複合可用性: クラウド インフラストラクチャの全体的な可用性の計算
Google Cloud Japan Team
※この投稿は米国時間 2022 年 11 月 16 日に、Google Cloud blog に投稿されたものの抄訳です。
クラウド システムを設計する際に、信頼性は重要な考慮事項です。インフラストラクチャ アーキテクトとして、お客様が内部ユーザーであるかエンドユーザーであるかにかかわらず、何を保証したいのかについて検討します。また、サービスの停止を許容できる時間はどれくらいか、復元力を備えたサービスをどのように設計するかについて検討します。
信頼性の大部分は、可用性(「稼働時間」または「稼働時間の可用性」とも呼ばれます)に依存します。Google Cloud ブログ投稿「可用性とどう向き合うべきか、それが問題だ : CRE が現場で学んだこと」において、可用性とは、システムがある時点で意図された機能を果たすことができるかどうかであると定義されています。言い換えると、ウェブページが訪問者にコンテンツを提供できる割合はどれくらいか、そのリンクにアクセスしたとき、レイテンシはさておき、常にウェブページが表示されるかということです。
サービスの可用性、SLA、SLO
通常、サービスの可用性は、成功したユニット数 ÷ 合計ユニット数で計算されます。つまり、稼働時間 ÷ (稼働時間 + ダウンタイム)、または、成功したリクエスト ÷ (成功したリクエスト + 失敗したリクエスト) などです。可用性は、システムが将来期待どおりに動作する確率を検証するための報告ツールおよび確率ツールとして機能します。可用性は 99.99% など、パーセントで報告されます。例:「当ウェブページは 99.99% の確率で訪問者にコンテンツを提供しています。」
Google Cloud 内では、サービスとプロダクトに、目標の可用性を記述する独自のサービスレベル契約(SLA)があります。たとえば、適切に構成されている場合、単一ゾーンの 1 つの Compute Engine インスタンスの月間稼働率は 99.5% 以上になります。
SLA は SLO(サービスレベル目標)とは異なることに注意してください。SLO はサービスの可用性の数値目標を定義しますが、SLA は、一定期間において SLO が満たされるという、サービスを利用するユーザーに対する約束を定義します。シンプルにするために、このドキュメントでは、以降「SLA」という用語を使用します。
しかしながら、Google Cloud 上のお客様のシステムが単一の Compute Engine インスタンスで構成されていることはまれです。実際には、複数のサービスが絡み合い、相互に依存していて、アプリケーションははるかに複雑です。そのインスタンスが、99.0% しか利用できない Cloud Storage バケットにも依存している場合、単一の Compute Engine インスタンスで実行されているアプリケーションに対して 99.5% 以上という SLA をユーザーに保証できるでしょうか。
