HAProxy を使用した Cloud SQL for PostgreSQL での読み取り専用ワークロードのスケーリング
Google Cloud Japan Team
※この投稿は米国時間 2022 年 2 月 8 日に、Google Cloud blog に投稿されたものの抄訳です。
Cloud SQL は、MySQL、PostgreSQL、SQL Server のワークロードのために Google Cloud が提供しているフルマネージドのリレーショナル データベース サービスです。Cloud SQL では、お客様はリードレプリカを使用して、読み取り専用のワークロードに対して水平方向のスケーリングを実装できます。このブログ投稿では、Cloud SQL for PostgreSQL と HAProxy を使用して、レプリカの自動検出を行う単一のエンドポイントの読み取りスケーリングとロード バランシング ソリューションについて説明します。
主な構成要素:
1 つ以上のリードレプリカを持つ Cloud SQL for PostgreSQL データベース。
HAProxy とクライアント プログラムを実行している Google Compute Engine(GCE)のインスタンス。
Cloud SQL インスタンスにリードレプリカが追加または削除された場合に、HAProxy 構成の自動更新を容易にするシェル スクリプト。
テスト設定のアーキテクチャ図:
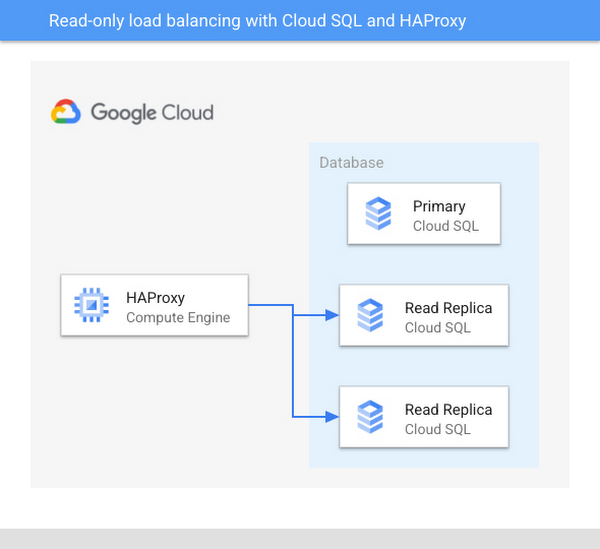
主な特徴
このセクションでは、ソリューションの主な特徴について説明します。
ロードバランサのオペレーション モード
HAProxy ロードバランサが TCP モードで動作するように構成します。データベース接続の観点からすると、「パススルー」モードと考えることができます。このロードバランサはデータベースの認証情報を保存せず(ヘルスチェック ユーザーを除く)、データベース接続のプールまたは復号 / 再暗号化も行いません。HAProxy の 1 つのクライアント接続は、Postgres の 1 つのクライアント接続に変換されます。
このアプローチは、ワークロードがクライアント接続数ではなく、データベースの処理能力によって制限される場合に適しています。クライアントの数が問題であれば、追加の接続プーリング コンポーネント(例: PgBouncer)が必要になる場合があります。たとえば、データベース インスタンスが、同時に接続するデータベース数の多さが原因で、パフォーマンスや安定性の問題を示した場合などです。
クエリと接続ロード バランシング
Google が提供する HAProxy 設定は、接続レベルのロード バランシングを使用します。つまり、次のようになります。
特定のデータベース接続を介して実行されるすべてのクエリは、同じリードレプリカに到達します。
クライアントは、異なるレプリカに到達する可能性があるため、接続を解除して再接続する必要があります。
HAProxy は、デフォルトの「roundrobin」アルゴリズムではなく、「leastconn」接続のルーティング アルゴリズムを使用するように構成されます。デフォルトの「roundrobin」アルゴリズムは、各レプリカの既存の接続数を考慮することなく、ほぼランダムに新しい接続を割り当てます。そのため、一部のレプリカが他のレプリカよりも多くの接続を受けることにより、ワークロードの不均衡が生じる可能性があります。一方、「leastconn」アルゴリズムは、新しい接続を既存の接続数が最も少ないレプリカにルーティングすることで、効率的にすべてのレプリカに対して均等な接続数を維持します。このアプローチにより、クエリ負荷をレプリカ間でより均等に分散できます。
