重要なストレージ サービスを HBase から Cloud Bigtable に移行した Box のゲームプラン

Google Cloud Japan Team
はじめに
Box, Inc. は、企業と個人を対象とするクラウドベースのコンテンツ管理、コラボレーション、ファイル共有ツールのリーダーとして評価されている企業です。最近、私たちは、オンプレミスにデプロイされているスケーラブルな分散型ビッグデータ ストアである Apache HBase から、Google Cloud の HBase 対応 NoSQL データベースである Cloud Bigtable に移行することを決定しました。これにより、HBase での運用保守作業の削減、柔軟なスケーリング、コストの削減、ストレージ フットプリントの 85% の縮小など、クラウド マネージド データベースによる多くのメリットを実現しました。また、この移行により、Google Cloud のエンタープライズ データ ウェアハウスである BigQuery を利用して、複数の地理的リージョンでデータベースを実行できるようになりました。
では、どのようにこれを実現したのでしょうか。Cloud Bigtable を採用するためには、Box の最も重要なサービスの一つを移行する必要がありました。その安全なファイル アップロード機能とダウンロード機能は、Box のコンテンツ クラウドの中核をなすものです。また、ダウンタイムなしで 600 TB を超えるデータを移行する必要もありました。この投稿では、私たちがどのようにそれを実現したか、そして最終的に享受したメリットについて取り上げます。
背景
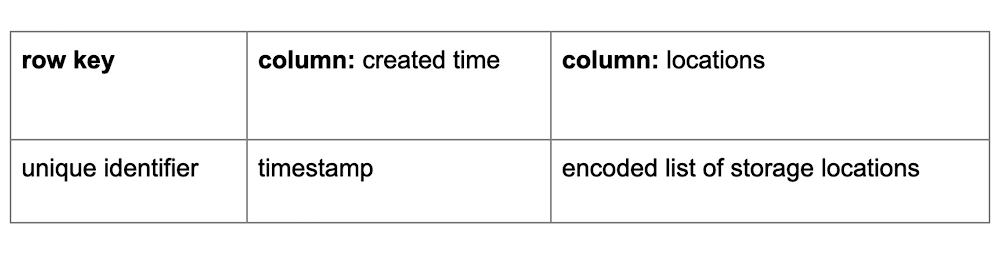
