PostgreSQL の移植性と親和性の高さを Spanner のスケーラビリティと信頼性と組み合わせる
Google Cloud Japan Team
※この投稿は米国時間 2023 年 11 月 14 日に、Google Cloud blog に投稿されたものの抄訳です。
金融サービス、ゲーム、小売など多くの業界の先進的なお客様が Spanner を使用して、ダウンタイムがなくスケーリングが必要な、要件の厳しいリレーショナル データベースのワークロードに対応しています。開発者のニーズに応えられるように、Spanner で利用できる PostgreSQL Interface では、開発チームが求めていた親和性と移植性を提供することで、Spanner のスケーラビリティおよび信頼性と組み合わせて活用できるようになりました。ユーザーはこれにより、PostgreSQL クエリ、データ型、スキーマ、クライアントを使用して Spanner 独自の整合性や可用性を大規模に利用できるようになります。
PostgreSQL Interface の機能と PostgreSQL により実現する整合性が何を意味するのかについて、見ていきましょう。
解析、最適化、実行
Spanner を始めとした多くのデータベース エンジンは複数のステージを経てクエリを処理します。たとえば次のようなステージです。
- 解析: クエリ文字列は、処理によりツリー型データ構造に変換されます。この構造には、テーブル検索、結合、式、その他のオペレーションなど、クエリ文字列で要求したすべての情報が表されます。データベース カタログ内の名前付きテーブルや関数などが検索対象となり、名前の競合を解消して、存在しないテーブルや関数を参照するクエリを拒否できます。
- 最適化: ツリー型データ構造は、データの並び替えの後で、リクエストされたデータを最大限効率的に取得する実行プランに変換されます。この処理は、クエリ プランニングまたはコンパイルとも呼ばれます。Spanner のクエリ オプティマイザーについては、こちらで説明しています。
実行: コンパイルしたクエリプランを実行します。リクエストされたデータを取得して返します。
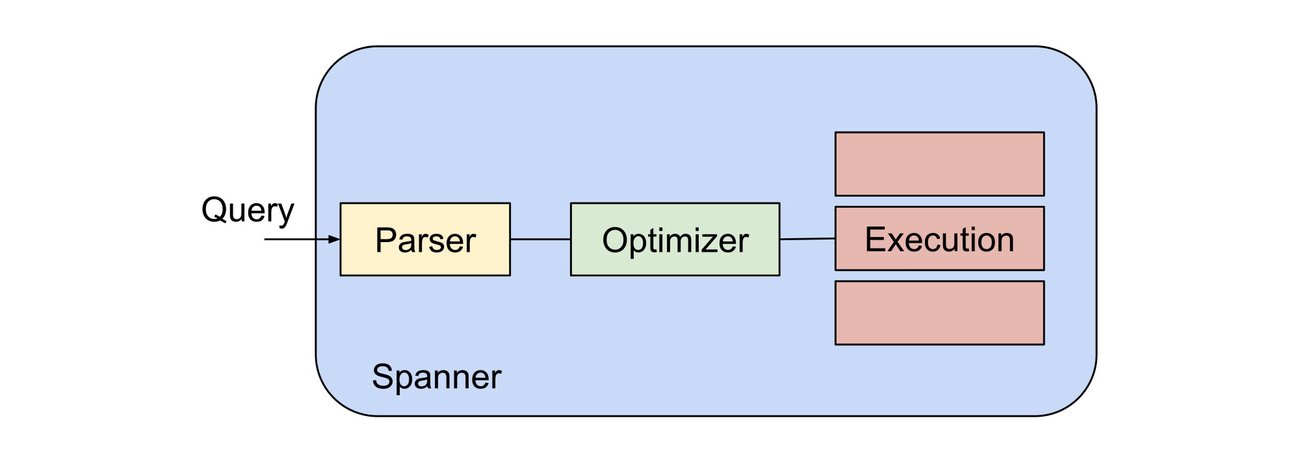
上のイラストは、これら 3 ステップについて論理的なコンセプトを表現したものです。Spanner は、解析と最適化の負荷を共有するクラスタ全体にクエリを分散します。また必要に応じて、各クエリの実行処理を複数のノードで分散します。その他のデータベースも同様のコンセプトの多くを共有していますが、処理の分散方法が異なる(または一切行わない)場合があります。