この文脈の「既存の接続」とは、ロードバランサ自体によって処理されるクライアント セッションであることに留意してください。HAProxy は、レプリカに対して直接開かれた可能性のある他の接続(ロードバランサを迂回した)を認識しません。
読み取り / 書き込みの分離
このソリューションでは、読み取り専用接続のロード バランシングは提供されますが、読み取り / 書き込みの両方を行う接続に対してのロード バランシングは提供されません。読み取り / 書き込みのトラフィックを分離するには、接続レベルでアプリケーションによって処理される必要があります。読み取り専用の接続は HAProxy ロードバランサ インスタンスに接続できますが、読み取り / 書き込みクエリを実行しようとする接続は、Cloud SQL プライマリ インスタンスに直接接続する必要があります。
高可用性
PostgreSQL レイヤ
HAProxy は Cloud SQL インスタンスの各リードレプリカに対して SQL レベルのヘルスチェックを実行し、新しいクライアント接続は正常なレプリカに分散されます。レプリカが異常 / 応答なしだった場合、そのレプリカに存在する接続が残りのレプリカに対して自動的に移行または再調整されることはありません。接続エラーを検出すると、クライアントは HAProxy に再接続するだけで、残りの正常なレプリカの一つに到達できます。
書き込みクエリを実行するクライアントは、Cloud SQL プライマリ インスタンスに直接接続する必要があります。それらのクライアントが高可用性を必要とする場合、Cloud SQL ドキュメントに記載されているように、Cloud SQL の高可用性(HA)構成を使用してください。
HAProxy レイヤ
このデモでは、HAProxy インスタンス自体は高可用性のために構成されているわけではありません。本番環境のアプリケーションでは、Google Cloud のロードバランサの背後にあるインスタンス グループといった高可用性構成で、ロードバランサ インスタンスのデプロイを検討する必要があります。詳しくは Google Compute Engine ドキュメントをご覧ください。
実際のデプロイに関するアーキテクチャ図の例:
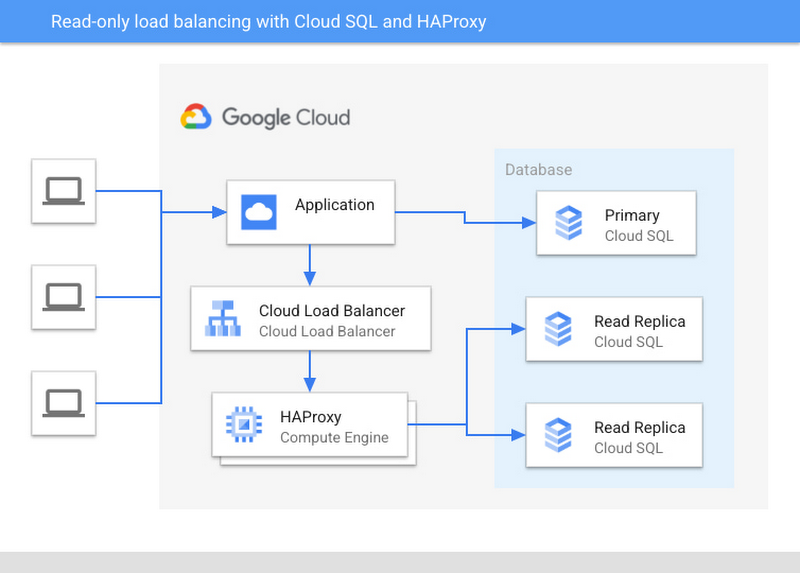
インスタンス トポロジの変更
お客様は、Cloud SQL を使用すると、リードレプリカを迅速かつ容易に追加、削除できます。これを受けてこのデモでは、レプリカを追加、削除する際に、ロードバランサの構成を手動で操作する必要がないことを前提としています。カスタム設定スクリプトを使用して、インスタンス トポロジの記述、使用可能なレプリカの列挙、HAProxy 構成の再読み込みを自動で行います。
初期設定
注意事項と前提条件
コンピューティング インスタンスを含む手順は、Debian GNU/Linux 10 buster オペレーティング システム イメージを使用して、Google Compute Engine でテスト済みです。ソフトウェアのインストール手順、構成 / ログファイルの場所は、システムによって異なる場合があります。
