Cloud Spanner を使用した高スループットの書き込み処理
Google Cloud Japan Team
※この投稿は米国時間 2023 年 5 月 6 日に、Google Cloud blog に投稿されたものの抄訳です。
ソーシャル アプリにはフィードを管理し、ユーザーがソーシャル プラットフォームを通じてコンテンツに賛成票を投じたり、コンテンツを共有できるものがあります。このような賛成票や共有は、バックエンドのデータベースで「カウンタ」として追跡されます。このガイドでは、Cloud Spanner データベースを使用して、賛成票および共有カウンタを実装するためのさまざまな選択肢について説明します。これは、ライブゲームのスコア追跡や小売店での在庫管理のほか、さまざまな業種のアプリケーションに容易に拡張できます。
Cloud Spanner はリレーショナル データベースとして、これらすべてのソリューションを強化する SQL セマンティクスを提供します。これはスケーリングを目的として構築されており、通常であれば、スケーリングの限界に達してしまう大規模なビジネス アプリケーション向けに、組み込みのシャーディング機能を提供します。また、在庫、会計、マーケットプレイスを扱うアプリケーションとの、トランザクションにおける優れた整合性を提供します。
課題
ソーシャル アプリでは、短期間にユーザーによる何百万という数の賛成投票や共有を引き起こすクチコミ投稿がよく見られます。これは、ホットスポット化によって発生する、少数の行セットに対するバックエンド データベースの過負荷を引き起こします。ホットスポットとは、同一データベース行に対して多量のリクエストが送信され、その行をホスティングするサーバーのリソースが飽和状態になり、エンドユーザーのレイテンシが高くなる事象と定義されています。
人気のソーシャル アプリには数千件のクチコミが投稿されることがあり、これらに対するユーザーからの賛成票がアプリやそのデータベースでの過負荷挙動を引き起こす可能性があります。これは、読み取りや書き込みのレイテンシ、データベースのメモリや CPU リソースの使用量の増加という形で確認できます。
さらに、ソーシャル アプリケーションによっては、ユーザーが投稿を人気順に並べ替えできるものがあり、高速な読み取りアクセスが必要となります。これは、これらのカウンタのインデックスを使用して構築できます。このような並べ替えの読み取りを実装することで、書き込みする際にさらなるパフォーマンス負荷が発生します。賛成投票や共有時には、データベースの書き込みがベーステーブルとカウンタ インデックスのトランザクションの更新に変換され(Cloud Spanner の場合、複数参加者の commit がそれにあたり、パフォーマンスが低下する可能性があります)、システムがさらに複雑になります。
