What’s your org’s reliability mindset? Insights from Google SREs
Google Site Reliability Engineering team
Editor’s note: There’s more to ensuring a product’s reliability than following a bunch of prescriptive rules. Today, we hear from some Google SREs—Vartika Agarwal, Senior Technical Program Manager, Development; Tracy Ferrell, Senior SRE Manager; Mahesh Palekar, Director SRE; and Magi Agrama, Senior Technical Program Manager, SRE—about how to evaluate your team’s current reliability mindset, and what you want it to be.
Having a reliable software product can improve users’ trust in your organization, the effectiveness of your development processes, and the quality of your products overall. More than ever, product reliability is front and center, as outages negatively impact customers and their businesses. But in an effort to develop new features, many organizations limit their reliability efforts to what happens after an outage, and tactically solve for the immediate problems that sparked it. They often fail to realize that they can move quickly while still improving their product’s reliability.
At Google, we’ve given a lot of thought to product reliability—and several of its aspects are well understood, for example product or system design. What people think about less is the culture and the mindset of the organization that creates a reliable product in the first place. We believe that the reliability of a product is a property of the architecture of its system, processes, culture, as well as the mindset of the product team or organization that built it. In other words, reliability should be woven into the fabric of an organization, not just the result of a strong design ethos.
In this blog post, we discuss the lessons we’ve learned relevant to organizational or product leads who have the ability to influence the culture of the entire product team, from (but not limited to) engineering, product management, marketing, reliability engineering, and support organizations.
Goals
Reliability should be woven into the fabric of how an organization executes. At Google, we’ve developed a terminology to categorize and describe your organization’s reliability mindset, to help you understand how intentional your organization is in this respect. Our ultimate goal is to help you improve and adopt product reliability practices that will permeate the ethos of the organization.
By identifying these reliability phases, we do not mean to offer a prescriptive list of things to do that will improve your product’s reliability. Nor should they be read as a set of mandated principles that everyone should apply, or be used to publicly label a team, spurring competition between teams. Rather, leaders should consider these phases as a way to help them develop their team’s culture, on the road to sustainably building reliable products.
The organizational reliability continuum
Based on our observations here at Google, there are five basic stages of organizational reliability, and they are based on the classic organizational model of absent, reactive, proactive, strategic and visionary. These phases describe the mindset of an organization at a point in time, and each one of them is characterized by a series of attributes, and is appropriate for different classes of workloads.
Absent: Reliability is a secondary consideration for the organization.
A feature launch is the key organizational metric and is the focus for incentives
The majority of issues are found by users or testers. This organization is not aware of their long-term reliability risks.
Developer velocity is rarely exchanged for reliability.
This reliability phase maybe appropriate for products and projects that are still under development.
Reactive: Responses to reliability issues/risks are tied to recent outages with sporadic follow-through and rarely are there longer-term investments in fixing system issues.
- Teams have some reliability metrics defined and react when required.
- They write postmortems for outages and create action items for tactical fixes.
- Reasonable availability is maintained through heroic efforts by a few individuals or teams
- Developer productivity is throttled due to a temporary shift in priority on reliability work due to outages. Feature development may be frozen for a short period of time.
This level is appropriate for products/projects in pre-launch or in a stable long-term maintenance phase.
Proactive: Potential reliability risks are identified and addressed through regular organizational processes.
- Risks are regularly reviewed and prioritized.
- Teams proactively manage dependencies and review their reliability metrics (SLOs)
- New designs are assessed for known risks and failure modes early on. Graceful degradation is a basic requirement.
- The business understands the need to continuously invest in reliability and maintain its balance with developer velocity.
Most services/products should be at this level; particularly if they have a large blast radius or are critical to the business.
Strategic: Organizations at this level manage classes of risk via systemic changes to architectures, products and processes.- Reliability is inherent and ingrained in how the organization designs, operates and develops software. Reliability is systemic.
- Complexity is addressed holistically through product architecture. Dependencies are constantly reduced or improved.
- The cross-functional organization can sustain reliability and developer velocity simultaneously.
- Organizations widely celebrate quality and stability milestones.
This level is appropriate for services and products that need very high availability to meet business-critical needs.
Visionary: The organization has reached the highest order of reliability and is able to drive broader reliability efforts within and outside the company (e.g., writing papers, sharing knowledge), based on their best practices and experiences.- Reliability knowledge exists broadly across all engineers and teams at a fairly advanced level and is carried forward as they move across organizations.
- Systems are self-healing.
- Architectural improvements for reliability positively impact productivity (release velocity) due to reduction of maintenance work/toil.
Very few services or products are at this level, and when they are, are industry leading.
Where should you be on the reliability spectrum?
It is very important to understand your organization does not necessarily need to be at the strategic or visionary phase. There is a significant cost associated with moving from one phase to another and a cost to remain very high on this curve. In our experience, being proactive is a healthy level to target and is ideal for most products.
To illustrate this point, here is a simple graph of where various Google product teams are on the organizational reliability spectrum; as you can see, it produces a standard bell-curve distribution. While many Google’s product teams have a reactive or proactive reliability culture, most can be described as proactive. You, as an organizational leader, must consciously decide to be at a level based on the product requirements and client expectations.
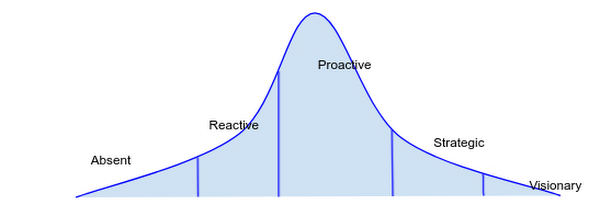
Further, it’s common to have attributes across several phases, for example, an organization may be largely reactive with a few proactive attributes. Team culture will wax and wane between phases, as it takes effort to maintain a strategic reliability culture. However, as more of the organization embraces and celebrates reliability as a key feature, the cost of maintenance decreases.
The key to success is making an honest assessment of what phase you’re in, and then doing concerted work to move to the phase that makes sense for your product. If your organization is in the absent or reactive phase, remember that many products in nascent stages of their life cycle may be comfortable there (in both the startup and long term maintenance of a stable product).
Reliability phases in action
To illustrate the reliability phases in practice, it is interesting to look at examples of organizations and how they have progressed or regressed through them.
It should be noted that all companies and teams are different and the progress through these phases can take varying amounts of time. It is not uncommon to take two to three years to move into a truly proactive state. In a proactive state all parts of the organization contribute to reliability without worrying that it will negatively impact feature velocity. Staying in the proactive phase also takes time and effort.
Nobody can be a hero forever
One infrastructure services team started small with a few well understood APIs. One key member of the team, a product architect, understood the system well and ensured that things ran smoothly by ensuring design decisions were sound and being at each major incident to rapidly mitigate the issue. This was the one person who understood the entire system and was able to predict what can and cannot impact its stability. But when they left the team, the system complexity grew by leaps and bounds. Suddenly there were many critical user-facing and internal outages.
Organizational leaders initiated both short and long-term reliability programs to restore stability. They focused on reducing the blast radius and the impact of global outages. Leadership recognized that to sustain this trajectory, they recognized that they had to go beyond engineering solutions and implement cultural changes such as recognizing reliability as their number-one feature. This led to broad training around reliability best practices, incorporating reliability in architectural/design reviews and recognizing and rewarding reliability beyond hero moments.
As a result, the organization evolved from a reactive to a strategic reliability mindset, aided by setting reliability as their number-one feature, recognizing and rewarding long-term reliability improvements, and adopting the systemic belief that reliability is everyone’s responsibility—not just that of a few heroes.