Cloud SQL インスタンスを含む手順のテストには、PostgreSQL 13 が使用されていますが、最新のリリース バージョンの PostgreSQL でも動作します。
GCE と Cloud SQL のインスタンスは、同じリージョン、VPC、ネットワークで起動することをおすすめします。そうすることで設定を簡略化し、プライベート IP アドレスを使用してインスタンス間での通信が可能になります。より複雑なネットワーク レイアウトを選択した場合(複数の VPC の使用など)、現在のネットワークとファイアウォールの構成で、プライベート IP を使用して HAProxy インスタンスから Cloud SQL レプリカへ接続できることを確認してください。
Cloud SQL データベースの設定
2 つのリードレプリカを持つ Cloud SQL for PostgreSQL インスタンスを起動します。このデモでは、1 個の vCPU、3.75 GB のメモリ、100 GB の SSD ストレージを備えたシングルゾーンの設定で十分でしょう。すべてのインスタンスで「プライベート IP」機能が有効になっていることを確認します。「パブリック IP」機能を無効にできますが、ここでは使用しません。
起動した時点の初期設定は以下のようになります。

図 3: 2 つのリードレプリカを持つ Cloud SQL インスタンスを表示する Google Cloud Console
Cloud SQL のデータベース ユーザーを作成するには、サポートされているメソッドのいずれかを使用します。
haproxy_healthcheck ユーザーは HAProxy からのヘルスチェックのクエリを処理します。
test_client ユーザーは HAProxy を通過するクライアント接続に使用します。
ユーザー パスワードは後で必要になりますので、メモしておいてください。
Google Cloud Console の Cloud SQL プライマリ インスタンスの [ユーザー] セクションで、ユーザー アカウントが正常に作成されていることを確認できます。次のようになります。
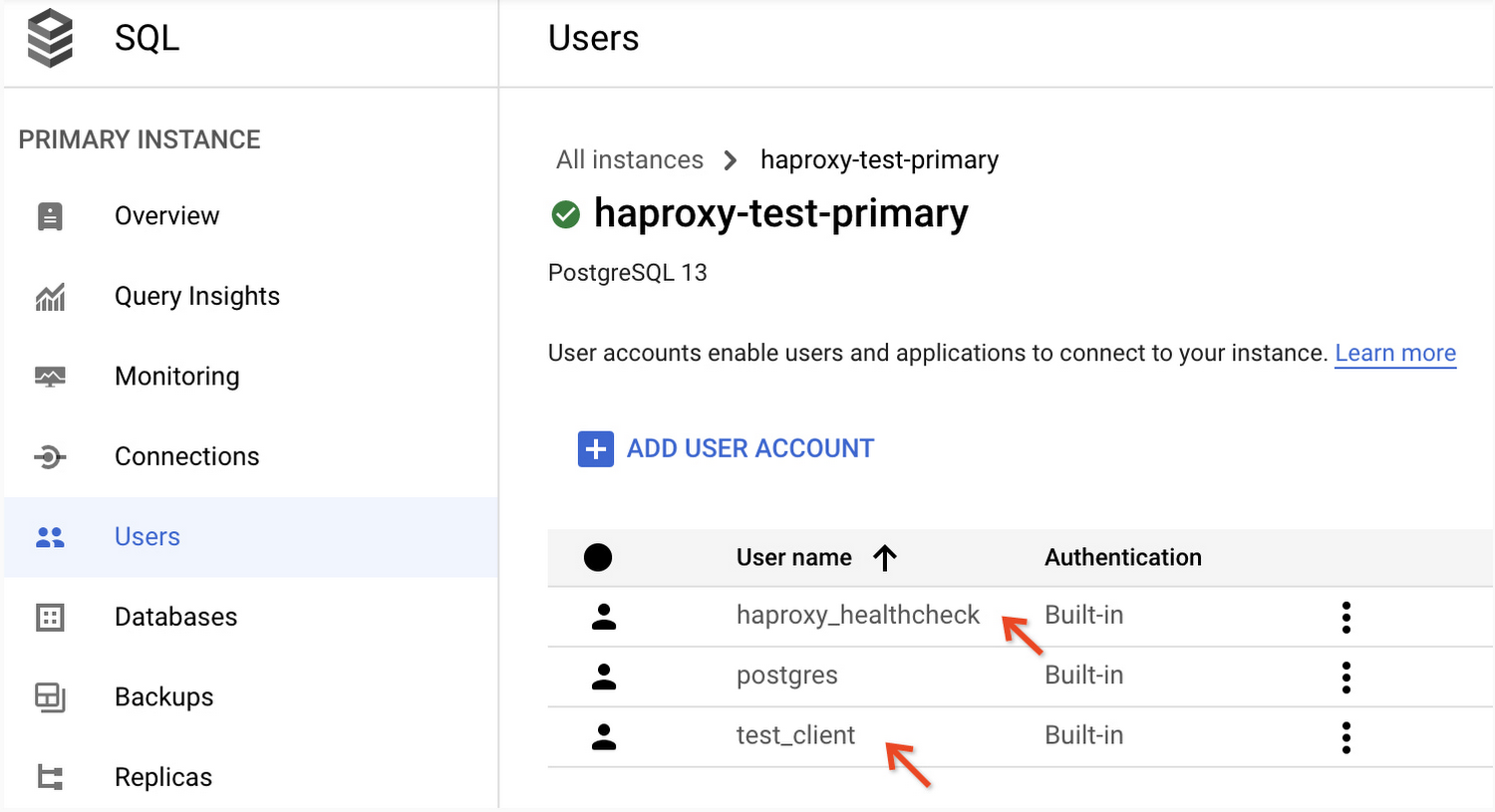
注: Cloud SQL データベースには、postgres という名前のデフォルト ユーザーが付属しています。これは、ヘルスチェックとクライアント接続の両方を処理するのに十分な権限を持つ特権付きアカウントです。そのアカウントを使用して設定を簡略化できます。本番環境のデプロイでは、最小権限ルールに従い、別の権限のないユーザー アカウントを使用してヘルスチェックを行う必要があります。
HAProxy インスタンスの設定
Debian GNU/Linux 10 オペレーティング システム イメージを使用して、GCE インスタンスを起動します。このデモでは、e2-medium のマシンタイプ(2 つの vCPU、4 GB のメモリ)で十分でしょう。SSH 経由でインスタンスに接続して、必要なソフトウェアをインストールし、以下で説明する基本的なデータベース接続を確認します。
Postgres のクライアント プログラムとサーバー プログラム、その他の必要なユーティリティをインストールします。