これまで、Box は HBase を使用して、以下の表のスキーマに基づいて顧客のファイル メタデータを保存してきました。これは、あるファイルから別のファイルの物理ストレージの場所までのマッピングを示すものです。このメタデータは、Storage Service と呼ばれる Kubernetes で実行されるサービスによって管理され、Box におけるすべてのアップロードとダウンロードで使用されます。私たちのスケールについて少し説明すると、移行の開始時には、6,000 億行と 200 テラバイトを超えるデータをそれぞれ格納する複数の HBase クラスタがありました。また、これらのクラスタは毎秒約 15,000 の書き込みと毎秒 20,000 の読み取りを受け取っていましたが、分析ジョブの何百万ものリクエストや、より高い負荷に対応するようにスケールできました。
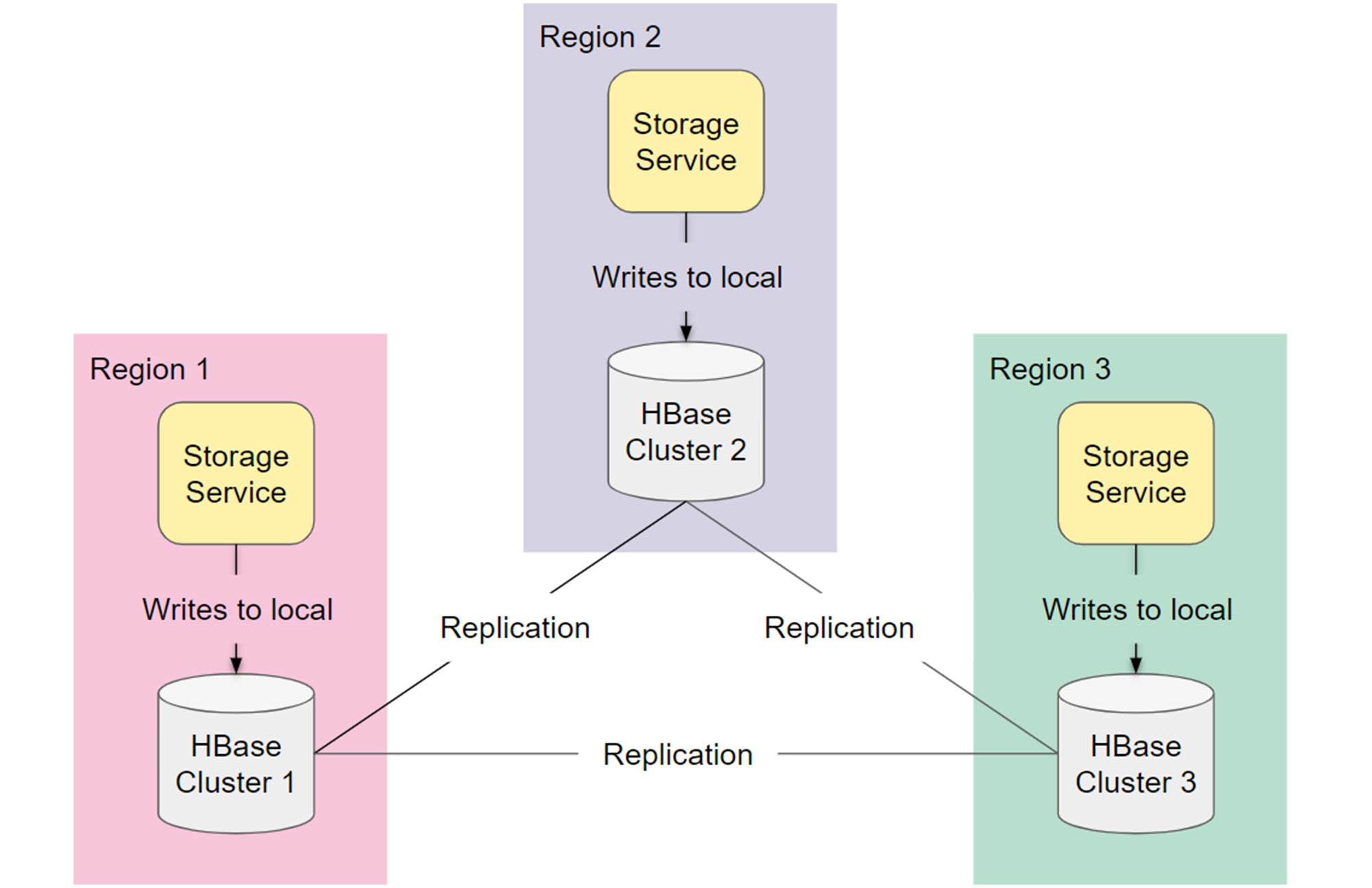
私たちの HBase アーキテクチャは、異なる地理的リージョンにまたがる完全に複製された 3 つのクラスタで構成されていました。高可用性のための 2 つのアクティブなクラスタと、定期的なメンテナンスに対応するための 1 つのクラスタです。各リージョンの Storage Service がローカルの HBase クラスタに書き込み、その変更が他のリージョンに複製されていました。読み取りでは、まず Storage Service がローカルの HBase クラスタから取得し、複製の遅延があった場合は他のクラスタにフォールバックしていました。
移行の準備
このユースケースに最適な Bigtable クラスタ構成を選択するために、移行前にパフォーマンス テストと非同期の読み取りおよび書き込みを行いました。詳細については、こちらの Box ブログの投稿をご覧ください。
