自動インクリメント キーの Spanner への移行におけるベスト プラクティス
Google Cloud Japan Team
この投稿は米国時間 2024 年 1 月 24 日に、Google Cloud blog に投稿されたものの抄訳です。
編集者注: このシリーズの前回の投稿では、Spanner での主キーのデフォルト値をご紹介しました。また、UUID と整数の SEQUENCE を使ってデータベースのキーを自動的に生成する方法も説明しました。今回の投稿では、こうした新しい機能を使用して他のデータベースから Spanner にスキーマとデータを移行する方法について説明します。この方法を使用することで、ダウンストリーム アプリケーションへの変更を最小限に抑え、Spanner のベスト プラクティスを実装することができます。
Spanner は、あらゆる規模の環境に最高水準の可用性と整合性を付与できるように設計された分散型リレーショナル データベースです。リソースをシームレスにスケールアップ、スケールダウンできるため、継続的な運用を維持しながらリアルタイムのニーズに応じてコストを最適化できます。ゲーム、小売、金融サービス、その他多くの業界のお客様が、最も要求の厳しいワークロードに Spanner を利用しています。
Spanner への移行
こうしたワークロードの多くは始めから Spanner で運用されていたわけではありません。リレーショナルかそうでないかを問わず、さまざまなデータベースを運用していたお客様が、Spanner のシームレスなスケーリングとフルマネージドの環境を活用したいと考え、Spanner を利用するようになったのです。Spanner には、移行をスムーズに行うためのツールセットとベスト プラクティスが用意されています。Spanner 移行ツールでは、MySQL や PostgreSQL 経由のテラバイト規模のデータベースの評価、スキーマ変換、データ移動を行うことができます。より広範な移行ガイダンスについては、Spanner ドキュメントをご覧ください。
この投稿では、自動生成キー、そのなかでも特に自動インクリメントのシーケンシャル整数と UUID を使用しているデータベースの移行を中心に見ていきます。
以下の移行戦略により、重要な要件に対処します。
- 移行するキーの忠実性と正確性を確保する
- キー自体の型や値の変更など、ダウンストリーム アプリケーションの変更を最小限に抑える
- システム間でライブ カットオーバーを行う場合など、移行元または移行先のデータベースのどちらかでキーが生成され、データが両データベース間で同期されるようなレプリケーションのシナリオをサポートする
- パフォーマンスとスケーラビリティのために Spanner のベスト プラクティスを実装する
シーケンシャル キーの移行
まず、リレーショナル ワークロードで Spanner を使用する最も一般的なシナリオから説明します。MySQL のAUTO_INCREMENT、PostgreSQL の SERIAL、SQL Server や Oracle の標準の IDENTITY 型など、単調なシーケンシャル キーを使用する単一インスタンスのデータベースを移行するシナリオです。単一のマシン上で書き込みを管理するデータベースの場合、シーケンシャル キーを提供するカウンタはシンプルなものです。しかし、順序付けされたキーは、Spanner のような分散システムではパフォーマンスのホットスポットの原因となる可能性もあります。
大まかに言うと、シーケンシャル キーを Spanner に移行するための戦略は次のようになります。
- ソース データベースの場合と同様に、整数の主キーを使用して Spanner でテーブルのコピーを定義する。
- Spanner でシーケンスを作成し、テーブルの主キーをデフォルト値に使用するよう設定する。
- ソース データベースから Spanner にデータとキーをそのまま読み込む。これには、Spanner 移行ツールや下位の Dataflow テンプレートなどを使用できます。
- 必要に応じて、任意の依存関係のテーブルに外部キー制約を設定する。
- 新しいデータを挿入する前に、既存のキーの範囲内の値をスキップするように Spanner のシーケンスを構成する。
- 従来と同様に新しいデータを挿入し、シーケンスがデフォルトでキーを生成するようにする。