Spanner は以前から、(ZetaSQL に関連する)Google 標準 SQL 言語をサポートしてきました。Google 標準 SQL は標準遵守型の堅牢な SQL 言語であり、Google で広く使用されています。たとえば BigQuery がこの言語に当たり、幅広い種類の SQL 機能をサポートしています。
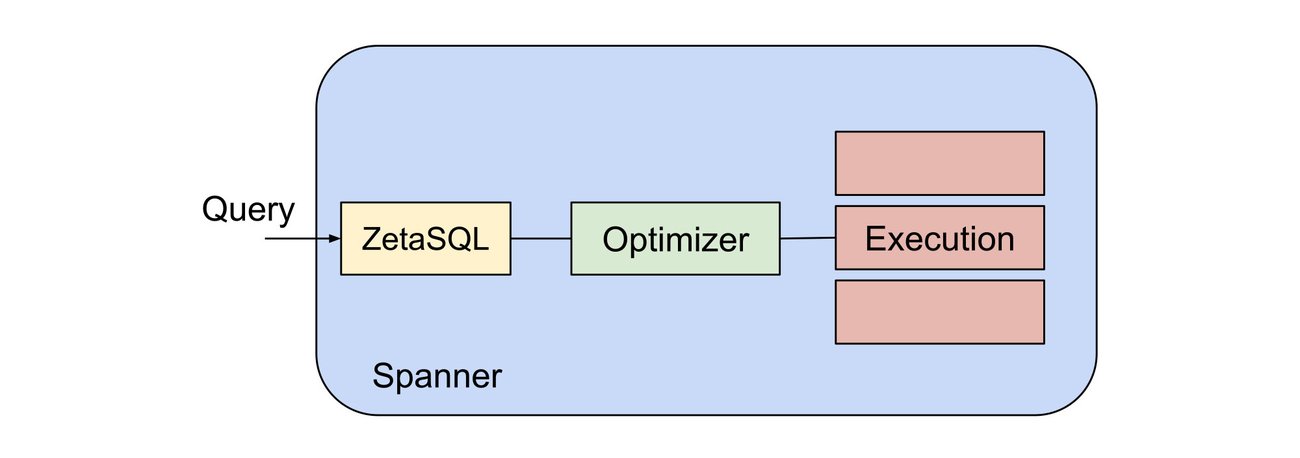
ZetaSQL はこの SQL 標準を遵守することに重点を置いています。これは、ユーザーがあらゆるデータベースで見慣れた構文を使って、Spanner と BigQuery の両方を活用したスタック全体で一貫したエクスペリエンスを構築したい場合に、望ましい選択肢となります。
他のデータベースでは異なるアプローチを採っています。例として PostgreSQL を考え見ましょう。オリジナルの Postgres エンジンは 1986 年と、SQL 標準自体よりもわずかに先行して開発されました。PostgreSQL は、数十年にわたっていくつかの特徴的なアイデアを採用してきましたが、それにより唯一無二の存在となり、各種 SQL 実装の中でも独特な機能を獲得しています。
PostgreSQL 言語とエコシステムに慣れ親しんだユーザーが力を発揮できるよう、Spanner は新たに PostgreSQL 構文クエリに対応しました。
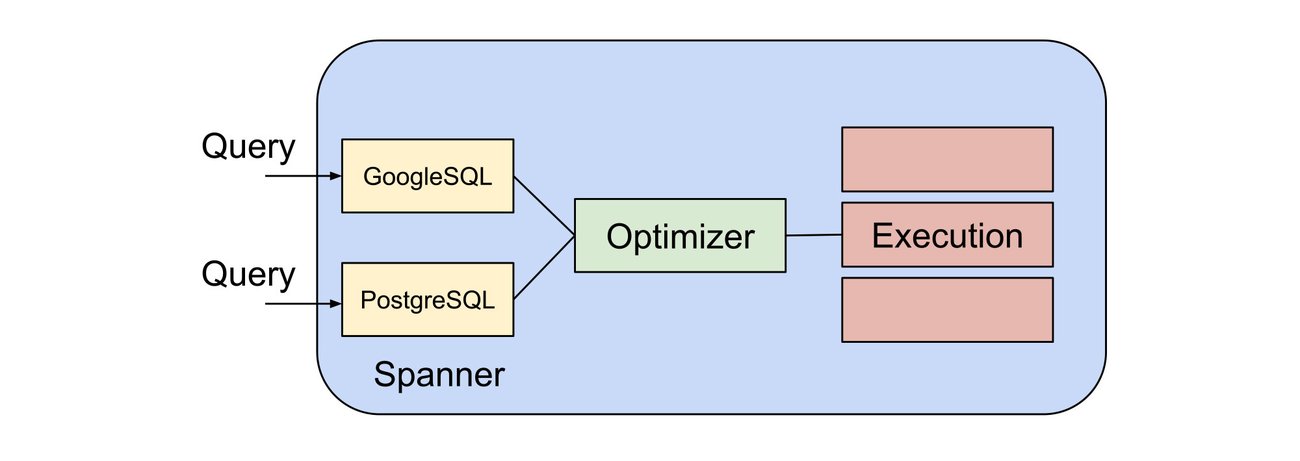
PostgreSQL 互換クエリは Spanner における「ファースト クラス」コンセプトであり、ネイティブにサポートされます。これらは GoogleSQL のクエリと同じように、直接データ構造に解析されて、Spanner のオプティマイザーで利用されます。これにより、基盤となる Spanner エンジンの力を PostgreSQL 言語で直接利用できるようになります。よく誤解されていますが、PostgreSQL クエリが GoogleSQL クエリに変換されるわけではありません。
オプティマイザーはその後、使用している特定データやインフラストラクチャに合わせてクエリプランを作成します。このクエリプランを使用して、大きく複雑なクエリであっても効率的でスケーラブルなクエリプランを Spanner で生成できるようになります。