この問題を解決するために使用できるソリューションがいくつかありますが、それぞれに緩和を必要とする異なる要件があります。
ソリューション
凡例

1. 読み取り / 修正 / 書き込み
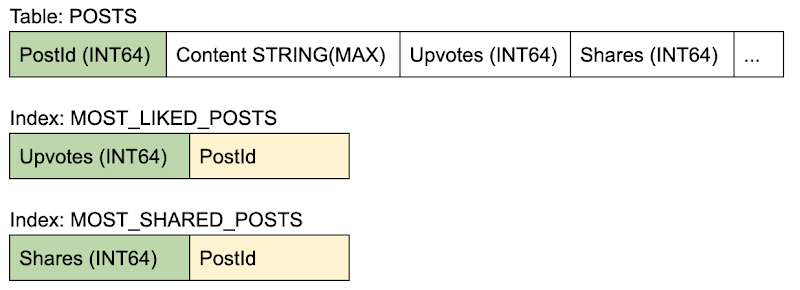
データベース テーブルでは、カウンタを投稿のメタデータの一部として、同じテーブル上に配置して保存できます。クライアント アプリケーションは、読み取り-修正-書き込みトランザクションを実行します。すなわち、投稿から現在のカウンタ値を読みとり、それに 1 を足した値に更新します。
単一のカウンタを更新するすべてのトランザクションは次々にシリアル化され、期待されるスループットは単一トランザクションのレイテンシの関数となります。
スキーマ
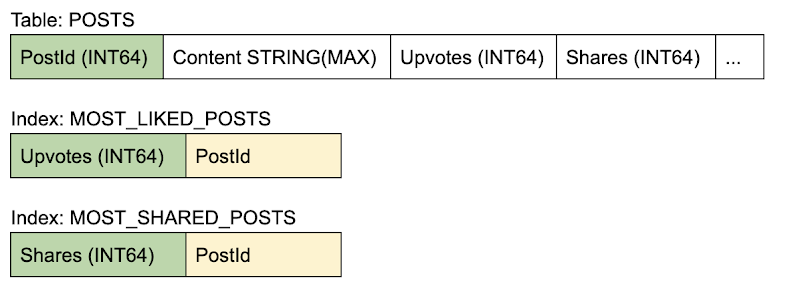
メリット:
これは、開発にもメンテナンスにも、最もわかりやすくシンプルなソリューションです。ほとんどのお客様のアプリケーションは、スケーリングの限界に達するまでは、このアプローチで構築されています。
投稿とそのメタデータの読み込みはすべて単一のテーブルで行われるため、複数のテーブルからデータを収集するための追加処理(JOIN など)は発生しません。カウンタの値が最も高い投稿を見つけるには、STORING 句に保存された追加メタデータ(投稿者、日付など)と併せて、インデックスを直接スキャンします。
また、カウンタはすでに集計されているため、追加処理(SUM(upvotes) など)は必要ありません。
これにより、アプリケーションに最新のカウンタ値(強整合性)が提供され、カウンタ値が常に最新の状態になります。
デメリット:
ホットスポット化の影響を受けやすくなり、ロック競合の発生も多いため、読み書きの両方でアプリケーションのスループットが低下します。
2. シャーディングされたカウンタ
データベース テーブルは、インターリーブ テーブルの一部としてカウンタを保存できます。Cloud Spanner では、インターリーブ テーブルが同じスプリット上に配置されているため、2 つの別のテーブルに対して行われる通常のオペレーションより、読み取りと書き込みが高速になります。このインターリーブ テーブルは、シャーディング カウンタ(X 行に分散する複数のカウンタ値)を実装します。予想される書き込みスループットに応じて、X の値は 10~100 程度になります。適切な値は、負荷テストを実行し、固定スループットのベンチマーク全体でレイテンシを測定することによって決定できます。
