PLAID が Bigtable を使用して実現した真のリアルタイム ユーザー解析
Google Cloud Japan Team
※この投稿は米国時間 2023 年 6 月 23 日に、Google Cloud blog に投稿されたものの抄訳です。
編集者注: 今回お話を伺うのは PLAID です。同社が開発した KARTE は、パーソナライズされたリアルタイムかつシームレスなエクスペリエンスをユーザーに提供できるようビジネスを支援するカスタマー エクスペリエンス プラットフォーム(CxP)です。PLAID は最近、Cloud Bigtable を使用してリアルタイム ユーザー解析エンジンを再構築し、レイテンシを 10 ミリ秒以内に抑えることに成功しました。今回は、その方法の詳細をご紹介いただきます。
PLAID は、多数の Google Cloud プロダクトを利用して幅広いユースケースのデータを管理しています。たとえば、リレーショナル ワークロードには AlloyDB for PostgreSQL、エンタープライズ データ ウェアハウジングには BigQuery、エンタープライズ グレード NoSQL データベース サービスには Bigtable を使用しています。今回、再び Bigtable を利用して、当社の核となるカスタマー エクスペリエンス プラットフォームを再構築しました。「Blitz」というリアルタイム ユーザー解析エンジンです。
Blitz には非常に高い基準が求められます。当社の環境はトラフィックが多く、1 秒あたり 100,000 件以上のイベントを受け取り、Blitz はそれをエンドツーエンドで数百ミリ秒以内に処理する必要があります。このブログ投稿では、当社が Bigtable を使用して Blitz を再構築し、大量の書き込みトラフィックがある環境で真のリアルタイム解析を実現した手法をご紹介します。この快挙を成し遂げるために、つまり高スケーラビリティかつ低レイテンシの分散キューを実装するために、アーキテクチャ面でどのような選択をしたか、またどのような実装手法を採用したかについて詳しく掘り下げます。
リアルタイム ユーザー解析の定義
まず、当社における「リアルタイム ユーザー解析」の定義についてご説明しましょう。リアルタイム ユーザー解析エンジンでは、あるユーザーのイベントが発生すると、イベント履歴とユーザーに固有の統計情報に基づいてさまざまなアクションを実行できます。以下に、パーソナライズされたアクションの対象となる特定のユーザーを絞り込む、イベントデータとルール定義の例を示します。
図 1: イベントデータ
図 2: ルール定義の擬似コード
これは、「userId-xxx」が「会員」であり、1 年間で平均 10,000 円以上を購入し、先週のセッション数が 10 以上であるにもかかわらず、ほとんど購入に至っていないユーザーであるかどうかを検証するルールの擬似コードです。