PostgreSQL Interface では、スケーラブルかつ分散可能なクエリプランを作成するために、PostgreSQL のオプティマイザーではなく Spanner のオプティマイザーを使用します。PostgreSQL のオプティマイザーは単一のサーバーに対して最適化されたプランの生成用に調整されている一方で、Spanner のオプティマイザーは Spanner の分散アーキテクチャのメリットを駆使して、複数のサーバーやデータセンターはおろか、複数の大陸にさえ対応できるようスケーリングできます。
カタログとシステムのメタデータ
PostgreSQL の構文は、クエリの記述する際に非常に便利ですが、構文は Spanner が備える PostgreSQL 要素の一部でしかありません。
既存の PostgreSQL ツールの多くは、基盤となるデータベースのイントロスペクションと把握を行うために、隠しメタデータ クエリを発行します。たとえば、SQL 標準「information_schema」スキーマのテーブルに対してクエリを実行することで、データベースに存在するテーブルと列を把握するツールがあるとします。その後ツールは、「pg_catalog」スキーマの PostgreSQL 専用テーブルに対してクエリを実行し、ディスク上におけるそれらのテーブルの保存場所と保存方法、列のデフォルト値の式、未加工の PostgreSQL 式ツリーとその式を実装するコア機能、その他の低レベル PostgreSQL 専用内部要素を把握します。
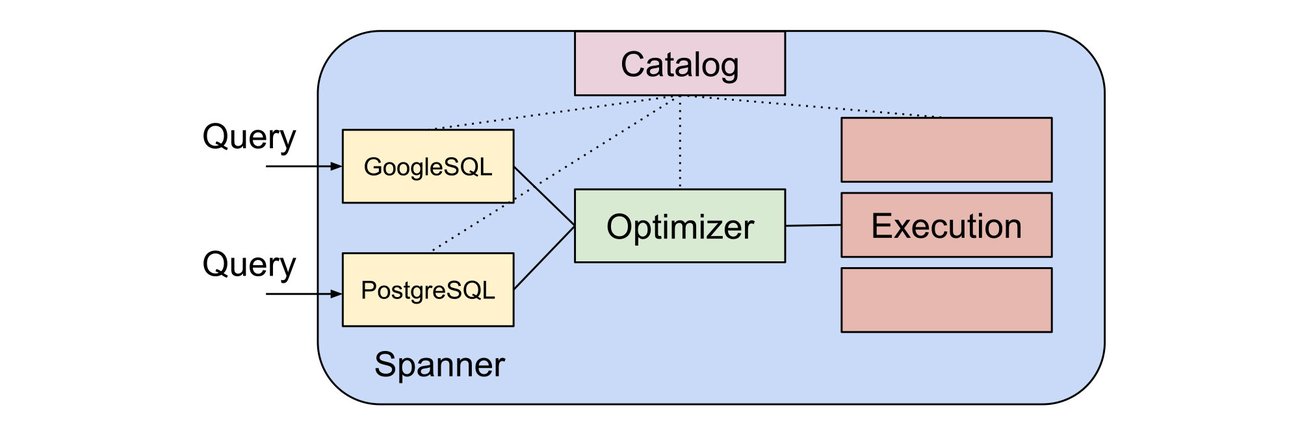
information_schema は SQL 標準の一部ですが、PostgreSQL はその標準を Spanner とは少し違う形で実装しています。Spanner PostgreSQL データベースを構築する際は、PostgreSQL で想定通りの動作を行うのか information_schema を確認します。
Spanner では、特に Spanner PostgreSQL データベースと一緒に利用する pg_catalog スキーマの対応化を進めています。Spanner が備える spanner_sys schema と同様に、information_schema は Google 標準 SQL データベースと PostgreSQL Spanner データベースの両方で引き続き利用可能です。
エンジンのサポート
