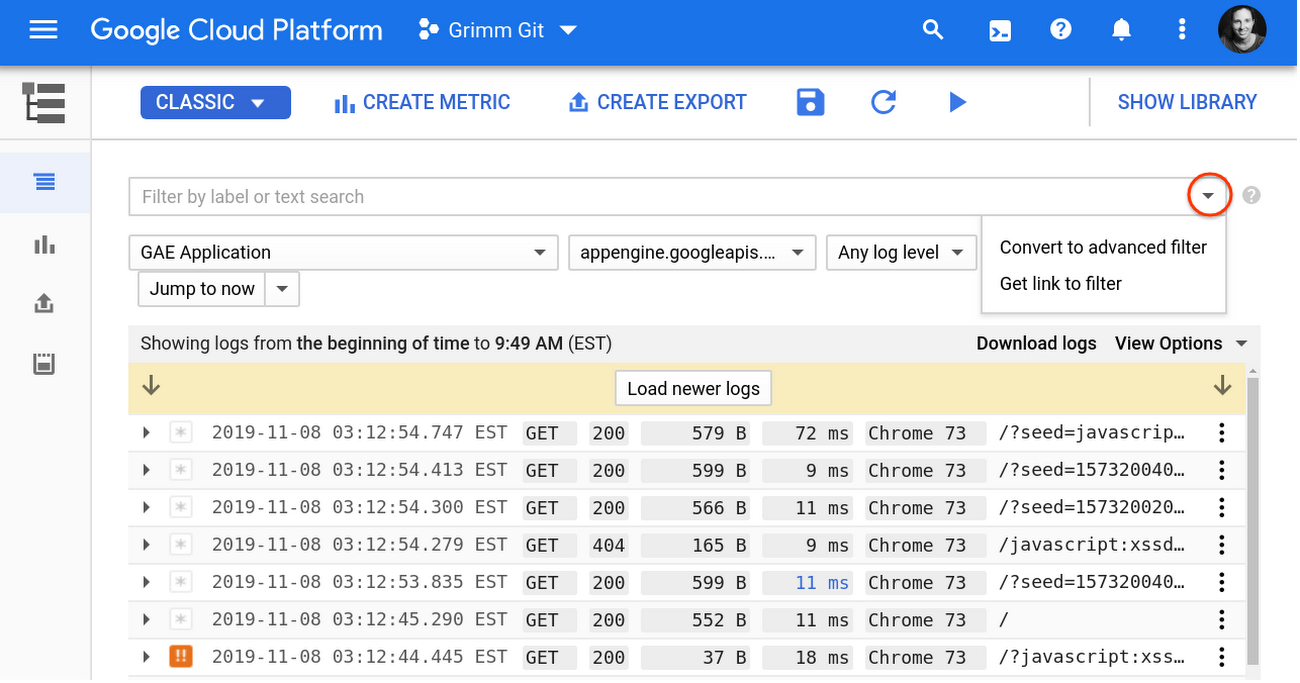
Some powerful tools in this advanced query mode include:
Comparison operators:
= # equal
!= # not equal
> < >= <= # numeric ordering
: # "has" matches any substring in the log entry fieldBoolean operators: By default, multiple clauses are combined with
AND,though you can also useORandNOT(be sure to use upper case!)Functions: ip_in_net() is a favorite for analyzing network logs, like this:
ip_in_net(jsonPayload.realClientIP, "10.1.2.0/24")
Pro tip: Include the full log name, time range, and other indexed fields to speed up your search results. See these and other tips on speeding up performance.
New queries library: We’ve polled experts from around Google Cloud to collect some of our most common advanced queries by use case including Kubernetes, security, and networking logs, which you can find in a new sample queries library in our documentation. Is there something different you’d like to see? Click the “Send Feedback” button at the top of the Sample Queries page and let us know.
