GenOps: マイクロサービスと従来の DevOps の世界から学ぶ
Sam Weeks
AI/ML Customer Engineer, UKI, Google Cloud
※この投稿は米国時間 2024 年 8 月 31 日に、Google Cloud blog に投稿されたものの抄訳です。
生成 AI アプリケーションは誰が管理すべきでしょうか。AI 関連の所有権はデータチームが持つことが多いものの、生成 AI アプリケーションに固有の要件はデータチームや AI チームの要件とは明らかに異なり、DevOps チームとの類似点が多いこともあります。このブログ投稿では、これらの類似点と相違点を探り、生成 AI アプリケーション独自の特性を扱う新たな「GenOps」チームの必要性について検討します。
「データからモデルを作成する」ことを目的とするデータ サイエンスとは対照的に、生成 AI は「モデルから AI 対応サービスを作成する」ことに関連しており、既存のデータ、モデル、API の統合に関与するものです。このように見ると、生成 AI は従来のマイクロサービス環境、すなわち複数の互いに異なる分離された相互運用可能なサービスが API を介して消費される環境に似ているように感じられます。そして、特徴に類似点がある場合、それらは共通の運用要件を持つのが道理にかなっています。では、マイクロサービスと DevOps の世界から新しい GenOps の世界にどのようなプラクティスを取り入れることができるのでしょうか。
何を運用化するのか: AI エージェントとマイクロサービスの比較
生成 AI アプリケーションの運用要件は他のアプリケーションとどのように違うのでしょうか。従来のアプリケーションでは、運用化の単位はマイクロサービスです。これは、コンテナにパッケージ化され、Kubernetes のようなコンテナネイティブのランタイムにデプロイされた個別の機能的なコード単位です。生成 AI アプリケーションの場合、比較対象となる単位は生成 AI エージェントです。これも、ある特定のタスクを処理するために定義された個別の機能的なコード単位ですが、単なるマイクロサービスではなく、以下の構成要素が追加されています。この追加の構成要素により、生成 AI エージェントは「処理と出力の両面で非決定論的である」というマイクロサービスとは異なる挙動をとります。
-
推論ループ - エージェントが何を行い、どのように機能するのかを定義する制御ロジック。これには多くの場合、初期タスクを、タスクの完了に向けて実行される一連のモデル駆動ステップに分解するための反復ロジックまたは思考チェーンが含まれます。