一般的には、リアルタイム解析とは、統計情報に数秒、場合によっては数分の遅れが出る「ほぼリアルタイム」の分析を意味します。しかし、真のリアルタイムを実現するには、ユーザー統計情報が常に最新である必要があり、ダウンストリーム サービスで利用できる結果にすべての過去のイベント履歴が反映されていなければなりません。目標は非常にシンプルですが、ユーザー統計情報を常に最新の状態に保つことは技術的に困難です。特に、1 秒あたり 100,000 件以上のイベントが発生し、数百ミリ秒以内のレイテンシが求められるトラフィックの多い環境では、なおさら難しくなります。
以前のアーキテクチャ
当社の以前の解析エンジンは、リアルタイム解析コンポーネント(Track)とユーザー統計情報を非同期に更新するコンポーネント(Analyze)の 2 つから構成されていました。
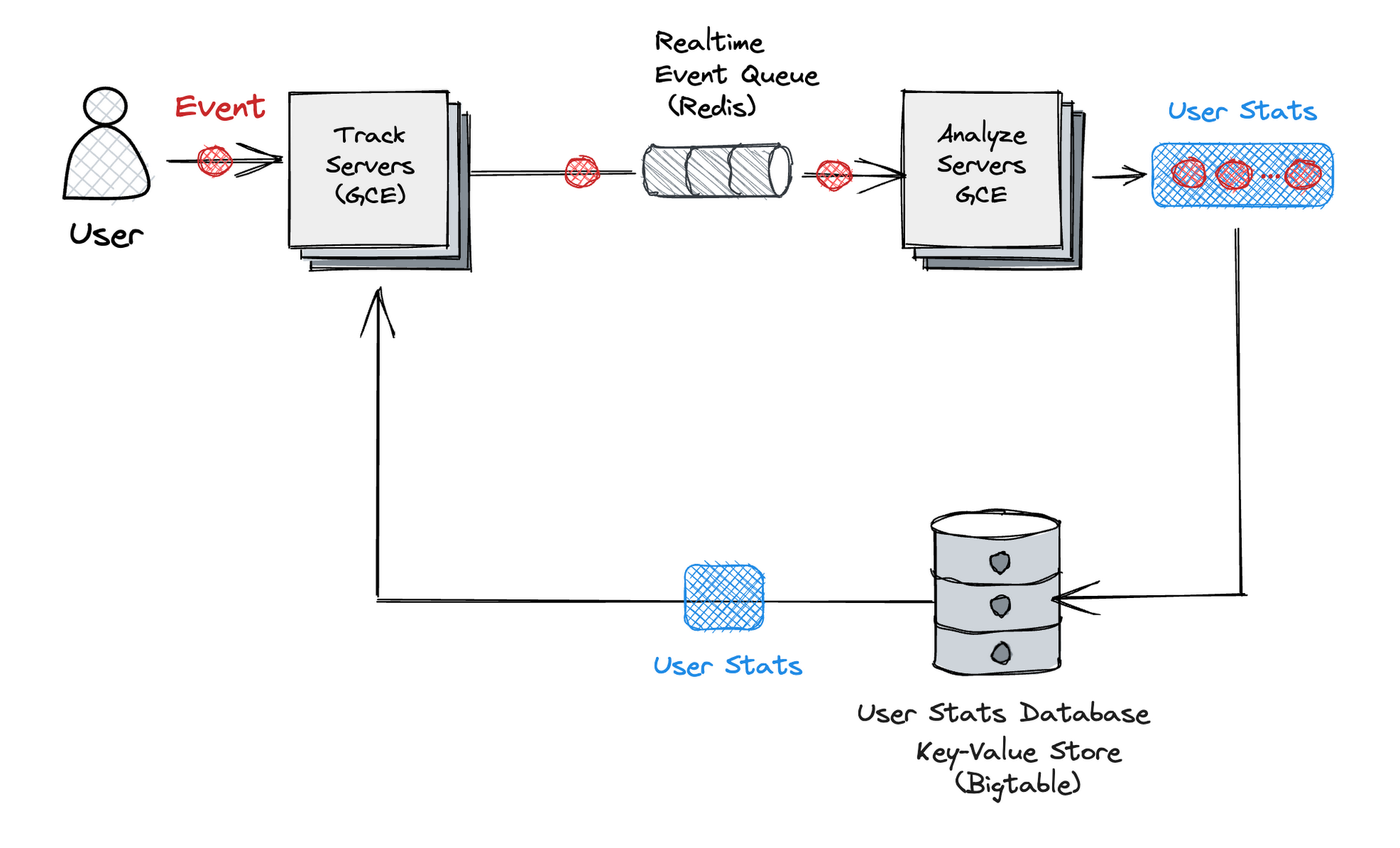
このアーキテクチャの重要なポイントは以下のとおりです。
リアルタイム コンポーネント(Track)では、Key-Value ストアから事前に生成されたユーザー統計情報は読み取り専用となり、書き見込みは一切行われません。
Analyze では、特定の期間にわたってストリーミング ジョブがイベントをロールアップします。
しかし、当社の分散キューでは以下の厳格なパフォーマンス要件を満たす必要がありました。
高スケーラビリティ - キューは、高トラフィックのイベントの数に合わせてスケールできなければなりません。日中のピーク時には、書き込みリクエストの参照値が 1 秒あたり約 30,000 オペレーション、書き込みデータの量が毎秒 300 MiB になります。
書き込みと読み込み両方で 10 ミリ秒以内の迅速な処理を実現する低レイテンシ。
しかし、既存のメッセージング サービスでは、高スケーラビリティと低レイテンシの両方の要件を同時に満たすことができませんでした。以下の図 4 を参照してください。

新しいリアルタイム解析アーキテクチャ
前述した技術面での課題を考慮して改良を加えたのが、以下の図 5 に示すアーキテクチャです。既存のアーキテクチャからの変更点は以下のとおりです。
リアルタイム サーバーを 2 つに分割しました。最初に、フロントエンド サーバーが分散キューへのイベントの書き込みを処理します。
リアルタイム バックエンド サーバーが分散キューからイベントを読み込み、分析を実行します。
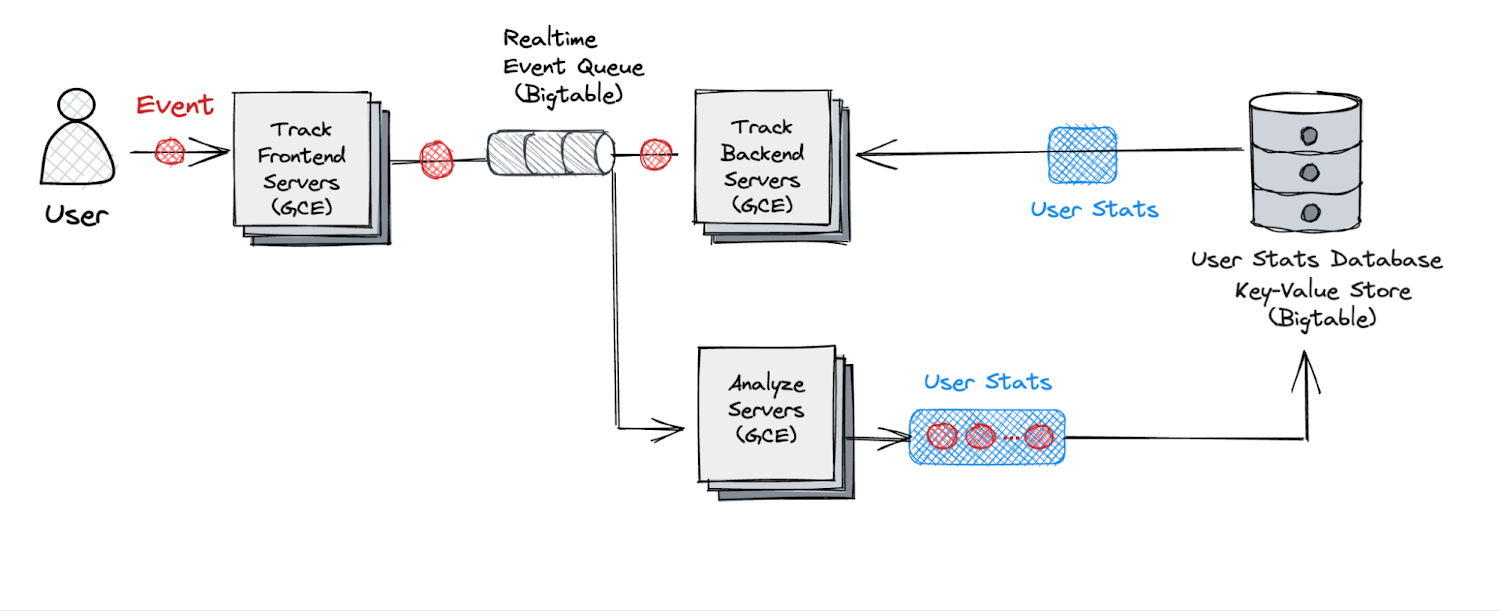
スケーラビリティとレイテンシの目標を両方とも達成するために、Bigtable を利用することにしました。これは、当社が分散キューを実装するために低レイテンシの Key-Value ストアとしてすでに利用していたソリューションでした。以下で、具体的な方法をご説明します。
Bigtable は主に、数ミリ秒(1 桁台)のレイテンシを実現し、水平にスケールすることが可能な Key-Value ストアとして知られています。当社が注目したのは、Bigtable では、行キーの開始と終了を指定したレンジスキャンの実行時間も短いという点です。
具体的な分散キューのスキーマは以下のようになります。