2. Customize your search results
Often there is a specific field buried in your log entries that is of particular interest when you’re analyzing logs. You can customize the search results to include this field by clicking on a field and selecting “Add field to summary line.” You can also manually add, remove, or reorganize fields, or toggle the control limiting their width under View Options. This configuration can dramatically speed up troubleshooting, since you get the necessary context in summary. See an example here:
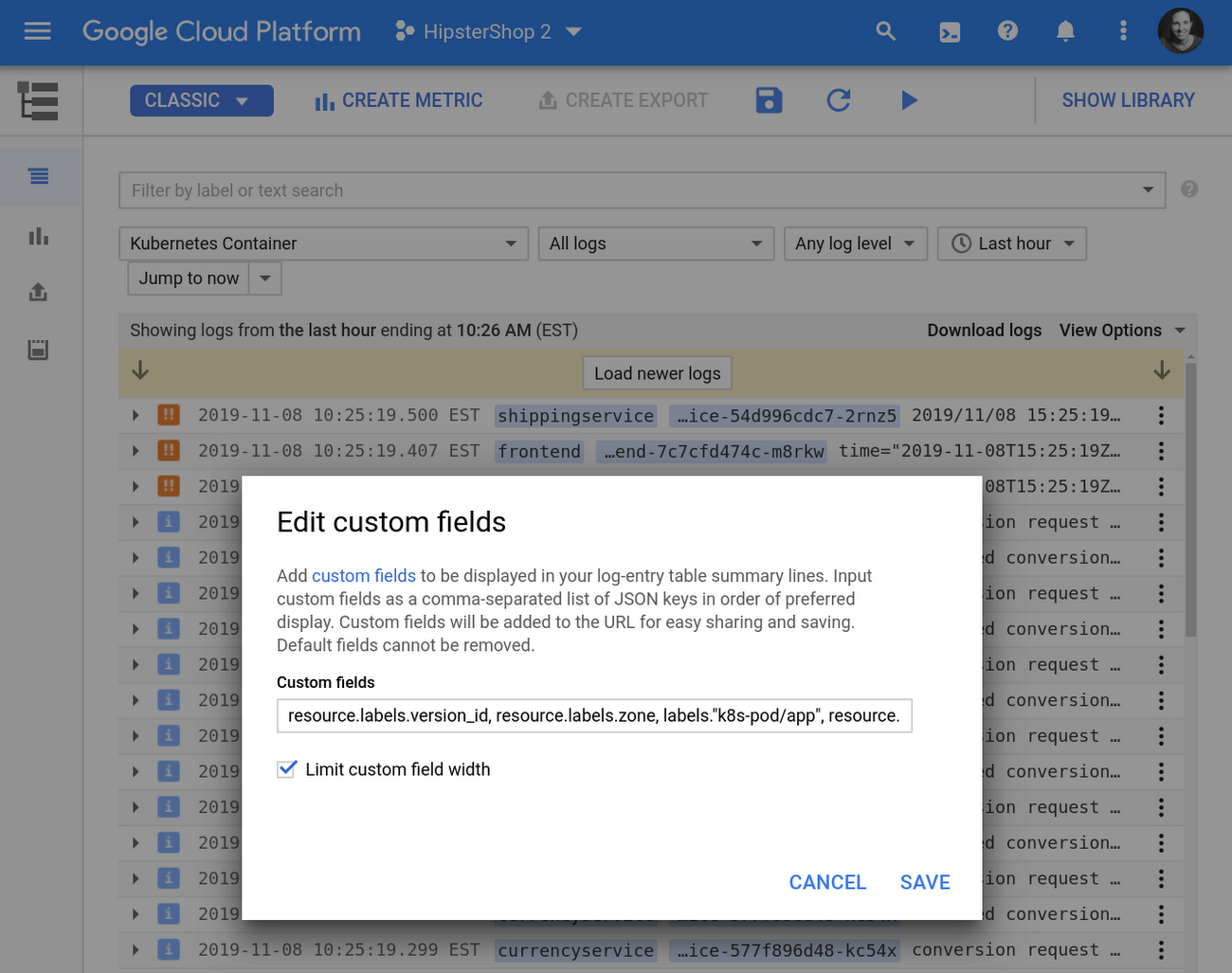
3. Save your favorite searches and custom search results in your personal search library
We often hear that you use the same searches over and over again, or that you wish you could save custom field configurations for performing future searches. So, we recently launched a new feature that lets you save your searches, including the custom fields in your own library.