-
モデル定義 - モデルとのやり取りのために定義されたアクセス パターンの 1 つまたはそのセット。これを推論ループで読み取って使用できます。
- ツール定義 - 他のエージェント、データアクセス(RAG)フロー、外部 API といったエージェントの外部にある他のサービスに対して定義されたアクセス パターンのセット。これらはエージェント間で共有され、API を通じて公開されるため、ツール定義は OpenAPI 仕様などの機械で読み取り可能な標準の形式をとります。

生成 AI エージェントの論理的構成要素
推論ループは本質的にマイクロサービスのスコープ全体であり、そこにモデル定義とツール定義が加わってマイクロサービスを超えたものになります。重要なのは、推論ループのロジックは単なるコードなので本質的に決定論的ですが、非決定論的な AI モデルからのレスポンスによって駆動されること、そしてこの非決定論的な性質がツールの必要性を生み出すということです。これは、タスクの遂行に使用する外部サービスをエージェントが「自ら選択する」ことによります。完全に決定論的なマイクロサービスでは、このような、ツールを選択するための「クックブック」は必要ありません。なぜなら、外部サービスの呼び出しは事前に決定されていて、推論ループにハードコードされているからです。
しかしそれでも、両者には多くの類似点があります。マイクロサービスと同様に、エージェントは、
-
マルチテナンシー パターンで複数のアプリ / ユーザー / チームの間で共有される個別の機能単位です。
-
開発アプローチの柔軟性が高く、幅広いソフトウェア言語が使用可能で、あるエージェントを別のエージェントとは異なる方法で構築できます。
-
エージェント間の相互依存性が非常に低く、各エージェントの開発ライフサイクルは独立した CI / CD パイプラインによって分離されています。あるエージェントをアップグレードしても、別のエージェントに影響は及びません。
運用プラットフォームと責任の分離
もう一つの重要な違いは、サービス ディスカバリです。この問題は、マイクロサービスの世界ではすでに解決しています。マイクロサービスが互いに通信するために可用性、所在、ネットワーキングの考慮事項を追跡するという非実用的な側面はマイクロサービス自体から取り除かれ、マイクロサービスをコンテナにパッケージ化して Kubernetes と Istio の共通プラットフォーム レイヤにデプロイするという形で処理されました。生成 AI エージェントでは、このような標準的なデプロイ ユニットへの整理統合はまだ実現されていません。