PostgreSQL には長い歴史があります。そのソースコードの起源は、1980 年代の Postgres プロジェクトと PostQUEL クエリ言語まで遡ります。何十年にもわたり、数多くの機能を蓄積してきました。PostgreSQL の SQL 言語が持つ重要なメリットの 1 つは、幅広い種類のオペレーションを表現できることです。Spanner のエンジンを慣れ親しんだ PostgreSQL 言語で利用可能とするだけでなく、Spanner の PostgreSQL Interface は、より多くの PostgreSQL 機能をサポートできるよう Spanner を拡張することを目指しています。
最初に重点を置いたのは、一般的な PostgreSQL データ型でした。たとえば、Spanner の NUMERIC(38) を拡張することで、PostgreSQL 方式の任意精度数値と Postgres に実装された正規化 JSONB データ型のサポートを追加しました。また、データ型に加えて、クエリ内での NULL 基準の並べ替え(例: NULLS FIRST/LAST)や PostgreSQL から取得される期待値にあわせたインデックスもサポートしました。今後 Spanner に新機能を追加する際には、その機能が Postgres に適合するように気を配りつつ、Spanner に追加すべき機能を計画する際には、PostgreSQL を利用しているユーザーの力となる変更を加えられるように検討していきます。
PostgreSQL クライアント、エコシステムのサポート
PostgreSQL クエリ、スキーマ、メタデータのサポートは、要素の一部でしかありません。PostgreSQL のクエリ構文のサポートに加えて重要な情報は、PostgreSQL クライアントが Spanner データベースに直接接続できるようになった点です。これは、既存ツールを使用する際に Spanner を PostgreSQL データベースとして扱えるようにすることを目的としています。
PostgreSQL 通信プロトコルは、同一マシンまたは(最悪の場合)同一ラックをサーバーとして動作しているクライアントに対して最適化されます。これにはいくつかのトレードオフがあり、クライアントの簡略化などの要素を分散パフォーマンスの効率化よりも優先します。
- 関連するメタデータの取得などのクエリを 1 件実行するには、複数のメッセージが必要な場合があります。これは、接続レイテンシが増加した場合に(例: 2 つのデータセンターを接続する場合)、クエリのレイテンシを著しく増加させる原因となります。このことは、同一マシンで動作している場合は問題ありませんが、別個のデータセンターや大陸で動作する際には問題となります。