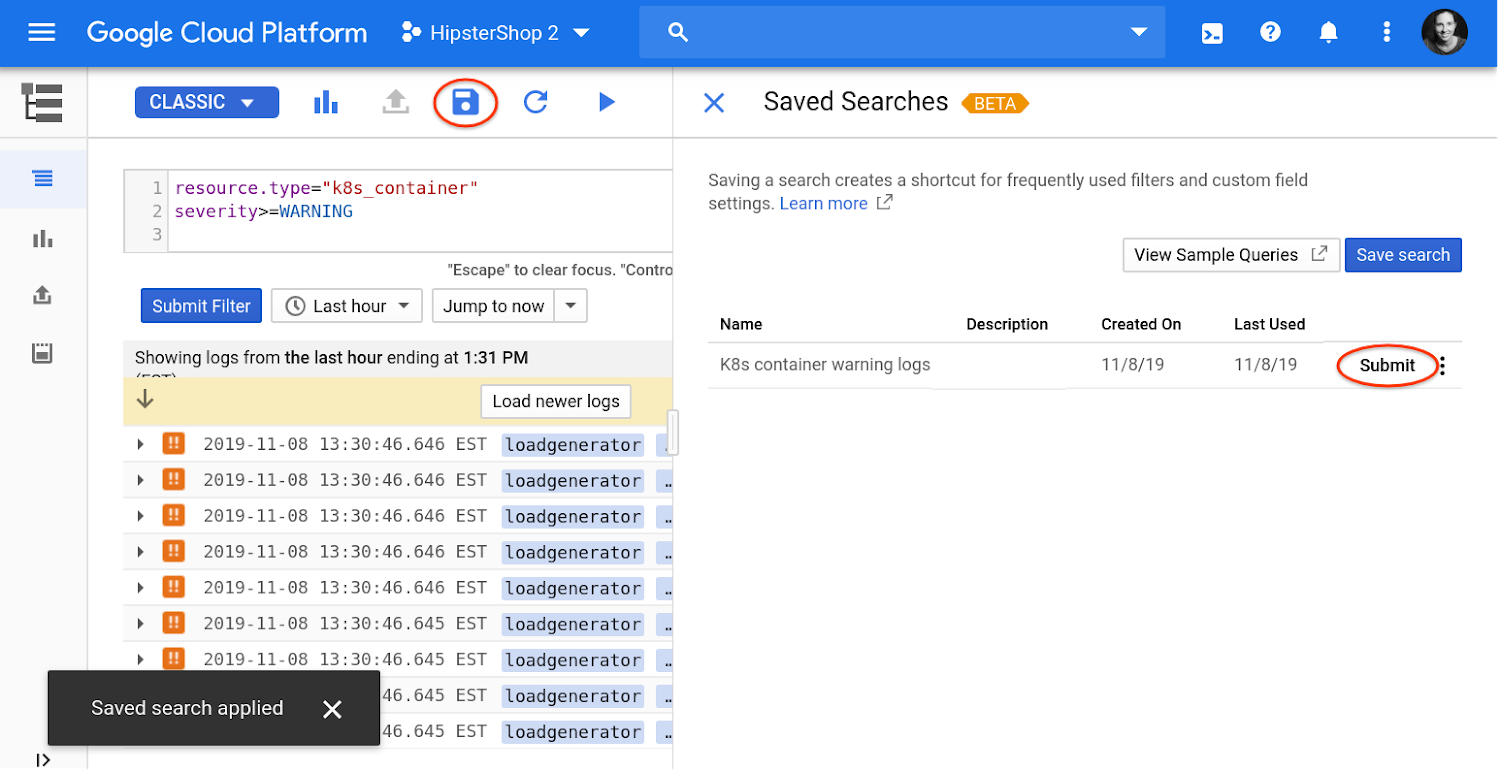
You can share your saved searches with users who have permissions on your project by clicking on the selector next to Submit and then Preview. Click the Copy link to filter and share it with your team. This feature is currently in beta, and we’ll continue working on the query library functionality to help you quickly analyze your logs.