ロードバランサ インスタンスに PostgreSQL サーバー パッケージのインストールをする必要はありません。必要なのはパッケージに含まれる pgbench ツールだけで、サーバー自体は使用しません。インストールをする際にサーバーが自動的に起動する場合がありますが、後で安全に停止できます。
HAProxy をインストールします。
注: この例では、OS パッケージ マネージャーによって提供されるデフォルトのバージョンである、HAProxy 1.8 を使用しています。これは設定を簡略化し、ソリューションのデモを行うのに十分なバージョンです。本番環境のデプロイでは、最新バージョンの安定した HAProxy の使用を検討してください。Debian を使用している場合、haproxy.debian.net のウェブサイトに、希望する HAProxy バージョンをインストールする手順が記載されています。
以前に作成した Cloud SQL リードレプリカの 1 つを選択して、psql ツールを使用してレプリカに接続し、ヘルスチェック ユーザーとして SELECT 1 クエリを実行できることを確認します。
Google Cloud SDK には、GCE のデフォルトの Debian OS イメージがプリインストールされています。確認するには、gcloud コマンドを実行します。
このコマンドは、インストールされたソフトウェアのバージョンを記述した数行を返します。gcloud: command not found などのエラー メッセージは、SDK がインストールされていないことを示します。Cloud SDK のインストールのドキュメントに沿ってインストールしてください。
以前に作成した Cloud SQL インスタンスに対して、SDK が初期化され、gcloud sql instances describe API を呼び出す権限が与えられていることを確認します。必要に応じて、Cloud SDK のドキュメント、Cloud SDK の初期化を参照してください。
SDK をインストールして承認すると、Cloud SQL インスタンスを次のように記述できるようになります。
たとえば、このコマンドでは、以前に作成したプライマリ Cloud SQL インスタンスを記述し、jq JSON 解析ツールを使って、replicaNames フィールドからリードレプリカのリストを抽出します。
HAProxy の構成
はじめに
HAProxy 構成は、2 つのコンポーネントで成り立っています。
静的設定: これは、HAProxy 構成ディレクティブ、頻繁に変更されないフロントエンド ディレクティブやバックエンド ディレクティブです。
動的設定: これは、Cloud SQL インスタンスにレプリカが追加または削除された際に、リードレプリカ トポロジなどに変更があった場合、更新する必要があるバックエンド構成ディレクティブです。
例として、以下の抜粋には、静的設定と動的設定の両方が含まれています。緑色でハイライトされているディレクティブは、手動で設定されていて、頻繁に修正することを想定していません。青でハイライトされているディレクティブは、リードレプリカの追加、削除、レプリカのプライベート IP アドレスの変更による修正のたびに変更が必要になります。これらの設定は動的なものとみなし、手動での変更は避けたいと考えています。
HAProxy 構成は、以下のように管理されます。
静的設定は、通常のテキスト ファイルに保存されます。