では、テーブルと関連のシーケンスの定義から見ていきましょう。Spanner では新しい SEQUENCE オブジェクトを定義し、移行先テーブルのデフォルトのプライマリ値として設定します。たとえば、GoogleSQL 言語を使うと次のようになります。
必須である bit_reversed_positive のオプションは、シーケンスによって生成される数値が 0 より大きいことを示しますが、順序付けはされません(ビット反転シーケンスについて詳しくは、入門編の投稿をご覧ください)。生成される値は INT64 型です。
既存の行をソース データベースから Spanner に移行する際、行のキーは変更されません。新しい挿入で主キーを指定しない場合、Spanner は自動的に GET_NEXT_SEQUENCE_VALUE() 関数を呼び出して新しい番号を取得します。これらの値は [1, 263] の範囲に均等に分散されるため、既存のキーとの競合が発生する可能性があります。競合すると、「キーはすでに存在します」というエラーになり、挿入は失敗します。これを防ぐには、既存のキーでカバーされている値の範囲をスキップするようにシーケンスを構成します。
たとえば、singers テーブルが PostgreSQL から移行され、そのキーである singer_id が SERIAL 型であるとします。
列の値は単調に増加します。移行後、singer_id の最大値を取得します。
返された値が 20,000 だったとしましょう。この場合、[1, 21000] の範囲をスキップするように Spanner のシーケンスを構成します。余分な 1,000 は、最初の一括移行後のソース データベースへの書き込みに対応するためのバッファとして機能します。これらの値は通常、その後複製されるので、その際も競合が発生しないようにする必要があります。
下の図は、移行したいくつかの行と、移行後に Spanner に挿入された新しい行を示しています。
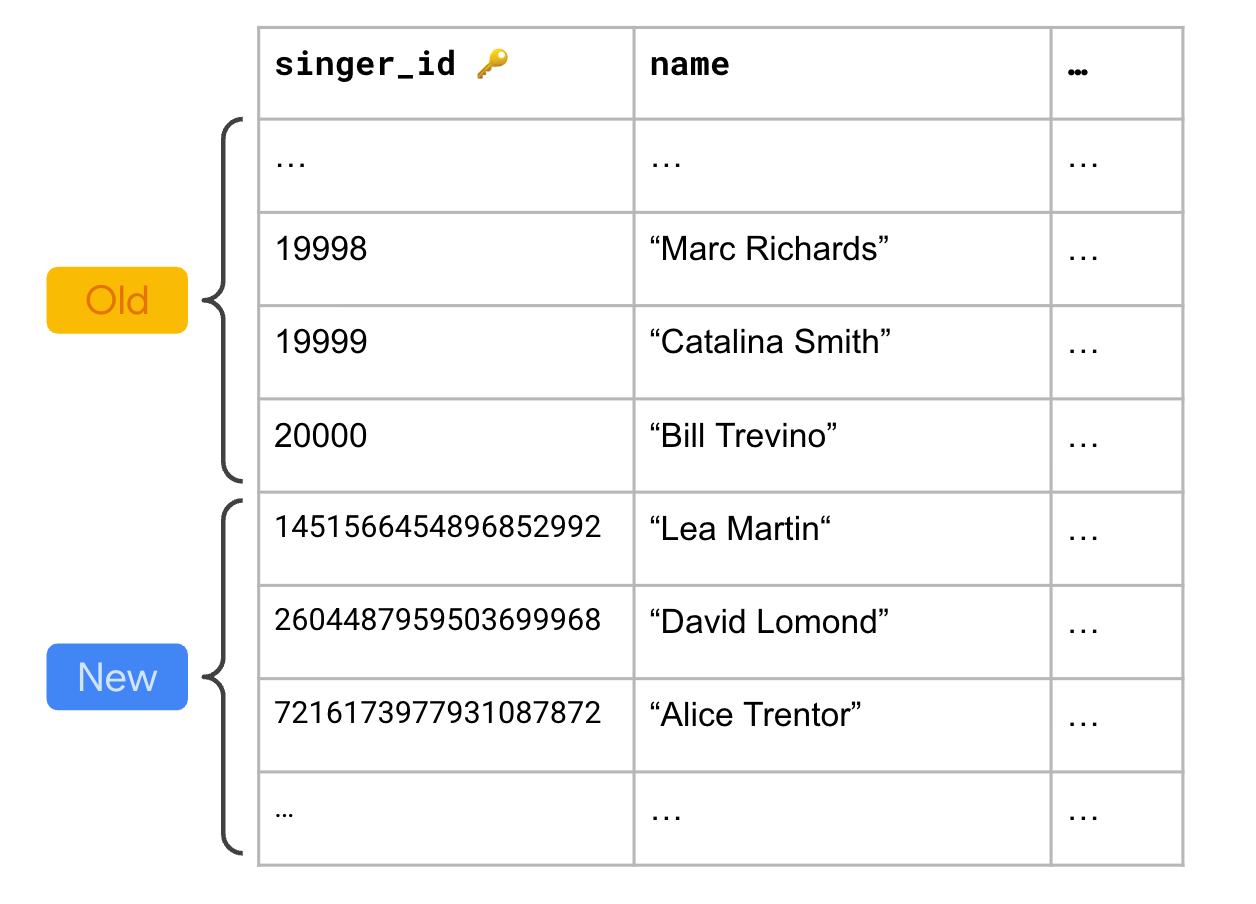
これで、Spanner で生成される新しいキーは、移行元の PostgreSQL データベースで生成されたキーの範囲と競合しなくなることが保証されます。
マルチデータベースの使用
この範囲スキップのコンセプトをさらに発展させて、Spanner とアップストリーム データベースのどちらかが主キーを生成するシナリオをサポートできます。たとえば、移行のカットオーバー時にどちらかの方向にレプリケーションを有効にし、障害復旧を確保するといったことが可能です。
これを行うために、各データベースが重複しないキー値の範囲を持つように構成できます。もう一方のデータベースの範囲を定義する際は、skipped range 構文を使用して Spanner のシーケンスにその範囲をスキップするように指示できます。
たとえば Google Cloud では、音楽トラッキング アプリケーションの一括移行後、PostgreSQL から Spanner にデータを複製し、カットオーバーにかかる時間を短縮します。Spanner でのアプリケーションの更新とテストが終わったら、PostgreSQL から Spanner にカットオーバーして、更新と新しい主キーの記録システムを Spanner にします。その際、データベース間のデータのフローを逆にし、問題が発生した場合に元に戻す必要が生じることを想定して PostgreSQL インスタンスにデータを複製します。
このシナリオでは、PostgreSQL の SERIAL キーは 32 ビットの符号付き整数ですが、Spanner キーはそれより大きな 64 ビット数なので、以下のことを行います。
1. PostgreSQL では、キー列が 64 ビット列または bigint になるように変更します。
2. singer_id に使用されるシーケンス singers_singer_id_seq の型は引き続き int なので、その最大値はすでに 231-1 です。念のため、必要に応じて PostgreSQL データベースのテーブルに CHECK 制約を設定し、singer_id の値が確実に 231-1 以下になるようにします。
3. Spanner では、範囲 [1, 231-1] をスキップするようにシーケンスを変更します。
4. PostgreSQL から Spanner、Spanner から PostgreSQL の両方のフローをデプロイし、使用をテストします。