- クライアントが理解できるのは、「サーバー」への接続方法だけです。シャーディング済みの PostgreSQL を使用した場合、データを保存しているサーバーの特定やその場所に応じてクエリをルーティングするプロトコルにネイティブで組み込まれている仕組みは存在しません。
- セッションは通信が切断されると再開できません。たとえば、ロードバランサがタイムアウトした、オンプレミスのデータセンターへの接続が道路工事により物理的に破壊された、エンドポイントとなるサーバーがオーバーロードして処理の再分散が必要になった、セキュリティ アップデートのためにクライアントの再起動が必要になった場合などには、進行中のトランザクションを中断する必要があります。
数多くの PostgreSQL ユーザーが、これらの問題の解決に PGBouncer などの PostgreSQL プロキシ サーバーを使用しています。こうしたツールは上記の問題を大幅に軽減できます。しかし、PostgreSQL の通信プロトコルは最新のクラウドよりも長い歴史があるため、単一のオペレーションから複数のサーバーへのデータのルーティングや、通信切断時などの透明性の高いフェイルオーバーといったコンセプトを、ネイティブではサポートしていません。PGBouncer のようなツールはこれらの問題を完全には解決できません。
おすすめのソリューションは、クライアント コンピュータ上またはクライアント ネットワーク上で動作するプロキシである PGAdapter です。このソリューションにより、サーバーラック内で軽量級の PostgreSQL クライアントを動作できます。その名が示唆するように、このソリューションは、PostgreSQL 通信プロトコルを Spanner のグローバルに利用可能なエンドポイントを使用する Spanner 独自の gRPC ベース プロトコルに対して適合させる、あるいは変換します。
広範囲に分散したデータベースに対して接続をルーティングする必要がある場合、PGAdapter はこの処理に必要なロジックを確実な高パフォーマンスでカプセル化します。また、指定のリクエストを適切なデータセンターにルーティングするために必要なロジックに対応しています。シンプルなオペレーションを自動でバッチ処理して往復レイテンシを減らすこともできます。公衆インターネット経由でのルーティングが必要なクエリにときおり発生する障害から回復することもできます。これらは、PGAdapter が対応可能な問題のほんの一部にすぎません。
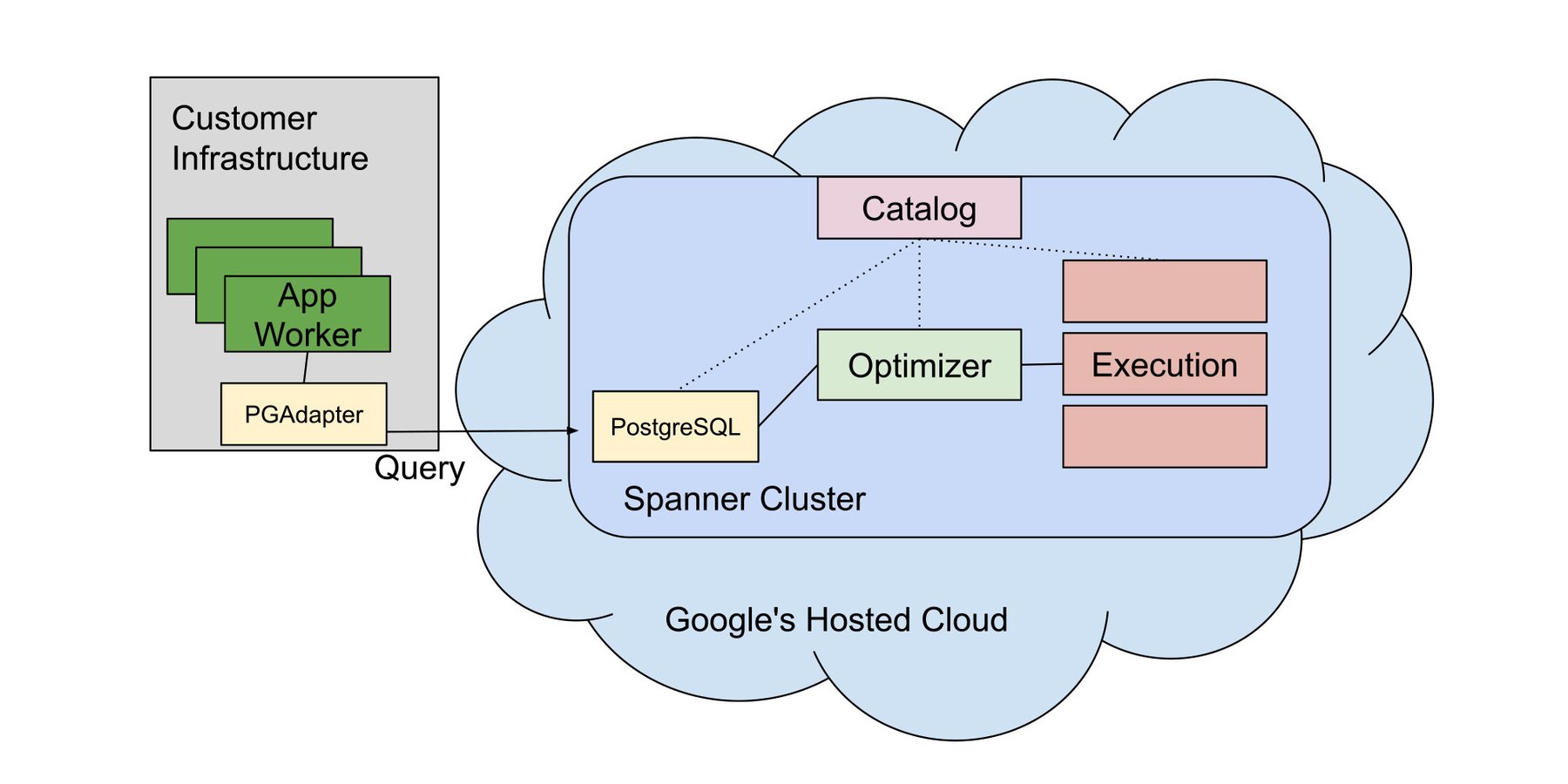