計算する必要があるのは、アプリケーションを構成するさまざまなサービスすべての可用性を組み合わせたもの、つまりアプリケーションの複合可用性です。そのためには、アプリケーション内のサービス間の関係が、アプリケーション全体の可用性にどのように影響するかを分析する必要があります。このアプローチにより、より回復力のあるシステムをより適切に設計し、ユーザーにより良いエクスペリエンスを提供できます。
複合可用性は、サービス間の関係に応じて、個々のサービス単独の可用性よりも高くなったり低くなったりする可能性があります。アプリケーションの設計例をいくつか見てみましょう。この計算はアーキテクチャ レベルの可用性のみを示すものであり、お客様のシステムに固有の手続き上および運用上のリスクは除外されていますが、設計を導くうえで意味のある、可用性の「上限」を示します。
依存サービス
依存サービスは、ひとつのサービスの可用性が他のサービスに依存するサービスとして定義されます。依存サービスのアーキテクチャには、いくつか一般的なバリエーションがあります。まず 1 つ目は「シリアル サービス」です。
シリアル サービス
連続するサービスが互いに直接依存しているアプリケーションについて考えてみましょう。
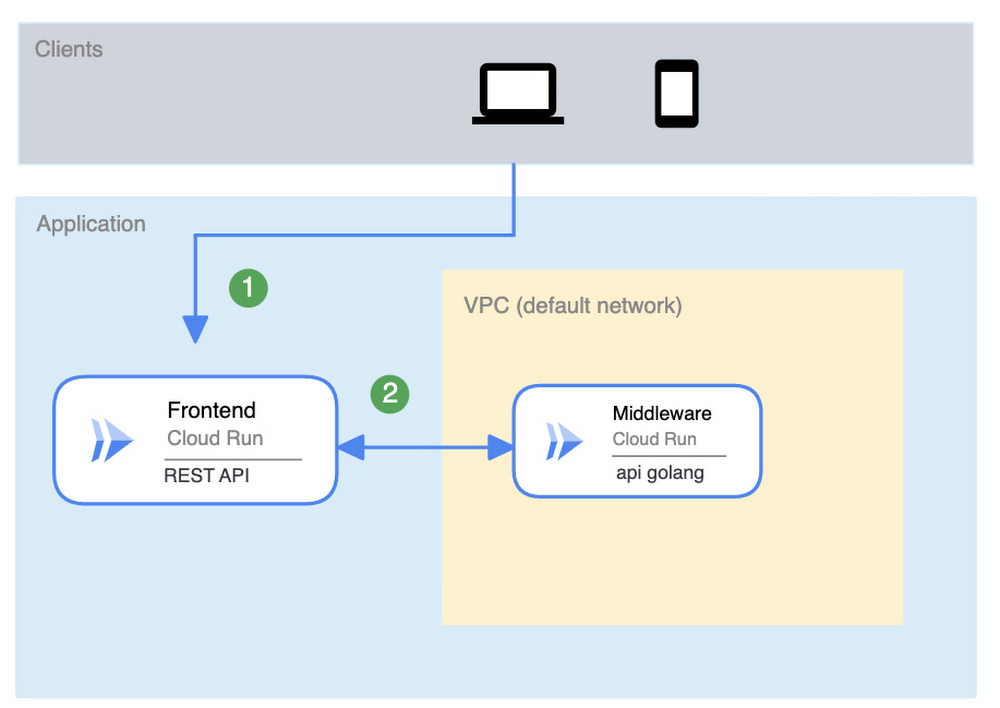
フロントエンドがミドルウェアに直接依存している場合、システム全体が使用できなくなる可能性は、各サービスの可用性に複合的に依存します。システムの信頼性は次のようになります。
または、任意の数の依存シリアル サービスに対する公式は次のようになります。
ここで、システムの SLA は、個々のサービスの SLA から大きく異なることに注意することが重要です。つまり、アーキテクチャの選択(すなわち、アーキテクチャの依存関係)は、プロバイダによる保証よりも大きな影響を与える可能性があります。Cloud Run サービスごとに「.9995」の可用性が提供されているとしても、システムでは「.999」の可用性しか提供できません。
並列サービス
もう 1 つの一般的な依存サービス アーキテクチャは、サービスを並列に配置するケースです。この場合、アプリはそれらすべての複合体になります。たとえば、ミドルウェアが、Cloud SQL で実行されているバックエンドと Memorystore で実行されているキャッシュに依存しているとします。ミドルウェアが機能するには、キャッシュとバックエンドの両方が稼働している必要があるとします。
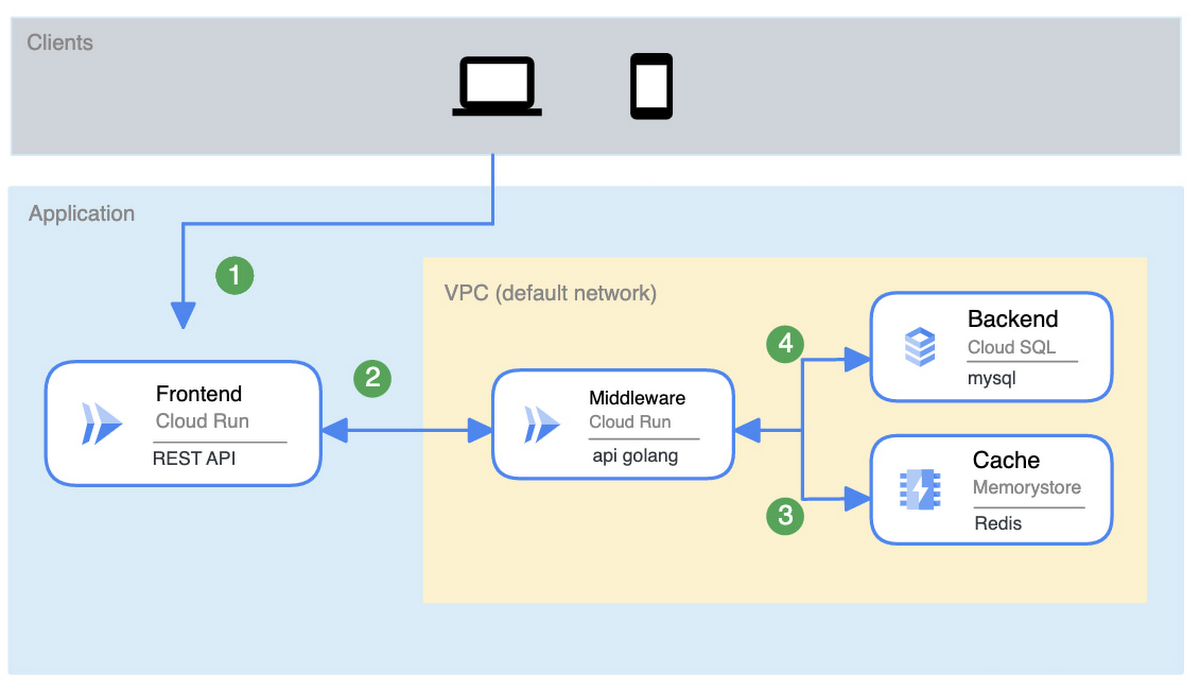
一見、この設計は 1 つ前のものより優れているように見えます。さまざまなサービスへの呼び出しを独立して行うことができるからです。しかしながら、キャッシュまたはバックエンドの障害は、ミドルウェアの障害と同様の信頼性への影響をもたらします。バックエンドはキャッシュに依存しませんが、システムは依存します。