If you think you are done, think again
End users are highly dependent on the reliability of this product and it ties directly to user trust. For this reason, reliability was top of mind for one Google organization for years, and the product was held as the gold standard of reliability by other Google teams. The org was deemed visionary in its reliability processes and work.
However, over the years, new products were added to the base service. The high level of reliability did not come as freely and easily as it did with the simpler product. Reliability was impacted at the cost of developer velocity and the organization moved to a more reactive reliability mindset.
To turn the ship around, the organization’s leaders had to be intentional about their reliability posture and overall practices, for example, how much they thought about and prioritized reliability. It took several years to move the team back to a strategic mindset.

Embrace reliability principles from the start
Another team with a new user-facing product was focused on adding features and growing their user base. Before they knew it, the product took off and saw exponential growth.
Unfortunately, their laser-focus on managing user requirements and growing user adoption led to high technical debt and reliability issues. Since the service didn’t start off with reliability as a primary focus, it was very hard to incorporate it after the fact.
Much of the code had to be re-written and re-architected to reach a sustainable state. The team’s leaders incentivized attention to reliability throughout the organization, from product management through to development and UX domains, constantly reminding the organization about the importance of reliability to the long-term success of the product. This mindshift took years to set in.

Conclusion
It is important that cross-functional organizations be honest about their reliability journeys and determine what is appropriate for their business and product. It is not uncommon for organizations to move from one level to another and then back again as the product matures, stabilizes and then is sunset for the next generation. Getting to a strategic level can be 4+ years in the making and require very high levels of investment from all aspects of the business. Leaders should ensure their product requires this level of continued investment.
We encourage you to study your culture of reliability, assess what phase you are in, determine where you should be on the continuum and carefully and thoughtfully move there. Changing culture is hard and can not be done by edicts or penalties. Most of all, remember that this is a journey and the business is ever-evolving; you cannot set reliability on the shelf and expect it to maintain itself in perpetuity.