Bigtable はメンテナンス ダウンタイムを必要としないため、障害復旧のために、3 つの HBase クラスタを、別々のリージョンにある 2 つの Bigtable クラスタに統合することにしました。これは大きなメリットでしたが、今度は 3 つのレプリカを 2 つのレプリカに統合するための最善の方法を見つける必要がありました。
理論的には、分割された書き込みと保証されたレプリケーションにより、3 つの HBase クラスタのメタデータはすべて同じものになるはずです。しかし、実際には、すべてのクラスタのメタデータがドリフトしており、Box の Storage Service が読み取りの際にこの不整合を処理していました。そのため、移行のバックフィル フェーズで、各 HBase クラスタのスナップショットを作成し、Bigtable にインポートすることにしましたが、スナップショットをオーバーレイすべきか、別々のクラスタにインポートすべきかわかりませんでした。
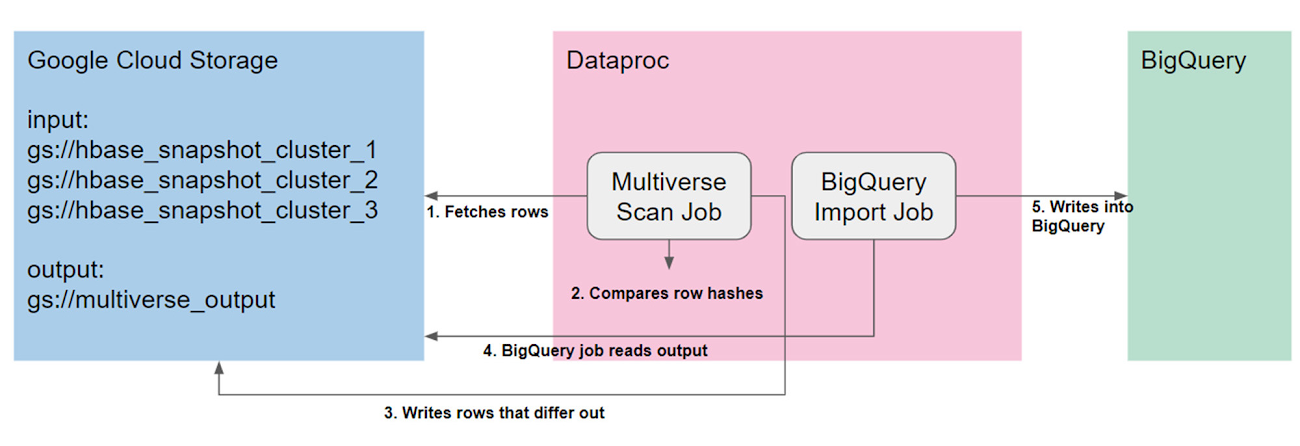
3 つのクラスタを 2 つに統合する方法を決定するために、Google が提供する Multiverse Scan Job を実行しました。これは、HBase テーブルのスナップショットを順次並行してスキャンするカスタマイズされた MapReduce ジョブです。これにより、3 つのテーブルのソートマージ結合を効果的に行い、行とセルを比較して 3 つの HBase クラスタ間の差分を明らかにすることができました。ジョブがテーブル全体をスキャンしている間に、無作為に選ばれた重要な行の 10% が比較されました。このジョブは 160 個の Dataproc ワーカーノードを使用して、4 日間実行されました。それから、分析のために差分を BigQuery にインポートしました。
不整合は次の 3 つのカテゴリに分類されることがわかりました。