ミドルウェアは各サービスを均等に使用するため、一連のサービスの全体的な観測可能な可用性は、特定の時間にこれらのサービスのいずれかが稼働している確率になります。
これらのシステムは依然として相互に依存しているため、結局、(SLA_1) × (SLA_2) … × (SLA_N) = システムの SLA、になってしまいます。そして、この依存サービスのリストが長くなるにつれて、システムの SLA が低下することがわかります。
独立サービス
では、どうすればシステムの SLA を改善できるでしょうか。アプリケーション全体の復元力を高めることができるサービスを導入することが必要です。たとえば、冗長性を持つサービスがこれにあたります。
冗長サービス
サービスの独立したコピーがあるということは、どれか 1 つのコピーが実行されている限り、アプリケーションが実行されることを意味します。では、アプリケーションを(たとえば複数のリージョンにまたがって)複製し、それらの間で負荷を分散したらどうなるでしょう。
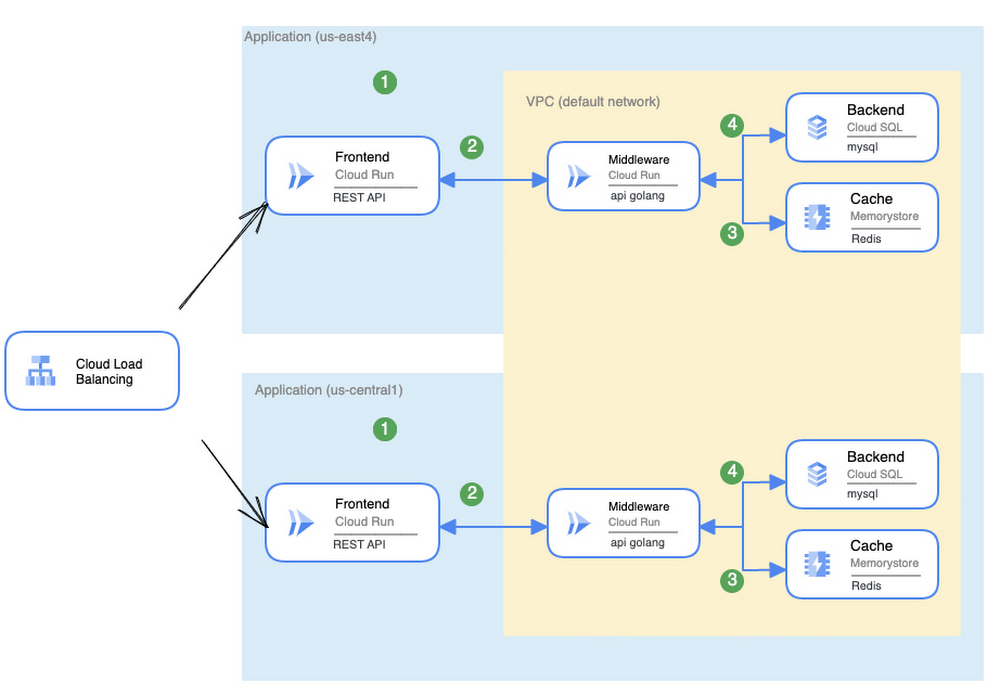
これで、アプリケーションのセットが 2 つになり、ロードバランサが導入されました。アプリケーションが停止する可能性は、両方のリージョンのすべてのサービスにおいて同時に障害が生じる確率、つまり「障害の確率」です。
システムが改善されました。この計算は、現実のシナリオにも当てはまります。リージョンでの障害が発生した場合でも、アプリケーションは稼働し続けます。
現実での考慮事項
これらすべてを念頭に置いたうえで、1 つの疑問が生じます。アプリケーションでほぼ無停止(0.99999…)を実現できないのはなぜでしょうか。理論的には、アプリケーションはいくらでも複製できます。しかし実際には、事態はもう少し複雑です。キャパシティやリソースの予算、構成に関連する時間と労力を考慮しなくてはいけません。最終的に、信頼性のボトルネックはインフラストラクチャでさえないことがよくあります。実際のボトルネックは、ネットワーク、アプリケーション ロジックであり、最も注目すべきは、複雑なシステムを管理する人々の実際の生活の影響です。
信頼性は、開発、プロダクト管理、運用、開発、SRE など、エンジニアリングに携わる全員の責任です。チームメンバーは、プロジェクトの信頼性の目標を理解し、リスクとエラー バジェットを把握し、作業の優先順位付けとエスカレーションを適切に行う責任があります。
最終的に、複合可用性を考慮した設計は重要ですが、それはパズルの 1 ピースにすぎません。ユーザー定義の独自の SLO、エラー バジェット、チームがどれくらい複雑な運用を引き受けることができるかに応じて、インフラストラクチャをコンテキスト化することが重要です。適切なバランスを見出すことが、アプリケーションを成功に導き、ユーザーを満足させる鍵です。
関連情報:
- アプリ モダナイゼーション担当ストラテジック クラウド エンジニア Cat Chu
- インフラストラクチャ モダナイゼーション担当ストラテジック クラウド エンジニア Gang Chen



