Cloud Spanner の変更ストリームでトランザクション データをさらに活用
Google Cloud Japan Team
※この投稿は米国時間 2022 年 4 月 7 日に、Google Cloud blog に投稿されたものの抄訳です。
データは今日のデジタル エコノミーにおいて最も価値のあるアセットの一つです。データの価値を引き出す方法の一つとして、最初に収集したデータに新たな活力を吹き込む方法があります。Cloud Spanner のようなトランザクション データベースは、より効率的にデータを活用するために、データに対する段階的な変更をリアルタイムかつ大規模に取得します。Cloud Spanner は、ほぼ無制限のスケーリング、強整合性、業界をリードする最大 99.999% の可用性を備えた Google のフルマネージド リレーショナル データベースです。
トランザクション データベースで取得された増分データをダウンストリーム システムで使用する従来の方法では、変更データ キャプチャ(CDC)を利用します。これにより、削除されたアカウントや更新された在庫数など、データベースへの変更に基づいて動作をトリガーできます。
本日は、近日中にリリースされる Spanner 変更ストリームを発表します。これにより、Spanner データベースから変更データを取得し、他のシステムと簡単に統合して新たな価値を引き出すことができます。
Spanner の変更ストリームは、挿入、更新、削除を追跡するという従来の CDC の機能よりはるかに高度なものです。非常に柔軟な構成が可能であり、特定のテーブルや列の変更だけでなく、データベース全体の変更を追跡できます。リアルタイム解析のために Spanner から BigQuery に変更をレプリケートしたり、Pub/Sub を使用してダウンストリーム アプリケーションの動作をトリガーしたり、コンプライアンスのために Google Cloud Storage(GCS)に変更を保存したりできます。これにより、最新のデータを確保してビジネスの成果を最適化できます。
変更ストリームは、カスタムの Dataflow 処理パイプラインまたは変更ストリームの読み取り API を含み、すぐに使用できるコネクタを通じて変更データを他の Google Cloud サービスやパートナー アプリケーションと統合するために幅広いオプションを提供しています。
Spanner は 1 秒間につき 12 億回以上のリクエストを常に処理しています。変更ストリームは Spanner に直接組み込まれているため、業界屈指の可用性とグローバル スケールが得られるだけでなく、追加のリソースをスピンアップする必要もありません。Spanner データベースを保護しているものと同じ IAM 権限を使用して変更ストリームのクエリにアクセスできます。変更ストリームのクエリは spanner.databases.select によって保護され、変更ストリームの DDL オペレーションは spanner.databases.updateDdl によって保護されています。