4. Use logs-based metrics for dashboarding and alerting
Now that you’ve mastered advanced queries, you can take your analysis to the next level with real-time monitoring using logs-based metrics. For example, suppose you want to get an alert any time someone grants access to an email address from outside your organization. You can create a metric to match audit logs from Cloud Resource Manager SetIamPolicy calls, where a member not under “my-org.com” domain is granted access, as shown here:
With the filter set, simply click Create Metric and give it a name.
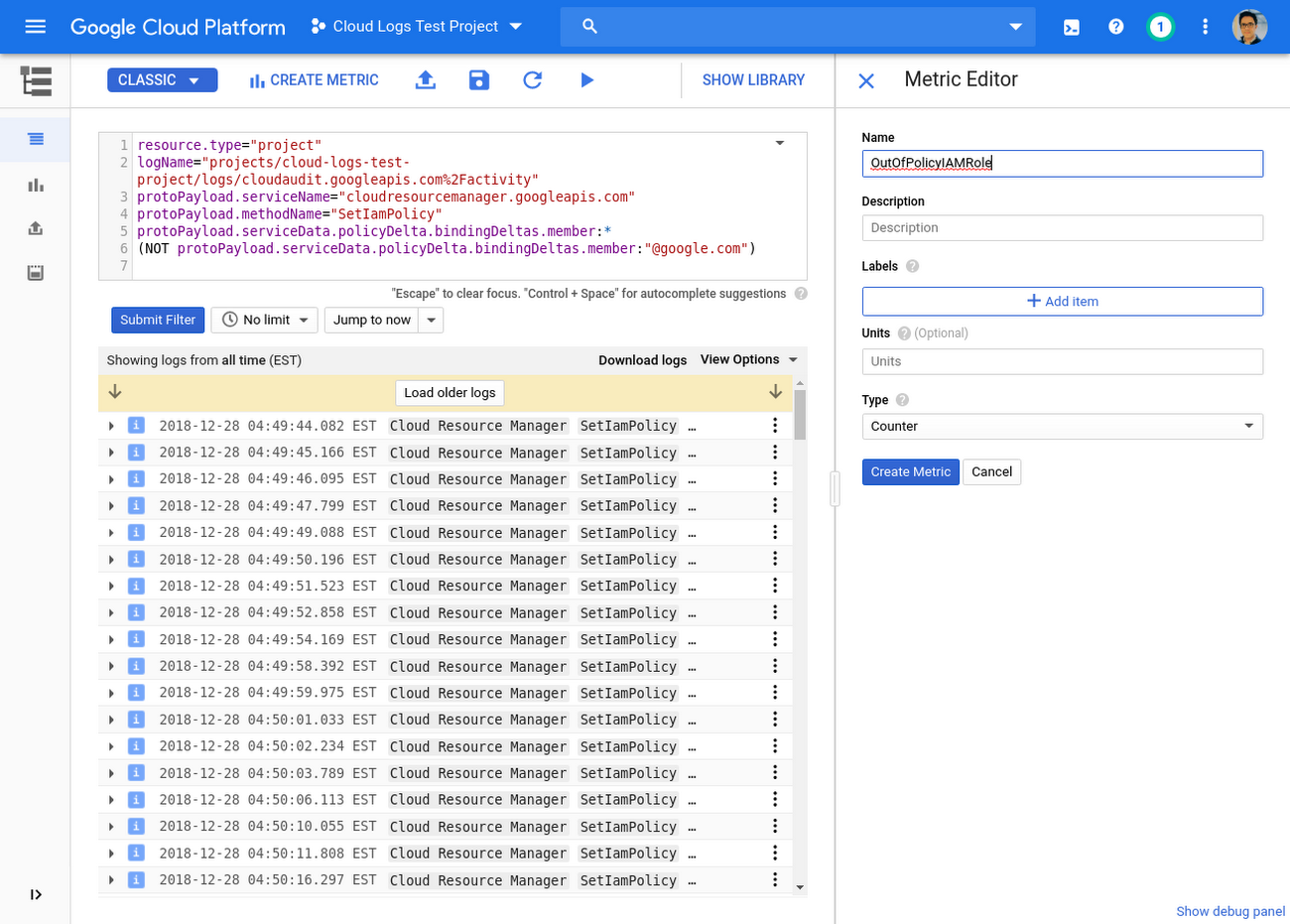
To alert if a matching log arrives, select Create Alert From Metric from the three-dot menu next to your newly created user-defined metric. This will open a new alerting policy in Stackdriver Monitoring. Change the aggregator to “sum” and the threshold to 0 for “Most recent value” so you’ll be alerted any time a matching log occurs. Don’t worry if there’s no data yet, as your metric will only count log entries since it was created.
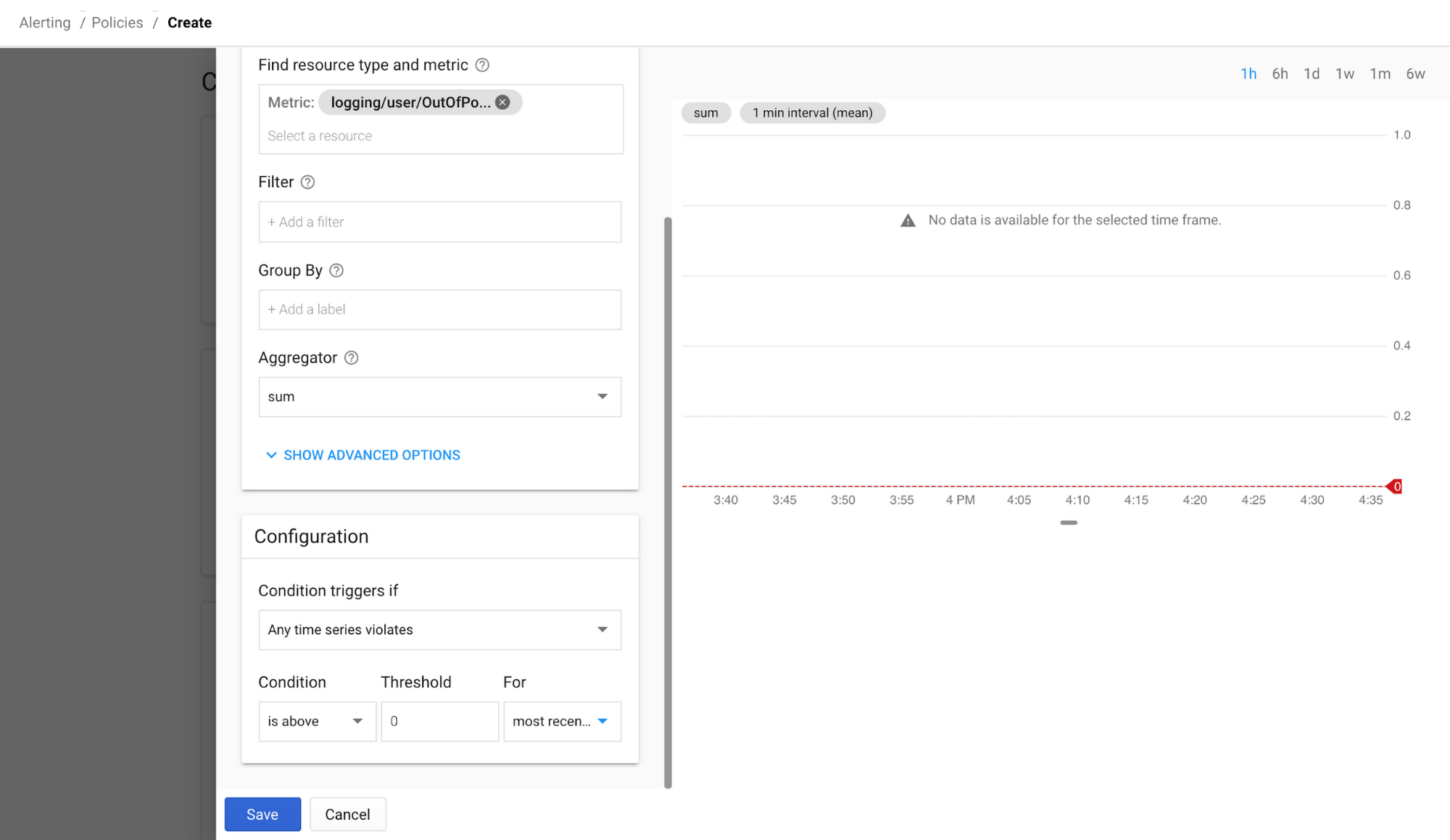