生成 AI エージェントを構築してデプロイする方法は、コードファーストの DIY アプローチからノーコードのマネージド エージェント ビルダー環境まで、さまざまに存在します。私は原則としてこれらのツールに反対してはいませんが、その結果生まれたデプロイ環境は今日のマイクロサービス アプリケーションで見られるものよりも異種混交性の高いものとなっており、これが将来的に運用上の複雑さをもたらすと予想しています。
これに対処するには、少なくとも現時点では、マイクロサービスに見られるポイントツーポイント モデルから脱却してハブアンドスポーク モデルを採用する必要があります。ハブアンドスポーク モデルでは、エージェント、ツール、モデルの検出は API ゲートウェイ上に公開された API を介して行われ、この API ゲートウェイが、上記のような不整合な環境の上位で不整合を吸収する抽象化レイヤとなります。
これは、開発チームが構築したアプリやエージェントと生成 AI に固有のモデルやツールなどのコンポーネントとの間で責任を明確に分離するというさらなる利点をもたらします。
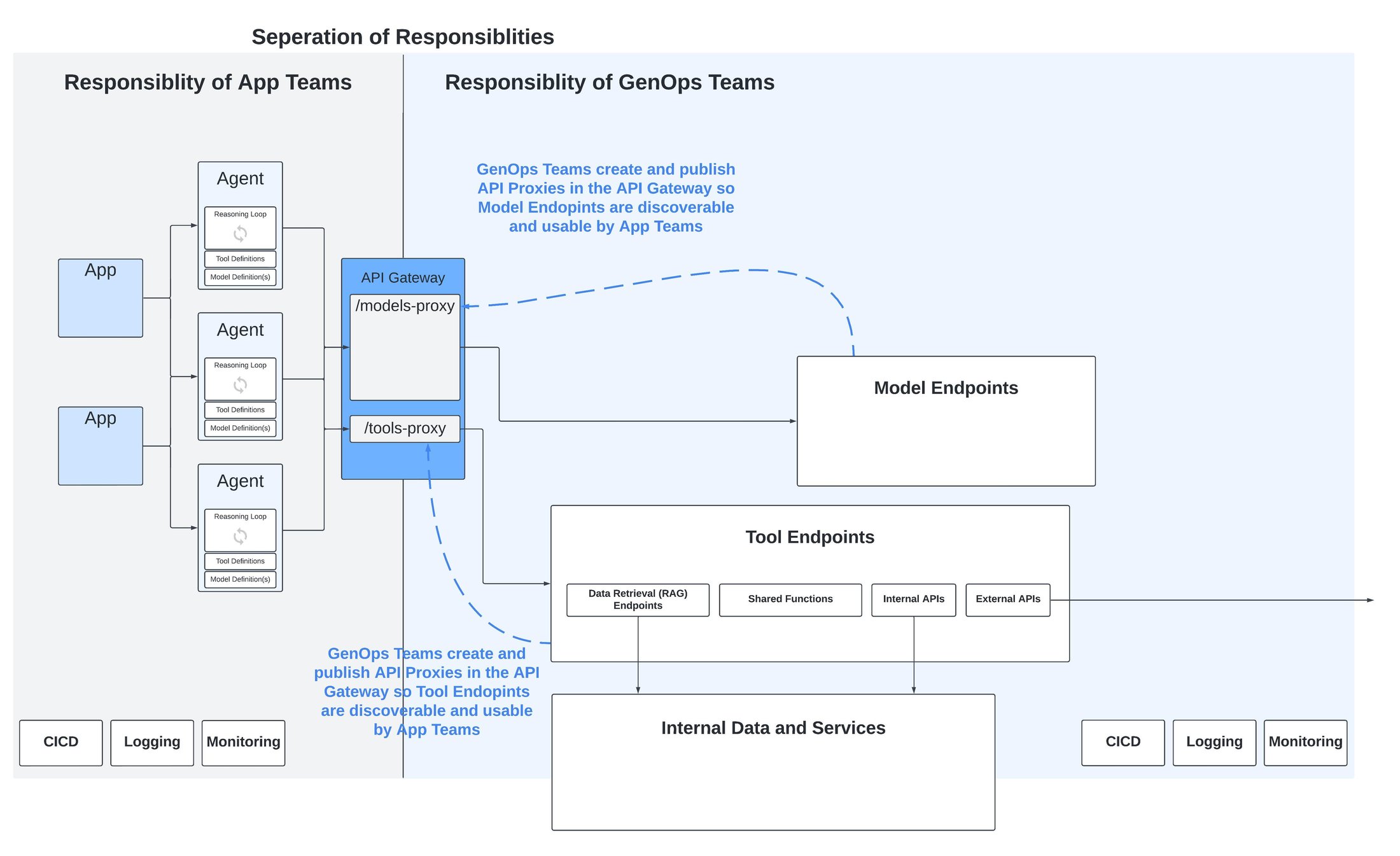
API ゲートウェイによる責任の分離
すべての運用プラットフォームでは、アプリ / マイクロサービス開発チームの役割や責任と運用チームの責任との間に明確な区別を設ける必要があります。マイクロサービス ベースのアプリケーションでは、責任はデプロイの時点で引き継がれ、焦点は信頼性、スケーラビリティ、インフラストラクチャの効率、ネットワーキング、セキュリティなどの非機能要件に移ります。
これらの要件の多くは、生成 AI アプリにとっても同様に重要です。私はこれ以外にも、生成エージェントや生成アプリに固有の、特定の運用ツールを必要とする考慮事項が存在すると考えています。これには以下が含まれます。
1. モデルのコンプライアンスと承認管理世の中には数多くのモデルがあります。オープンソースのものもあれば、ライセンス付きのものもあります。知的財産の補償を提供するものもあれば、提供しないものもあります。いずれのモデルにも特有の複雑な使用条件があり、それらは大きな問題をもたらす可能性を秘めているものの、完全に理解するには時間と適切なスキルが必要です。
モデルの選択時にデベロッパーがこれらの考慮事項を検討する時間や必要な知識を持っていることを期待するのは合理的ではなく、適切でもありません。その代わりに、モデルのレビューと承認のプロセスをデベロッパーから切り離し、そこでモデルの使用条件が今後の使用にとって許容できるかどうかを判断する方が得策です。このプロセスは、法務およびコンプライアンス チームをオーナーとし、開発環境にまで及ぶ明確で管理可能かつ監査可能な承認 / 却下プロセスによって技術レベルで支えられている必要があります。