変更ストリームの実例
このセクションでは、Spanner から BigQuery の分析データ ウェアハウスに変更データを送信する変更ストリームの設定方法について説明します。
変更ストリームを作成する
前述のとおり、変更ストリームはデータベース全体、テーブルのセット、またはデータベースの列のセットで変更を追跡します。各変更ストリームには 1~7 日間の保持期間を設定できます。また、複数の変更ストリームを設定して、特定のビジネスの目標に必要な変更を正確に追跡することもできます。
まず、InventoryLedger というテーブルで変更ストリームを作成します。このテーブルには 7 日間の保持期間があり、InventoryLedgerProductSku と InventoryLedgerChangedUnits の 2 つの列で在庫の変更を追跡します。
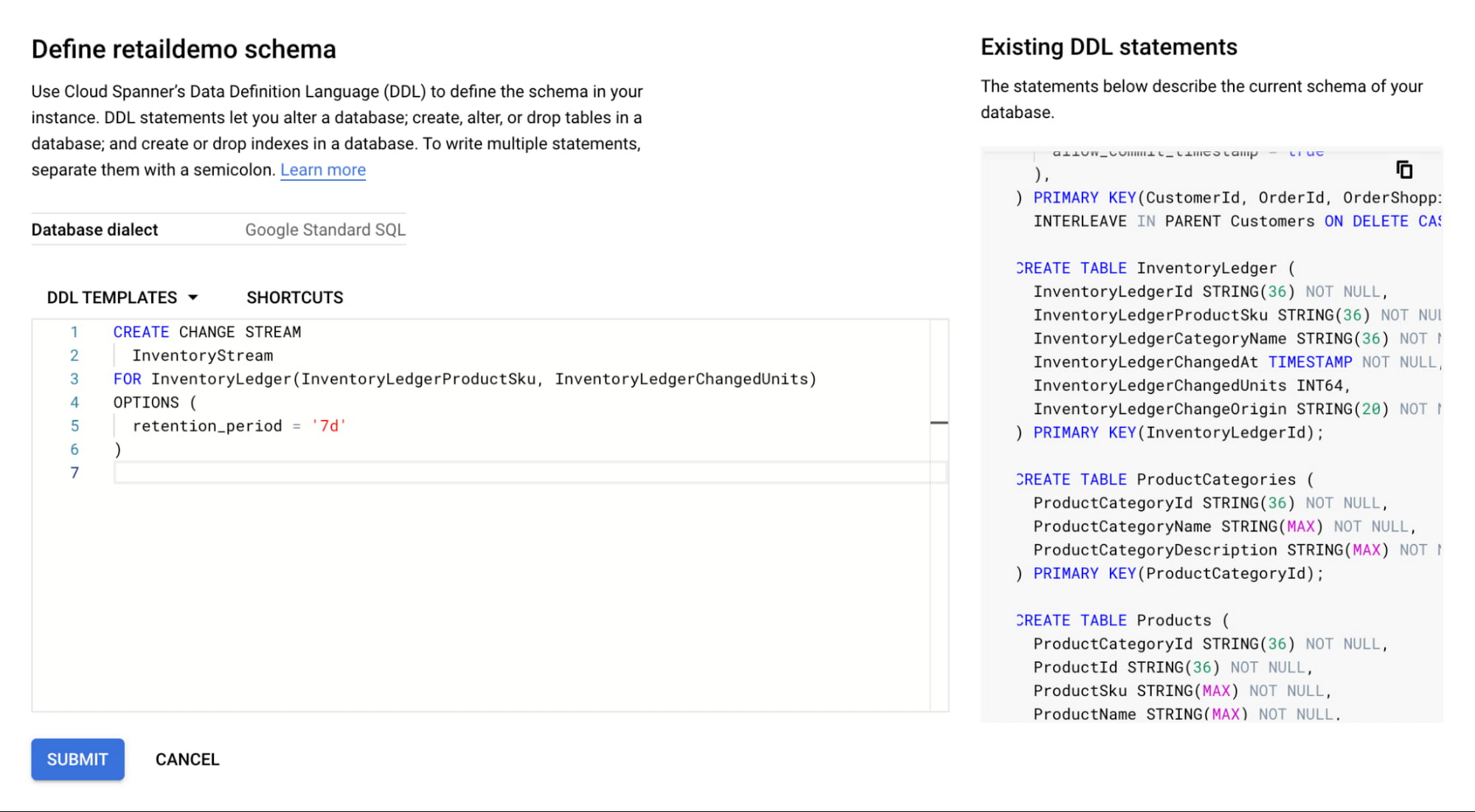
レコードを変更する
各変更レコードには、主キー、commit タイムスタンプ、トランザクション ID を含む豊富な情報が含まれています。もちろん、そのなかには変更されたデータの新旧の値も含まれます(該当する場合)。これにより、変更レコードをトランザクション全体として commit タイムスタンプに基づいて順番に、またはビジネスニーズに合わせて到着したときに個別に、簡単に処理できます。
在庫の例に戻ります。InventoryLedger テーブルで変更ストリームを作成したので、このテーブルのすべての挿入、更新、削除は InventoryStream 変更ストリームに公開されます。これらの変更は InventoryLedger テーブルの commit と強整合性を保ちます。トランザクションの commit が成功すると、関連する変更が自動的に変更ストリームに永続化されます。変更レコードの見逃しを心配する必要はありません。
変更ストリームを処理する
ユースケースに応じて変更ストリームを処理する方法は数多くあります。
アナリティクス: 変更レコードを変更ログのセットとして、またはテーブルを更新することで BigQuery に送信できます。
イベントのトリガー: ダウンストリーム システムによってさらなる処理を行うために、Pub/Sub に変更ログを送信できます。
コンプライアンス: アーカイブの目的で変更ログを Google Cloud Storage に保持できます。