動的設定は、gcloud sql instances describe API を介して取得したレプリカ情報をもとに、スクリプトで生成されます。
静的設定と動的設定は統合され、最終的な構成ファイルが作成されます。HAProxy 構成は、ロードバランサを完全にシャットダウンしてから再起動をしなくても、インプレースで再読み込みされます。
cron のシステムツールを使用し、スケジュールに従って実行されるシェル スクリプトよって手順 2 と 3 を実施します。
構成
HAProxy のメイン ディレクトリ(この例では、/var/lib/haproxy)に以下のファイルを作成します。
pgcheck.sh: HAProxy がリードレプリカに対してヘルスチェック クエリを実行するために使用するシェル スクリプトです。
cfgupdate.sh: インスタンス トポロジを記述して、HAProxy バックエンドの設定を生成し、その設定で HAProxy を再読み込みを行うシェルス クリプトです。
config_global.cfg, config_backend.cfg: 静的 HAProxy 構成を含むファイルです。
各ファイルの初期状態の内容は以下のとおりです。
config_backend.cfg
config_global.cfg
pgcheck.sh
cfgupdate.sh
ファイルの作成後、構成を調整します。
pgcheck.sh で、ヘルスチェック ユーザーの接続構成(ユーザー名、データベース、パスワード)を指定します。
cfgupdate.sh で、プライマリ Cloud SQL インスタンスの名前を指定します。
デモを完了するために静的 HAProxy 設定を変更する必要はありませんが、本番環境のデプロイでは、必要な感度を得るために、ヘルスチェックのタイムアウト設定と再試行の設定の調整が必要な場合があります。静的設定の変更は、config_global.cfg と config_backend.cfg で行えます。
必要な構成値を pgcheck.sh と cfgupdate.sh で指定した後、dryrun 引数を使用して cfgupdate.sh スクリプトを手動で実行します。ドライラン モードでは、このスクリプトによって HAProxy 構成が一時ファイルに生成されますが、HAProxy の再起動や再読み込み、またはメインの HAProxy 構成ファイルの置き換えは行いません。これにより、実際に適用する前にスクリプトをテストし、構成を確認できます。
エラーが発生した場合は、出力されるか、ログファイルに書き込まれます。たとえば、以下のエラーは、プライマリではなくレプリカである、または、レプリカの付かないプライマリであるなど、構成された Cloud SQL インスタンス名が正しくないことを示します。
スクリプトが正常に実行されると、以下のように表示されます。いくつかの通知がありますが、出力やログファイルにはエラーはありません。
設定ファイルの一番下に自動生成された server ディレクティブを確認できるようになります。
これで、このスクリプトを通常モードで実行して、HAProxy 構成の置き換え、再読み込みをする準備が整いました。HAProxy がすでに実行されているかどうかによって、「Starting HAProxy」または「Reloading HAProxy」と出力されます。
