組織の信頼性のマインドセット:Google SRE の知見
Google Cloud Japan Team
※この投稿は米国時間 2021 年 9 月 23 日に、Google Cloud blog に投稿されたものの抄訳です。
編集者注: プロダクトの信頼性は、数多くの規範的規則を守りさえすれば確保できるというものではありません。今回は、Google SRE のメンバー(開発担当シニア テクニカル プログラム マネージャーの Vartika Agarwal、シニア SRE マネージャーの Tracy Ferrell、ディレクター SRE の Mahesh Palekar、SRE 担当シニア テクニカル プログラム マネージャーの Magi Agrama)に、チームの現在の信頼性のマインドセットを評価する方法と、目指すべき姿について話を聞きました。
信頼できるソフトウェア プロダクトがあると、組織に対するユーザーからの信用、開発プロセスの有効性、プロダクト全般の品質を改善できます。サービス停止はお客様とそのビジネスに悪影響を及ぼすため、プロダクトの信頼性がこれまで以上に注目されています。しかし、新機能を開発しようとする多くの組織が、信頼性への取り組みをサービス停止後の対応のみに絞り、停止を誘発した直接的な問題を限定的に解決しています。迅速に行動すると同時にプロダクトの信頼性も改善できるということが認識されていない場合が少なくありません。
Google は、プロダクトの信頼性に対して多くの考え方を提供してきました。そのいくつかの側面、たとえばプロダクトまたはシステムの設計などに関しては十分に理解されています。ただし、第一に信頼できるプロダクトを作成するという組織の文化やマインドセットについては、それほど考慮されていません。プロダクトの信頼性は、そのシステムのアーキテクチャ、プロセス、文化の特性だけでなく、それを構築したプロダクト チームまたは組織のマインドセットを表すものであると、Google は確信しています。言い換えると、信頼性は、強固な設計精神の結果であるだけでなく、組織の基礎構造に織り込むべきです。
このブログ投稿では、エンジニアリング、プロダクト管理、マーケティング、信頼性エンジニアリング、サポート組織などから、プロダクト チーム全体の文化に影響を与えることのできる組織またはプロダクトのリードに関連して私たちが得た教訓について述べていきます。
目標
信頼性を組織運営方法の基礎構造に織り込む必要があります。Google では、信頼性に対する組織の意識を把握するための一助として、組織の信頼性マインドセットを分類して記述する用語を策定しました。Google の最終目標は、組織の精神に浸透するプロダクト信頼性の実践行動を改善して導入できるように支援することです。
Google は、これらの信頼性フェーズを特定して、プロダクト信頼性改善のために行うことの規範的リストを提供しようとしているのではありません。また、これを誰もが適用すべき義務的な原則の一式とみなしたり、チームに公然とラベル付けしてチーム間競争を助長するために使ったりすべきでもありません。リーダーは、信頼できるプロダクトを持続的に構築する途上でチーム文化の育成を支援する方法として、これらのフェーズをとらえるべきです。
組織の信頼性の連続的な流れ
Google での観察によれば、組織の信頼性には 5 つの基本的段階があります。それらは不認識、受動的、積極的、戦略的、先見的という典型的組織モデルに基づいています。これらのフェーズは、ある時点での組織のマインドセットを表します。それぞれが一連の属性によって特徴付けられ、異なるワークロード クラスに当てはまります。
不認識: 組織にとって信頼性は二次的な考慮事項です。
機能のリリースが組織の主要指標であり、インセンティブの焦点となっています。
大多数の問題はユーザーまたはテスターによって発見されます。このような組織は長期的な信頼性リスクに気づいていません。
開発速度が信頼性と引き換えられることはほとんどありません。
この信頼性フェーズは、開発中のプロダクトまたはプロジェクトに当てはまる可能性があります。
受動的: 信頼性の問題 / リスクへの対応が最近のサービス停止に結び付けられ、散発的なフォローが行われます。システムの問題の修正に長期的な投資が行われることはほとんどありません。
信頼性指標はいくつか定義されており、必要に応じて対応が行われます。
サービス停止の事後分析が書かれ、限定的修正のためのアクション アイテムが作成されます。
少数の個人またはチームの英雄的取り組みにより、相応の可用性が維持されます。