この手法を使用すると、PostgreSQL は常に 32 ビットの整数空間にキーを生成しますが、Spanner のキーは 64 ビットの整数空間に制限されます。64 ビット整数空間は 32 ビット数値すべての集合より大きく、将来の拡大のための余裕が十分にあります。これにより、両システムが確実に競合しないキーを独立して生成できるようになります。
UUID の移行
UUID 主キーは、一般的にシーケンスの整数キーよりも移行が簡単です。UUID(具体的には v4)は、生成される場所に関係なくほぼ一意になります(この衝突確率は、統計学の誕生日問題を応用して導くことができます)。そのため、他の場所で生成された UUID キーは、Spanner で生成された新しい UUID キーと簡単に統合でき、その逆もまた同様です。
UUID キーの移行のおおまかな戦略は次のようになります。
-
PostgreSQL 言語のデフォルトの式である
GENERATE_UUID()またはspanner.generate_uuid()で文字列の列を使用して、Spanner で UUID キーを定義します。 -
ソースシステムからデータをエクスポートして、UUID キーを文字列としてシリアル化します。
-
キーをそのままの状態で Spanner にインポートします。
-
必要に応じて外部キーを有効にします。
Spanner では、UUID 主キーの列を STRING 型または TEXT 型として定義し、そのデフォルト値として GENERATE_UUID() を割り当てます。移行中、ソース データベースから Spanner へ、キーの値を含めて既存の行のすべての値を移行します(詳細は、移行ガイドをご覧ください)。移行後、新しい行が挿入されると、Spanner は GENERATE_UUID() を呼び出して UUID の新しい値を生成します。たとえば、主キーの FanClubId は、FanClubs テーブルに新しい行を挿入すると、UUIDv4 の値を取得します。
独自の主キーを移行する
ビット反転のシーケンスと UUID は、Spanner で主キーとして使用されたときに大規模なホットスポットにならない一意の値を提供します。設計上、値の順序は保証されません。しかし、アプリケーションの中には、値が十分に新しいかどうかを判定したり、新しく作成されたデータをシーケンス化したりするためにキーの順序を参照するものもあります。スケーリングのために手動でシャーディングされたデータベースは通常、独立したデータベース インスタンスの外で調整されたグローバル カウンタを利用します。
外部で生成された順序付きキーを Spanner で使用するには複合キーを作成します。複合キーで組み合わせる 1 つ目のコンポーネントは、シャード ID やハッシュなど均等に分散された値、2 つ目のコンポーネントは連続する数値にします。これにより、順序付けされたキー値は保持されますが、大規模なホットスポットが発生しません。
この例では、AUTO_INCREMENT 主キーを使用した MySQL テーブルである students を Spanner に移行しています。ダウンストリーム アプリケーションは学生 ID を生成し、ID はエンドユーザー(学生、教員など)と共有されます。
Spanner で、StudentId 列のハッシュを含む生成列を追加します。
今すぐ使用を開始する
Google Cloud は近ごろ、ユーザーにすでになじみのある SQL のコンセプトを使用して Spanner の主キーのベスト プラクティスを実装するために役立つ新機能を導入しました。本稿で詳しく説明した戦略を採用することで、他のリレーショナル データベースから自動インクリメントと UUID を移行する際に、ダウンストリームのアプリケーションの変更を最小限に抑え、Spanner のパフォーマンスと可用性を最大限に高めることができます。
Spanner の独自性や使用例について詳しくは、こちらをご覧ください。または、90 日間無料で、あるいは月額わずか 65 米ドルで、中断を伴う再構築やダウンタイムなしでビジネスの成長に合わせて拡張できる本番環境対応のインスタンスを実際にお試しください。
-ソフトウェア エンジニア Diem Tran
-シニア プロダクト マネージャー Justin Makeig