これで HAProxy が実行され、Postgres ポート(5432)でリッスンできるようになりました。また、HAProxy の統計情報で、「UP」とマークされたレプリカがバックエンドに表示されます。これは、SQL のヘルスチェックが正常に行われたことを示します。
HAProxy を実行していない、またはステータスが「UP」のサーバーが一覧表示されていない場合は、ログファイル(通常は /var/log/haproxy.log)でエラー メッセージとトラブルシューティングの情報について確認してください。
HAProxy を実行し、レプリカを起動した状態で、次のセクションに進みます。
デモ
基本的な接続の確認
SSH 経由で HAProxy インスタンスに接続します。
psql ツールを使用して、ロードバランサ インスタンスのプライベート IP に接続します。以前に作成した test_client ユーザーとして接続できます。正常に接続されると、Postgres コマンドラインのプロンプトが表示されます。
次に HAProxy の統計情報を取得します。ここで、scur フィールド(現在のセッション)が、レプリカの 1 つに対して「1」という値を返していることに注目してください。これは、psql クライアント プログラムが HAProxy 経由で接続されているレプリカです。
せっかくの機会ですので、1 つの接続ではなく、バックグラウンドで同時に 20 の接続を開いて、少し異なるアプローチを試してみましょう。各接続では、pg_sleep 関数を実行して、セッションを 30 秒間アクティブに保ちます。
コマンド実行後 30 秒以内に、HAProxy の統計情報を再確認します。今回、セッション カウンタには、2 つのレプリカに分散された合計 20 の接続が表示されます。
sleep 関数を終了し、クライアント セッションが閉じられた後、現在のセッション カウンタ(scur)は、ゼロに戻ります。
pgbench を使用したロード バランシングのテスト
SSH 経由で HAProxy インスタンスに接続します。
Cloud SQL プライマリ インスタンスに接続し、テストに必要なデータベース オブジェクトを作成します。
テストテーブルには、ランダムなデータサンプルを入力します。
このようなクエリを使用して、読み取り専用のワークロードをシミュレーションできるようになりました。このクエリは CPU に比較的高い負荷をかけるため、HAProxy による読み取りスケーリングの有効性を示すのに役立ちます。
pgbench が使用する SQL スクリプトにテストクエリを挿入します。
100 の同時実行セッションを使用して、pgbench を 5 分(300 秒)実行します。各セッションは、HAProxy 経由でデータベースに接続、クエリを実行、接続解除という 3 つのステップを繰り返し実行します。
別の設定でベンチマークを実行したい場合は、pgbench ドキュメントに利用可能なパラメータの詳細な説明が記載されています。
前のセクションで説明したとおり、テストの実行中に、HAProxy の統計情報をモニタリングできます。現在の HAProxy セッション数は、クライアントの接続と接続解除に応じて変動しますが、トラフィックは、2 つのレプリカ間でほぼ均等に分割されます。
実行の終了時に、pgbench によって以下のようなサマリーが作成されます。この例では、2 つのレプリカを使用して、1 秒あたり 52 トランザクション(クエリ)を実現しました。