書き込みのたびに、インターリーブ テーブルのランダムな行(乱数生成ツールを使用して生成された)が増分されます。このように読み取りをしない場合、このアプローチでは書き込みスループットは(シャードの数に応じて)直線的に増加します。しかしながら、読み取りの方が費用がかかります。集計されたカウンタ値の読み取りごとに、インターリーブ テーブルの全行にわたる合計(カウンタ)が実行されます。高い読み取りスループットを得るためには、お客様は読み取り専用トランザクション内で(ステイルまたは強力な)読み取りを使用する必要があります。このアプローチでは、読み取り / 書き込みトランザクション内で読み取りを実施すると大幅に速度が低下し、ロック競合(書き込み側との)の発生頻度が高くなる可能性があります。
スキーマ
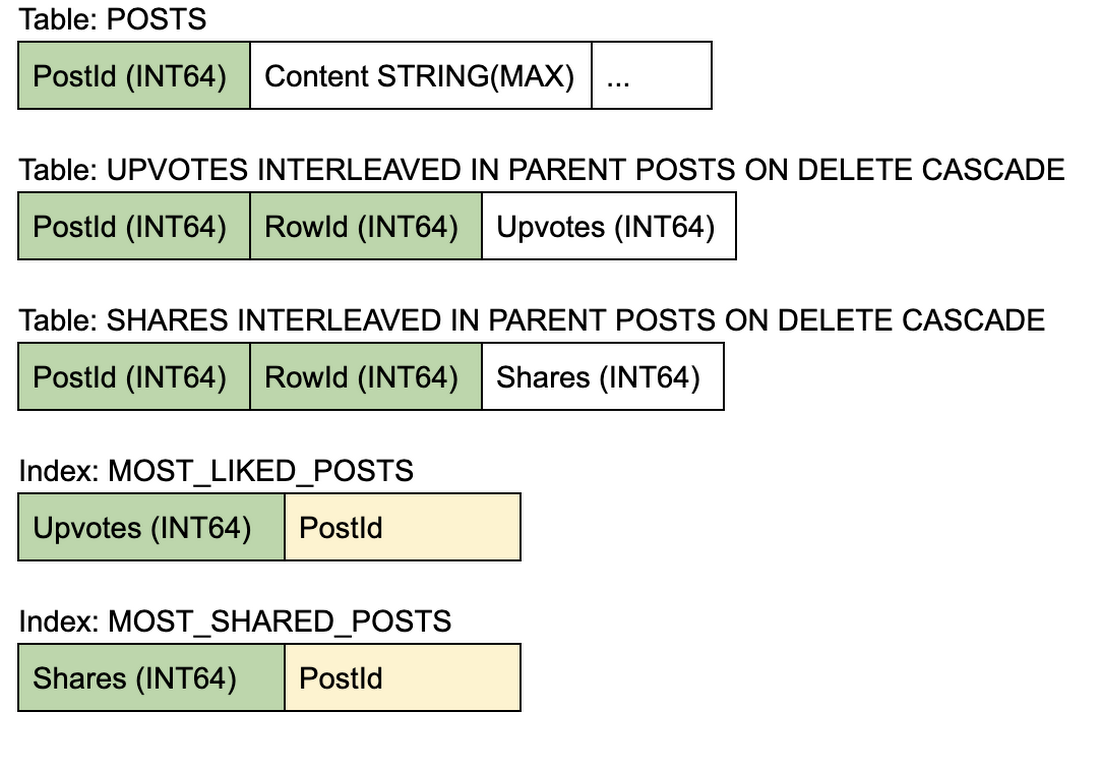
メリット:
カウンタを増加させる書き込みが、インターリーブ テーブルの X 行に分散されるようになります。そのため、ホットスポット化してしまう可能性が低くなります。また、親の POSTS テーブル内などの他の投稿メタデータ更新頻度が低い場合、インターリーブ カウンタ テーブルへの書き込みは、親行の共有ロックを維持するのみのため、親の POSTS テーブルの読み取り性能を大幅に向上させます。
カウンタの読み取りは、SUM() 関数を使って簡単に行うことができ、インターリーブ テーブルのサイズが小さいことから、Cloud Spanner ではこのような読み取りを(読み取り専用トランザクションで)非常に効率的に実行できます。
これにより、アプリケーションに最新のカウンタ値が提供されます(信頼性の高い同時実行性)。
デメリット:
トランザクションにおけるカウンタの読み取りと書き込みの比率が高い場合、このアプローチでは効率が上がりません。
3. 盲目的書き込みと周期的な集計
注: このソリューションは、キーごとに約 10 万の QPS が想定される、非常に高スループットのアプリケーションにのみ適しています。
上述したすべてのソリューションの性能は、内部でポスト行の排他ロックを維持し、カウンタの読み取り / 書き込みスループットを制限する、読み取り-修正-書き込みの更新セマンティクスによって制約を受けます。これらのパラダイムでは、読み取り、書き込み、最終的な commit のリクエストのネットワーク往復レイテンシが原因で、ロック保持期間も長くなります。その結果、ロック競合によるエンドユーザーのレイテンシ、トランザクションの中断の割合が高くなります。
Cloud Spanner では、排他ロックを取得しない盲目的書き込みが可能であり、スループットを大幅に向上させることができます。しかし、カウンタを維持するために盲目的書き込みを使用するには、クライアント アプリケーション レイヤで構築された高度なロジックと、より複雑なデータベース スキーマが必要です。