変更ストリーム データを処理する最も簡単な方法は、Dataflow 用の Spanner コネクタを使用することです。このコネクタにより、Dataflow の構築済みパイプラインを BigQuery、Pub/Sub、Google Cloud Storage に活用できます。次の図は、この変更ストリームを処理し、変更データを BigQuery に直接インポートする Dataflow パイプラインを示しています。
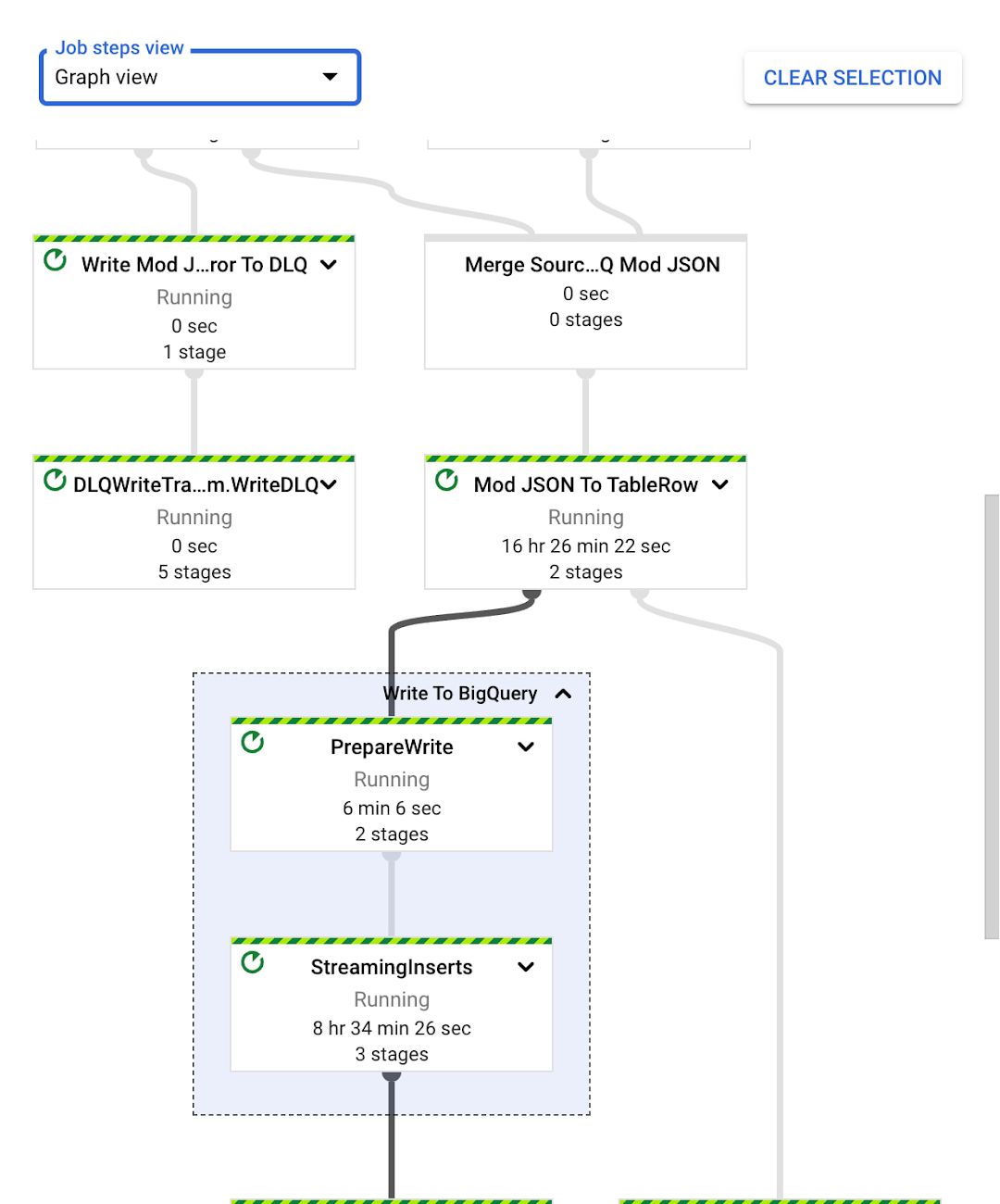
別の方法として、カスタムの Dataflow パイプラインを構築し、Apache Beam を使用して変更データを処理する方法もあります。この場合、変更データを DataChangeRecord オブジェクトの Apache Beam PCollection として出力する Dataflow コネクタが提供されます。
さらに柔軟性を高めるために、基盤となる変更ストリームのクエリ API を使用できます。クエリ API は変更ストリームから直接読み取って独自のコネクタを実装し、任意のパイプラインに変更をストリーミングできる高度なインターフェースです。クエリ API 側では、変更ストリームは複数のパーティションに分割されます。これにより、スループットを向上させるために変更ストリームのクエリを並行して実行できます。Spanner は負荷とサイズに基づいてこれらのパーティションを動的に作成します。パーティションは Spanner のデータベース スプリットに関連付けられ、変更ストリームが Spanner の他の部分と同じように簡単にスケーリングできるようにします。
変更ストリームを使ってみる
変更ストリームでは、目的が BigQuery での分析、ダウンストリーム アプリケーションのイベントのトリガー、またはコンプライアンスやアーカイブのいずれであっても、必要な場所に Spanner のデータを従わせることができます。変更ストリームは非常に柔軟な構成が可能なため、必要としているデータや、ビジネスにとって重要な期間の変更データを正確に取得できます。また、 Spanner に組み込まれている機能であるため、ソフトウェアをインストールせずに外部整合性、高スケール、最大 99.999% の高可用性を得ることができます。
変更ストリームの使用に追加料金は必要ありません。通常の Spanner 料金の場合、変更データの追加コンピューティングとストレージのみお支払いいただきます。
Spanner の利用を開始するには、インスタンスを作成するか、Spanner Qwiklabs でお試しください。
お客様が Spanner の変更ストリームを活用し、データからより多くの価値を引き出せることを期待しております。
- Cloud Spanner プロダクト マネージャー Mark Donsky
- エンジニアリング マネージャー Eike Falkenberg