両方のレプリカが利用されたことを確認するには、Google Cloud Console を開き、レプリカを選択します。
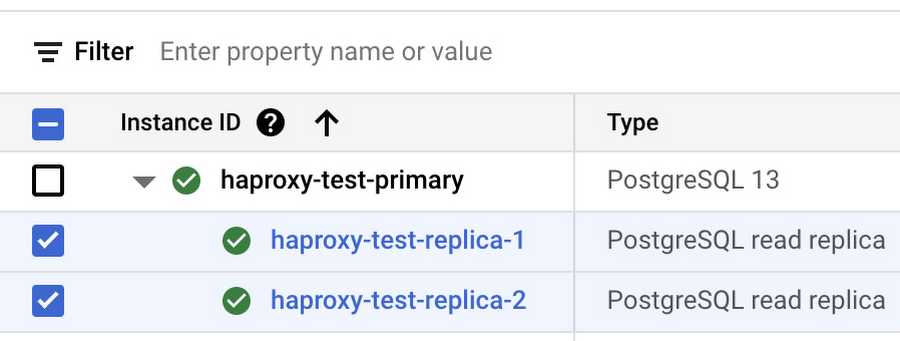
図 5: Google Cloud Console で Cloud SQL リードレプリカを選択
レプリカを選択すると、右側の情報パネルにそれぞれのモニタリング グラフが表示されます。「CPU 使用率」と「アクティブな接続」のグラフを参照し、テストの実行中に両方のレプリカが均等に利用されたことを確認します。以下に例を示します。
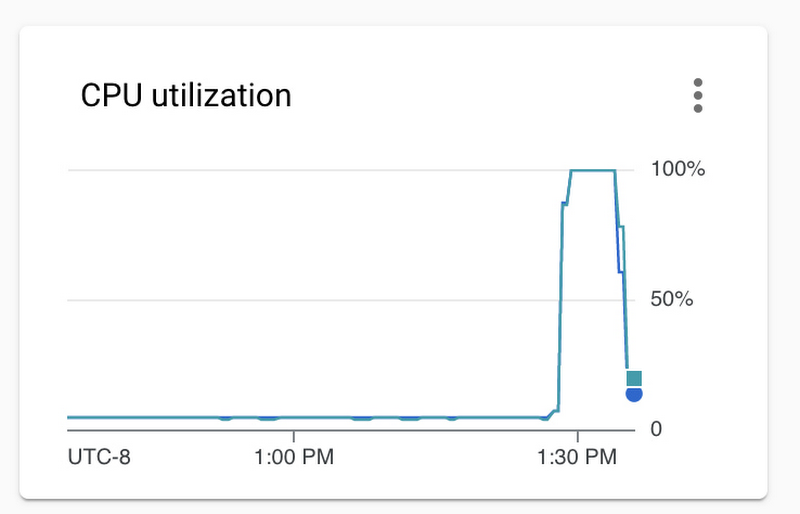
次に、3 つ目のレプリカをスピンアップして、利用可能になるのを待ちましょう。
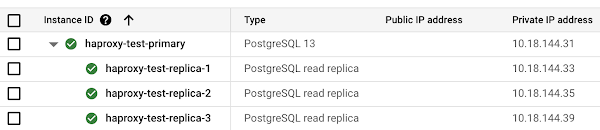
cfgupdate.sh スクリプトを使用して、HAProxy 構成を更新します。
最後に、pgbench を再実行し、出力を確認します。この例では、2 つのレプリカの秒間クエリ数 52 という以前の結果に対して、3 つのレプリカで秒間クエリ数 74 を実現できました。
上記で説明したとおり、Cloud SQL の指標や HAProxy の統計情報を使用して、負荷分散の確認ができます。
HAProxy 構成の自動更新による動的スケーリングの有効化
この時点で、HAProxy 構成スクリプトを使用して動的なワークロードのスケーリングを有効にするために必要なすべての構成要素が揃いました。このスクリプト自体が、レプリカのトポロジの変更を検知し、それに応じて HAProxy 構成を再読み込みする機能については、すでにご説明しました。あとは、スケジュールに従って自動的にスクリプトを実行するだけで、手動でスクリプトを実行しなくても、レプリカの変更が HAProxy 構成に反映されます。
まず、HAProxy インスタンスの crontab(/etc/crontab)に以下の行を挿入し、1 分ごとに自動的にスクリプトを実行します。
毎分の最初にコードが実行されているかを確かめるには、スクリプトのログファイルのタイムスタンプを確認します。
スクリプトがスケジュール通りに実行されていれば、pgbench を使用してテストを続行できます。テスト中に、レプリカの 1 つを削除します(例: haproxy-test-replica-3)。レプリカをシャットダウンするとすぐに、HAProxy のヘルスチェックは失敗し、レプリカは「down」とマークされます。
レプリカは最終的に構成スクリプトのログからも削除されます。
3 つ目のレプリカ設定をし直すと、数分以内に HAProxy が自動的に検知します。
テストを続行して、レプリカを追加、削除しながらテストを追加で実行することもできます。数分以内に HAProxy 構成に変更が反映されていることが確認できます。
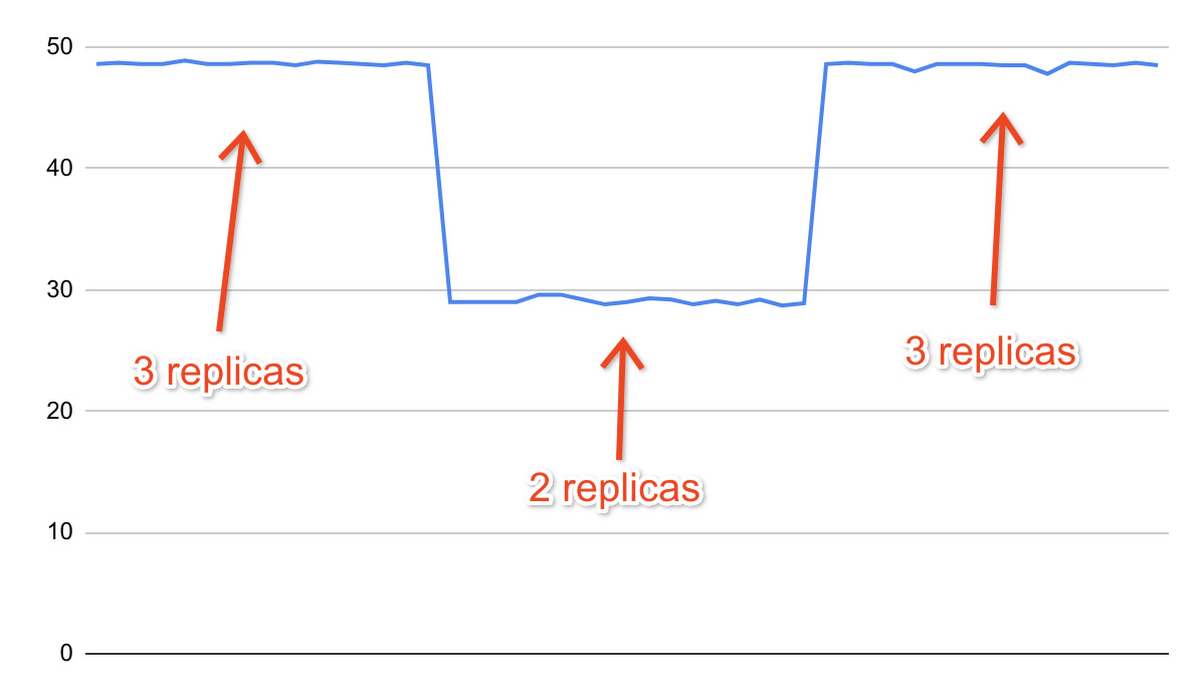
例として、以下は別のテスト中に pgbench が返した TPS(1 秒あたりのトランザクション数)の指標の記録です。そのテストは、3 つのレプリカ、次に 2 つのレプリカ、そして再び 3 つのレプリカで実行されました。ワークロードのスケーリングは、構成スクリプトによって自動的に行われました。
高度なトピック
本番環境のデプロイでは、以下の高度な機能の実装を検討してみてください。