Additionally, you can add an email address, Slack channel, SMS, or PagerDuty account and name, and save your alerting policy. You can also add these metrics to dashboards along with custom and system metrics.
5. Perform faster SQL queries on logs in BigQuery using partitioned tables
Stackdriver Logging supports sending logs to BigQuery using log sinks for performing advanced analytics using SQL or joining with other data sources, such as Cloud Billing. We’ve heard from you that it would be easier to analyze logs across multiple days in BigQuery if we supported partitioned tables. So we recently added this partitioned tables option that simplifies SQL queries on logs in BigQuery.
When creating a sink to export your logs to BigQuery, you can either use date-sharded tables or partitioned tables. The default selection is a date-sharded table, in which a _YYYYMMDD suffix is added to the table name to create daily tables based on the timestamp in the log entry. Date-sharded tables have a few disadvantages that can add to query overhead:
Querying multiple days is harder, as you need to use the UNION operator to simulate partitioning.
BigQuery needs to maintain a copy of the schema and metadata for each date-named table.
BigQuery might be required to verify permissions for each queried table.
When creating a Log Sink, you can now select the Use Partitioned Tables option to make use of partitioned tables in BigQuery to overcome any issues with date-sharded tables.
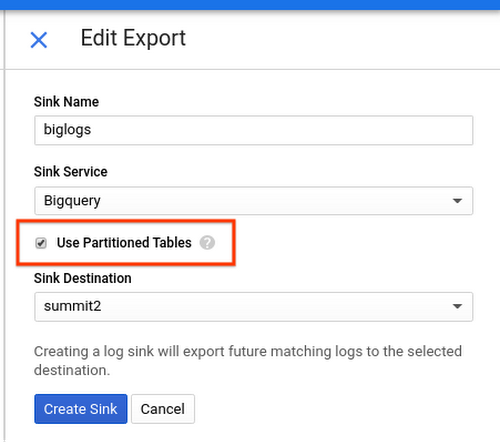
Logs streamed to a partitioned table use the log entry’s timestamp field to write to the correct partition. Queries on such ingestion-time partitioned tables can specify predicate filters on the _PARTITIONTIME or _PARTITIONDATE pseudo column to limit the amount of logs scanned. You can specify a range of dates using a WHERE filter, like this:
WHERE _PARTITIONTIME BETWEEN TIMESTAMP("20191101") AND TIMESTAMP("20191105")
Learn more about querying partitioned tables.
Find out more about Stackdriver Logging, and join the conversation directly with our engineers and product management team.