PGAdapter があれば、PostgreSQL のネイティブ アプリケーションを改造することなくそのまま Spanner に接続でき、最新のクラウド環境やインターネット環境でときおり発生するチャーンや障害に対して堅牢なプロトコルを使用することもできます。
Spanner とのインテグレーションをより強化したいお客様には、Spanner のネイティブ クライアントとドライバを使用して Spanner PostgreSQL データベースに接続するという選択肢もあります。このアプローチを JDBC とあわせて使用することを特におすすめします。PGAdapter を介した PostgreSQL の JDBC ドライバの使用は完全にサポートされています。ですが、特に JDBC に関して、PostgreSQL の JDBC ドライバ + PGAdapter の併用から Spanner の JDBC ドライバへの移行はほぼシームレスな体験であったことや、PGAdapter が不要になることで生じる運用の簡便さについて、数多くのユーザーが発信しています。また、Postgres には存在しないような Spanner 機能を利用しやすくなります。存在しない以上、こうした機能は PostgreSQL ドライバではサポートされていません。機能によっては、あるデータベースではサポート対象でも他のデータベースではサポート対象外のことがあるため、それぞれの用途に最適な機能を見つけ出すことをおすすめします。
まとめ
Spanner の PostgreSQL Interface が提供する高度なインテグレーション体験では、PostgreSQL 環境を利用しているユーザーが、慣れ親しんだツールと専門知識を使って、グローバルに分散された高可用性アプリケーションを簡単に作成できるようになります。Google は、Spanner の既存システムに PostgreSQL のサポートを追加するのではなく、PostgreSQL 互換のクエリ構文とクライアントをサポートするように Spanner を拡張しました。この取り組みが PostgreSQL 専用機能を実現し、Spanner に関して実施中の、より優れた機能を追加していく取り組みの指針となっています。
ぜひ今すぐに Spanner PostgreSQL Interface をお試しいただき、感想をお聞かせください。90 日間無料または月額 $65 というわずかな金額で Spanner をお試しいただくと、Spanner PostgreSQL データベースを新規または既存の Spanner インスタンスに追加できます。
ー ソフトウェア エンジニア Adam Seering