テンプレートに基づくロードバランサ インスタンスのデプロイ。大規模なロードバランサを管理する場合、各インスタンスを手動で構成する代わりに、HAProxy インスタンスのプロビジョニングに使用される共通のマシンイメージを作成できます。インスタンス固有の設定(HAProxy 構成スクリプトで使用するプライマリ インスタンス名など)は、起動スクリプトやカスタム VM メタデータなどの Google Compute Engine の機能を使用して指定できます。
高度な認証情報ストレージ。ヘルスチェック ユーザーの認証情報は、各 HAProxy インスタンスで利用可能である必要があります。Secret Manager などのサービスや IAM データベース認証などの Cloud SQL の機能を利用することで、ヘルスチェックのファイル内にあるユーザー認証情報のハードコード化を回避できます。
高度なレプリカ検出ロジック。今回のデモで提供された構成スクリプトは、単一の Cloud SQL プライマリ インスタンスのリードレプリカに関する基本的な検出に対応しており、インスタンス名やラベルなど、レプリカの特徴に基づいた高度な検出機能を導入できます。たとえば、インスタンス ラベルを使用して、HAProxy 構成から特定のレプリカを追加または除外するようにスクリプトを修正できます。
複数のレプリカプールに対応。今回のデモで提供された構成スクリプトは、単一の HAProxy バックエンド用の設定を生成します。このスクリプトを拡張することで、単一の HAProxy のインストレーション内で複数の HAProxy バックエンドを公開できます。そうすることで、単一の HAProxy インスタンスで複数の Cloud SQL データベースのトラフィックをロード バランシングできます。
接続プーリング。ここで示したソリューションは接続プーリングを提供していないので、リードレプリカ インスタンスによって処理される接続の総数を減らすことはできません。これは、ワークロードがクライアント接続の数ではなく、データベースの処理能力によって制約される場合は問題ありません。クライアントの数が非常に多くなり、プロセスの競合によってレプリカに問題が発生した場合、HAProxy と連携して動作する接続プーリング コンポーネント(PgBouncer など)が必要になる場合があります。効率性を高めるため、接続プーリング ソフトウェアと HAProxy は、同じインスタンスで実行されます。
代替ソリューションHAProxy(オプションで PgBouncer)は PostgreSQL のロード バランシング(および接続プーリング)を実装する最も簡単な方法の一つですが、それが唯一の方法というわけではありません。ここでは、検討できる代替ソリューションの例をいくつかご紹介します。
プーリングとロード バランシングの両方に対応する Pgpool-II。Pgpool-II は、HAProxy や PgBouncer に比べて設定や管理がやや複雑ですが、上級ユーザーが使用すると便利なツールになります。
Pgpool-II(ロード バランシング用)と PgBouncer(プーリング用)。
クライアント側のドライバによって提供される接続プーリングを備えた HAProxy(ロード バランシング用)
- Cloud SQL スタッフ データベース エンジニア Szymon Komendera