2. プロンプトのバージョン管理モデルごとにプロンプトを最適化する必要があります。アプリチームは、プロンプトの最適化と優れたアプリの構築のどちらに重点を置くべきでしょうか。プロンプト管理は非機能コンポーネントであり、プロンプトはアプリのソースコードから切り離して集中管理する必要があります。これにより、プロンプトの最適化や定期的な評価を行い、アプリやエージェントの間でプロンプトを再利用できます。
3. モデル(およびプロンプト)の評価MLOps プラットフォームと同様に、特定のユースケースに最適なモデルをデータに基づいて評価および選択するアプローチを可能にするには、モデルのレスポンス品質を継続的に評価する必要があります。生成 AI モデルでの主な違いは、従来の ML モデルのスキューおよびドリフト検出の定量分析と比較して、評価が本質的により定性的であることです。
人間による主観的な定性的評価は明らかに拡張可能ではなく、複数名で実施すると一貫性がなくなります。その代わりに、AI 評価ツールを基盤とする一貫した自動化パイプラインが必要です。これは、不完全ではあるものの、評価に一貫性をもたらし、モデル同士を比較するためのベースラインとなります。
4. モデルのセキュリティ ゲートウェイ私が聞いた中で、大企業が時間を投資している最も一般的な運用機能は、セキュリティ プロキシです。これは、プロンプトをモデルに渡す前の安全性チェックを行い、さらに生成されたレスポンスをクライアントに返す前にチェックするという役割を担っています。
一般的な考慮事項:
-
LLM に関する OWASP トップ 10 に挙げられたプロンプト インジェクション攻撃やその他の脅威
-
有害なプロンプト / 非倫理的なプロンプト
-
モデルやその他の下流システムに送る前に秘匿化する必要がある顧客の個人情報などのデータ
一部のモデルにはセキュリティ コントロールが組み込まれていますが、これは不整合を生み出し、複雑さを増加させます。整合性を確保し、モデルの切り替えを容易にするには、モデルにセキュリティ コントロールを組み込むのではなく、モデルに依存しない抽象化されたセキュリティ エンドポイントをすべてのモデルの上位に配置する必要があります。
5. ツールの集中管理最後に、エージェントが使用可能なツールは、再利用と集中管理を可能にするためにエージェントから抽象化する必要があります。これは、特にデータへのアクセスを制御しなければならないデータ取得パターンが関係する場合に、適切な責任の分離を確立します。