親テーブル(POSTS)には、集計されたカウンタ値と、これが最後に集計された時点のタイムスタンプ(commit_timestamp を使用して実装)が保存されます。各アプリがカウンタ値を更新するために「書き込み」を行うと、特定のカウンタ インターリーブ テーブル内の行とタイムスタンプの追加のみが行われます。定期的に、これらのトランザクションは、最後に集計された時点のタイムスタンプ以降のインターリーブ テーブルのすべてのカウンタを合計し、親行を更新します。その後、オプションでインターリーブされた行のパージや、Spanner の TTL ポリシーの適用が可能です。
各読み取りは、最新のカウンタ値を確認するため、親テーブルから集計値を読み取り、インターリーブ テーブル内の行(最後に集計された時点のタイムスタンプ以降の)をカウントする必要があります。
スキーマ
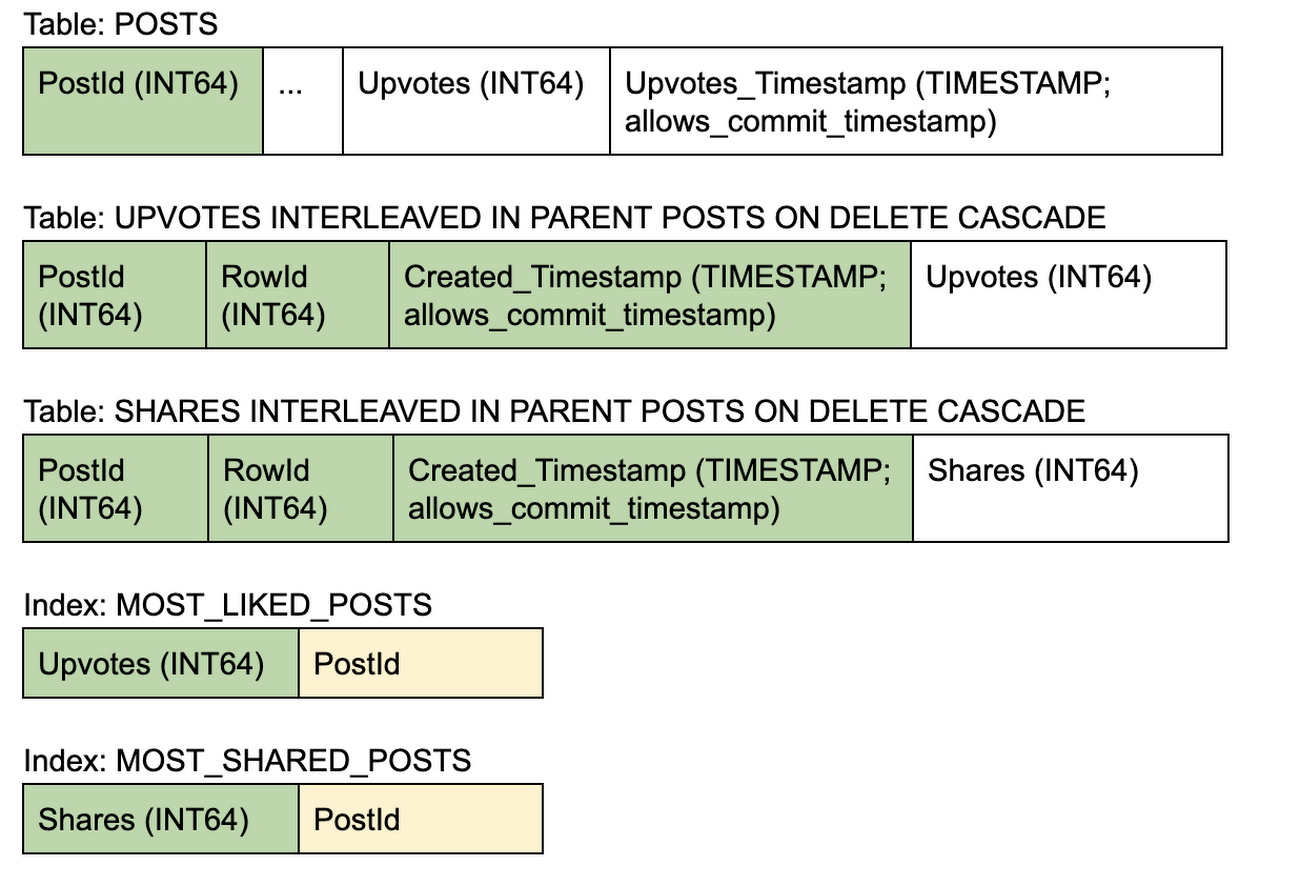
4. キャッシュ
注: このソリューションは、カウンタのトランザクションの強整合性に依存しないアプリケーションに適しています。集計レイヤとしてのキャッシュの推奨事項は、Spanner への書き込みの総数を減らしてより高いスループットを実現することです。
クライアント アプリケーション レイヤは、これらのカウンタを中間レイヤ(Cloud Memorystore など)でキャッシュに保存し、データベースに定期的に(バックグラウンドで)更新できます。高度な実装をすることで、分散キャッシュを使用して、これらのカウンタを同時に読み取り、書き込みすることが可能になります。
ライトバック キャッシュを実装することで、アプリケーションの書き込みスループットを向上させることができます。主なメリットは、複数の書き込みを Spanner への 1 回の書き込みに集約できることです。このパラダイムでは、(非同期書き込みが完了するまで)Spanner のデータが最新のものではない、というデメリットがあります。
スキーマ
メリット:
キャッシュは、読み取り-修正-書き込みオペレーションのレイテンシが低く、ACID プロパティを保証します。
これにより、クライアント アプリケーションの読み取りおよび書き込みのスループットが向上します。
デメリット:
キャッシュ レイヤの構築、維持のためのインフラストラクチャを追加する必要があります。
データベースが最新でない可能性があるため、すべての読み取りで、キャッシュを使用する必要があります。
非永続キャッシュの場合、データの耐久性が懸念されます。
次のステップ
Cloud Spanner は、あらゆるサイズのお客様アプリケーションに対応するスケーラブルなソリューションを提供します。Spanner の読み取りおよび書き込みトランザクションについて詳しくは、こちらのドキュメントをご覧ください。Cloud Spanner を使い始めるには、簡単なチュートリアルをお試しください。
- シニア ソフトウェア エンジニア Sneha Shah