重要なポイントは、最後に追加されたイベントのタイムスタンプです。これにより、イベントのタイムスタンプの開始と終了を指定して、レンジスキャンを実行できるようになります。
さらに、Bigtable のガベージ コレクション機能を使用して有効期間(TTL)を設定することで、キューから古いデータを削除する機能を簡単に実装できました。
これらの変更を実装することで、反映されていないイベントがあるかどうかにかかわらず、リアルタイム解析バックエンド サーバーでユーザー統計情報を常に最新の状態に保つことができるようになりました。
Bigtable のその他のメリット
Bigtable を使用して分散キューを実装したことで当社のアーキテクチャにもたらされたものは、スケーラビリティと低レイテンシだけではありませんでした。費用対効果と管理のしやすさというメリットもありました。
費用対効果
SSD ストレージ タイプの素晴らしいスループットと、古いデータを削除してデータの量を一定に保つガベージ コレクション機能のおかげで、当初想定していたものより大幅に少ない費用でリアルタイム分散キューを運用できています。当社の計算では、Pub/Sub で同じワークロードを実行する場合と比較して、運用の費用は半分以下です。
管理のオーバーヘッドが少ない
インフラストラクチャ運用の視点では、Bigtable の自動スケーリング機能を使用することで運用の費用を削減できています。リアルタイム キューへのリクエストが急増した場合、Bigtable クラスタが CPU の使用状況に基づいて自動的にスケールアウトします。当社がこのリアルタイム分散キューの運用を開始して 1 年以上になりますが、運用は安定しており、手間も最小限で済んでいます。
リアルタイム解析エンジンの強化
このブログ投稿では、Bigtable を使用して当社の核となるリアルタイム ユーザー解析エンジン、Blitz を改良した経験をご紹介しました。トラフィックが多い状況においても、リアルタイム解析エンジンで一貫性のあるユーザービューを実現できました。この成功の鍵となったのは、Bigtable を革新的な方法で利用して、高スケーラビリティと低レイテンシという両方の要件を満たす分散キューを実装できたことです。Bigtable の低レイテンシの Key-Value ストアとレンジスキャン機能を利用することで、水平にスケール可能でレイテンシが 10 ミリ秒以内の分散キューを作成することができました。
当社の経験とアーキテクチャ面での選択が、有用な事例として、リアルタイム解析システムを進化させることを目指す世界中のエンジニアの皆様のお役に立てば幸いです。当社は、Bigtable の機能を活用すれば、リアルタイム解析エンジンのパフォーマンスと整合性を新たなレベルに押し上げ、最終的にはユーザー エクスペリエンスの改善と豊富な情報に基づいた意思決定を実現できると考えています。
リアルタイム解析をレベルアップするためのソリューションをお探しなら、コンテンツ エンゲージメント分析、音楽のおすすめ、オーディエンス セグメンテーション、不正行為の検出、小売分析など、幅広いユースケースに使用されている Bigtable をご検討ください。