RAG パターンは、数が増えて複雑化する可能性があり、また実際には特に堅牢でなく十分なメンテナンスもされていないため、大きな技術的負債を引き起こす可能性があります。したがって、データアクセス パターンを可能な限りクリーンかつ可視的にするために、集中管理することが重要です。
これらの考慮事項に加えて、前提条件としてすでに説明したように、API ゲートウェイ自体により、生成 AI 固有のサービスの上位に整合性と抽象化を提供するレイヤを構築する必要があります。API ゲートウェイをフルに活用すると、単なる API エンドポイントをはるかに超えた役割を果たし、一連の中間 API 呼び出しとロジック、セキュリティ機能、使用状況モニタリングのための調整およびパッケージング ポイントとして機能します。
たとえば、モデルにリクエストを送信するための公開 API は、次のような複数のステップからなるプロセスの出発点になります。
-
そのユースケースとモデルに最適なプロンプト テンプレートを取得して「ハイドレート」する
-
モデル安全性サービスによるセキュリティ チェックを実行する
-
リクエストをモデルに送信する
-
モデルやプロンプトの評価パイプラインなどの運用プロセスで使用するために、プロンプト、レスポンス、その他の情報を保持する
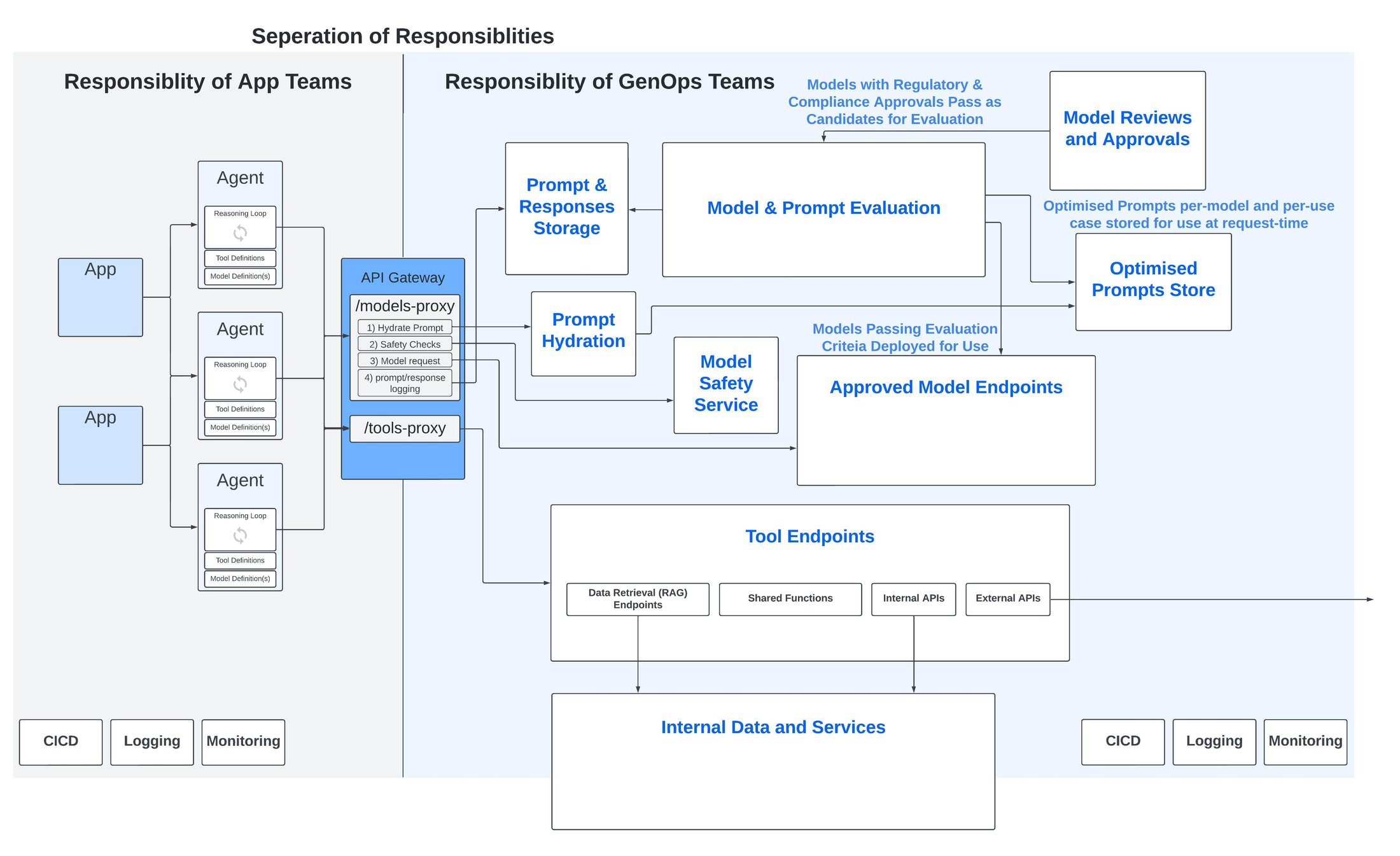
GenOps プラットフォームの主要なコンポーネント
Google Cloud で GenOps を実現する
上記の各考慮事項に対して、Google Cloud は、生成 AI アプリケーションとエージェントの評価、デプロイ、保護、アップグレードをサポートする独自の差別化されたマネージド サービスを提供しています。
-
モデルのコンプライアンスと承認管理 - Google Cloud の Model Garden は、150 を超える Google 製モデル、パートナー モデル、オープンソース モデルを集中管理しているモデル ライブラリで、Hugging Face との直接統合を通じてさらに数千のモデルを使用できます。
-
モデルのセキュリティ - 新たに発表された Model Armor(第 3 四半期にプレビュー版が提供される予定)は、基盤モデルのプロンプトとレスポンスの検査、ルーティング、保護を可能にします。これは、プロンプト インジェクション、ジェイルブレイク、有害コンテンツ、センシティブ データ漏洩などのリスクの軽減に役立ちます。
-