デベロッパーの生産性は、サービス停止による信頼性の取り組みの一時的な優先順位変更によって調整されます。機能の開発が短期間凍結される場合があります。
このレベルは、リリース前または安定的長期維持フェーズのプロダクト / プロジェクトに当てはまります。
積極的: 定期的な組織プロセスを通じて潜在的な信頼性リスクが特定され対処されます。
リスクが定期的に考察され優先順位付けされます。
積極的に依存関係が管理され、信頼性指標(SLO)が考察されます。
既知のリスクと障害モードに対して新しい設計が早い段階で評価されます。グレースフル デグラデーションが基本的要件となります。
信頼性への投資を継続的に行い、開発速度とのバランスを維持する必要性が理解されています。
ほとんどのサービス / プロダクトがこのレベルにあるべきです(特に、影響範囲が大きいサービス / プロダクトまたはビジネスにとって非常に重要なサービス / プロダクトの場合)。
戦略的: このレベルにある組織は、アーキテクチャ、プロダクト、プロセスを体系的に変更することでリスクのクラスを管理します。
ソフトウェアの設計、運用、開発方法に信頼性が根付いています。信頼性が浸透しています。
複雑性にはプロダクト アーキテクチャを通じて総体的に対処します。依存関係が継続的に軽減または改善されます。
複数の職能にまたがる組織は、信頼性と開発速度を同時に維持できます。
品質と安定性のマイルストーンが幅広く重要視されます。
このレベルは、ビジネス クリティカルなニーズを満たすために高い可用性を必要とするサービスおよびプロダクトに当てはまります。
先見的: 信頼性の最高位に到達しており、信頼性への幅広い取り組みをベスト プラクティスおよび経験に基づいて社内外で推進できます(たとえば書類の作成や知識の共有など)。
信頼性の知識が、すべてのエンジニアおよびチームにわたってかなり高度なレベルで広く存在し、組織間の移動に伴って進展していきます。
システムに自己回復力が備わっています。
アーキテクチャを信頼性のために改善することで、メンテナンス作業が削減され、生産性(リリースの速度)に好影響が及びます。
このレベルに到達しているサービスまたはプロダクトはほとんどありません。到達しているとしたら、それらは業界トップクラスということになります。
この信頼性スペクトラムでの位置付けはどうあるべきでしょう?
必ずしも戦略的フェーズや先見的フェーズにいる必要はないということを理解することが非常に重要です。フェーズ移行に伴ってかなりのコストがかかり、この曲線上で高位置を維持するためにもコストがかかります。Google の経験から言うと、積極的レベルが妥当であり、ほとんどのプロダクトに適しています。
それを説明するために、さまざまな Google プロダクト チームが組織の信頼性スペクトラム上に占めている位置を表した単純なグラフを示します。ご覧のとおり、標準的な釣鐘曲線分布を成しています。Google のプロダクト チームの多くが受動的または積極的な信頼性文化を持っていますが、ほとんどは積極的と表現することが可能です。組織のリーダーは、プロダクトの要件とクライアントの期待に基づいて、あるべきレベルを意識的に決める必要があります。
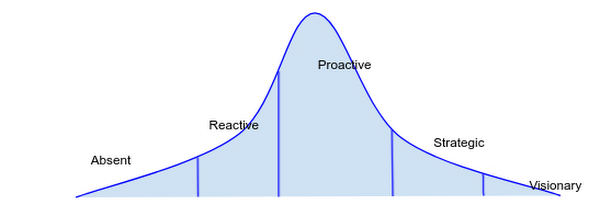
さらに、複数のフェーズにまたがる属性を持っていることも一般的です。たとえば、大部分は受動的だが少数の積極的属性を持つ組織などがあります。チームの文化は、戦略的な信頼性文化の維持に向けた努力をする中で、フェーズ間で一進一退します。しかし、組織内で信頼性を主要機能として受け入れ重要視する人々が増えるにつれて、維持コストは減少します。
成功の鍵となるのは、自分たちの現在のフェーズを率直に評価し、その後にプロダクトにとって意味あるフェーズに移行するための取り組みを協調して行うことです。自身の組織が不認識または受動的フェーズにある場合は、ライフサイクルの初期段階にある多くのプロダクトにはそれが適している可能性があることを忘れないでください(スタートアップおよび安定したプロダクトの長期的維持の両方に当てはまります)。
信頼性フェーズの実例
実際の信頼性フェーズを説明するには、組織の実例および上昇 / 下降の様子を見ていくとよいでしょう。
留意すべきなのは、企業やチームはすべて異なるということです。フェーズを通じた進展にかかる時間の長さもさまざまである可能性があります。真の意味での積極的状態に移行するのに 2~3 年かかることも珍しくありません。積極的状態では、組織の全部門が、機能リリース速度にマイナスの影響が出ることを憂慮せず信頼性に貢献しています。積極的フェーズを維持するのにも時間と努力が必要です。