プロンプトのバージョン管理 - Google Cloud Next '24 において、まもなくプロンプト管理機能が提供されることが発表されました。これには、集中バージョン管理、テンプレート化、ブランチ化、プロンプトの共有などの機能が含まれます。また、プロンプトを批評して自動的に書き直す AI プロンプト支援機能も紹介されました。
-
モデル(およびプロンプト)の評価 - Google Cloud のモデル評価サービスは、さまざまな指標を基準にプロンプトとレスポンスを自動的に評価します。そのため、特定の入力に対する 2 つのモデルのレスポンスや、2 つの異なるプロンプトに対する同じモデルのレスポンスを評価するなど、拡張可能な評価パターンが可能になります。
-
ツールの集中管理 - ツールの作成をサポートする包括的なマネージド サービス スイートが用意されています。特記すべきものとしては、インテリジェントなドキュメント チャンキングを可能にする Document AI Layout Parser、Multimodal Embeddings API、Vertex AI ベクトル検索が挙げられますが、私が特に注目したいのは Vertex AI Search です。これは、ドキュメントの解析とチャンキングからエンベディングの作成と保存までのあらゆる複雑さを処理する、フルマネージドのエンドツーエンド OOTB RAG サービスです。
API ゲートウェイに関しては、Google Cloud の Apigee を使用することで、モデルとツールを API プロキシとして公開できます。これには、複数のダウンストリーム API 呼び出しに加えて、条件付きロジック、再試行、セキュリティ / 使用状況モニタリング / クロスチャージのためのツールも含めることができます。
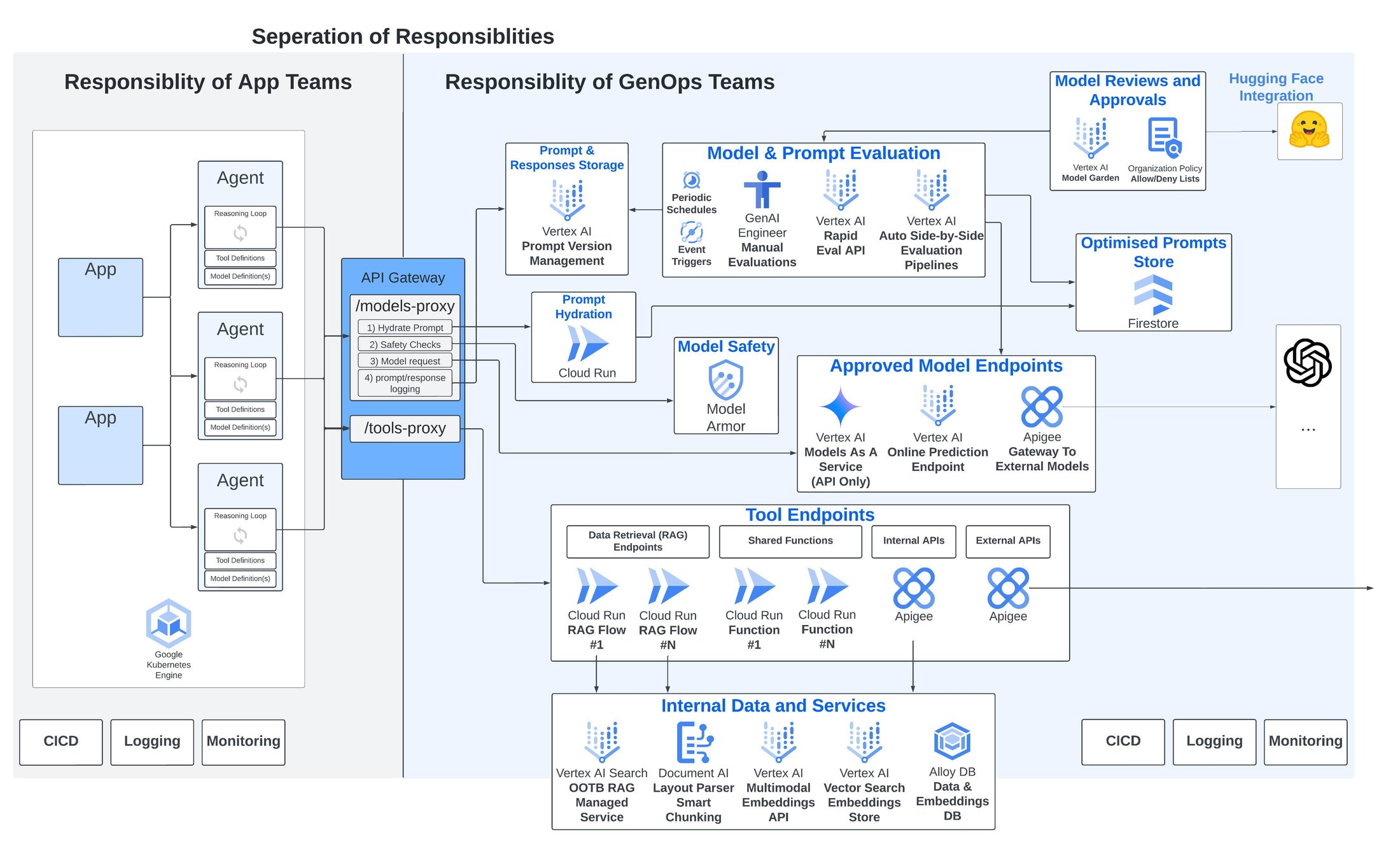
Google Cloud による GenOps
組織の規模を問わず、生成 AI で成果を上げるには生成 AI アプリケーション独自の特性と要件をうまく管理する必要があり、したがってそれらの特性と要件を扱えるように設計された運用プラットフォームが必要になります。このブログで論じたポイントが、この刺激的でインパクトの強い新たなテクノロジーの時代を生き抜くうえで皆様のお役に立てば幸いです。
このトピックについてさらに詳しくお知りになりたい場合は、担当の Google Cloud アカウント チーム(該当する場合)にお問い合わせいただくか、私に直接ご連絡ください。
ー AI / ML カスタマー エンジニア Sam Weeks