誰も永遠にヒーローではいられない
わずかな API にしか精通していない状態で細々と始動したインフラストラクチャ サービスチームがありました。チームの主要メンバーであるプロダクト アーキテクトは、システムをよく理解していました。そして、物事をスムーズに運ぶためには、設計に関する決定が正当であること、およびそれぞれの重大インシデントに際して迅速に問題を緩和することが必要と断言しました。このアーキテクトは、システム全体を理解し、安定性への影響があるものとないものを予測できる人でした。ところが、彼らがチームから去ってしまうと、システムは急速に複雑さを増していきました。突然、ユーザー向けサービスと社内サービスに、重大なサービス停止が数多く起こるようになりました。
組織のリーダーは、安定性を回復させるために、短期と長期の両面で信頼性プログラムを開始しました。グローバルなサービス停止の範囲と影響を小さくすることに集中しました。リーダーは、この軌道を維持するためにはエンジニアリング ソリューションを越えて文化を変化させる(信頼性を第一の特徴と認識するなど)必要があることを認識しました。ここから、信頼性のベスト プラクティスを中心とした広範なトレーニング、アーキテクチャ / 設計の検討事項に信頼性を組み込むこと、一時的な盛り上がりにとどまらずに信頼性を認識し報奨することなどにつながりました。
その結果、組織は受動的なマインドセットから戦略的な信頼性マインドセットへと進化しました。信頼性を第一の特徴に設定し、長期的な信頼性向上を認めて報奨し、信頼性は少数のヒーローだけではなく全員の責任であるという信念を浸透させたことが、その進歩を支えました。

これで完了と思ったときにもう一度考え直す
エンドユーザーはこのプロダクトの信頼性に大きく依存しています。信頼性はユーザーからの信用に直接結び付きます。このような理由から、Google のとある組織では、長年にわたり信頼性が最重要視されてきました。他の Google チームはそのプロダクトを信頼性の絶対的基準として考えていました。この組織は、信頼性のプロセスと取り組みに関して先見的であるとみなされました。
しかし、長い年月の間に、次々と新しいプロダクトが基本サービスに追加されました。プロダクトがよりシンプルだったときのように自由自在かつ簡単には高い信頼性レベルを実現できなくなりました。信頼性が開発速度に影響されて、組織はさらに受動的な信頼性マインドセットに移行しました。
方向転換するには、信頼性に対する姿勢と全般的な実施状況(信頼性をどれだけ考慮し優先しているかなど)を組織のリーダーが意識する必要がありました。チームが戦略的マインドセットに戻るまでには数年かかりました。

信頼性の原則を始めから受け入れる
ユーザー向けの新しいプロダクトに取り組む別のチームは、機能の追加とユーザー数の拡大を重視していました。あっという間に、プロダクトが売れ始めて飛躍的に成長しました。
残念ながら、チームの重点がユーザー要件の管理と導入ユーザー数の増加のみに絞り込まれていたことが、大きな技術的負担と信頼性の問題につながりました。サービス始動時に信頼性を主要重点事項としていなかったため、後からそれを組み込むのは非常に困難でした。
維持可能な状態に達するためには、コードの多くを書き直して再設計する必要がありました。チームのリーダーは、プロダクト管理から開発および UX ドメインに至るまで、組織全体に対して信頼性への配慮を奨励し、プロダクトの長期的成功にとって信頼性が重要であることを絶えず組織に想起させました。このマインドシフトが定着するまでに数年間かかりました。

結論
複数の職能にまたがる組織の場合、自身の信頼性の道程を率直に見つめビジネスとプロダクトに何が適しているのかを判断することが重要です。プロダクトが成熟して安定し、やがては次世代に道を譲ることになるなど、組織のレベルが行き戻りすることも珍しくありません。戦略的レベルに到達するには 4 年以上かかることがあり、ビジネスのあらゆる局面から非常に高いレベルの投資が必要になります。リーダーは、自身のプロダクトにこのレベルの持続的投資が必要であるかを確認すべきです。
Google からの助言として、信頼性の文化を学び、現在のフェーズを評価し、どの段階に行くべきかを判断して、熟慮の上で慎重に移行することをおすすめします。文化を変えることは困難であり、命令や罰で実現できるものではありません。特に覚えておいていただきたいのは、これは一種の旅でありビジネスは絶えず進化するということです。信頼性とは、棚に置いたままでいつまでも自然に維持されるものではありません。
- Google サイト信頼性エンジニアリング チーム