HBase クラスタの行が欠落している
HBase クラスタの行は存在するが、列が欠落している
HBase クラスタの行は存在するが、重要ではない列が異なっている
このテストにより、3 つのスナップショットのすべてを 1 つに統合することで、最も整合性のあるコピーを取得でき、また、Bigtable のレプリケーションにより、そのデータをセカンダリ Bigtable クラスタにインポートできると判断できました。これにより、列または行の欠落に関する問題が解決されます。
移行プラン
では、何兆もの行を、稼働中のデータベースに移行するにはどうすればよいでしょうか。私たちは、小規模なデータベースを Bigtable に移行した過去の経験に基づいて、同期による変更を実装することにしました。つまり、HBase を変更するにしたがって、対応する Bigtable の変更も行われるというものです。いずれかの手順が失敗した場合、リクエスト全体が失敗とみなされるため、アトミック性が保証されます。たとえば、HBase への書き込みが成功すると、Bigtable への書き込みを発行して、オペレーションをシリアル化します。これにより、HBase と Bigtable への書き込みの合計まで、書き込みのレイテンシが増加することになりました。ただし、この両方のデータベースに並行して書き込みを行うと、Box の Storage Service に複雑なロジックが導入されてしまうため、これは許容可能なトレードオフであると判断しました。
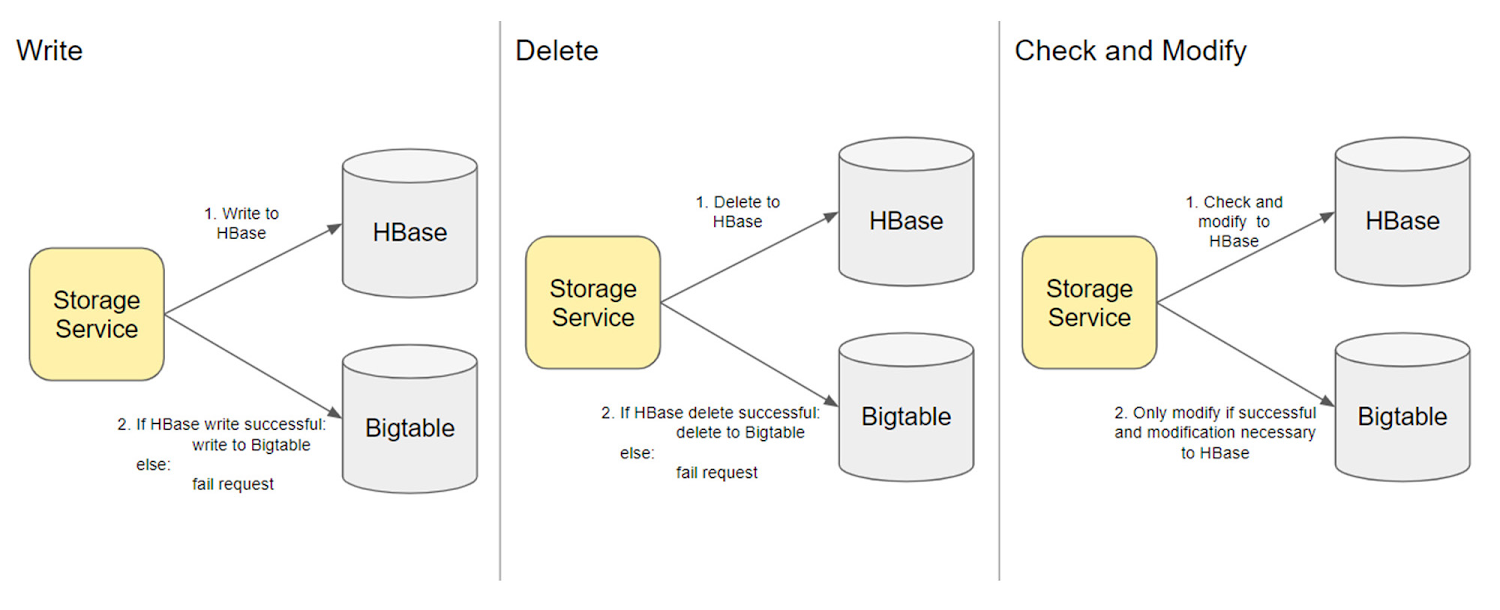
複雑さを 1 つ挙げるとすれば、Box の Storage Service が多くのチェックおよび変更のオペレーションを実行することでした。移行中は Bigtable がバックフィルされないため、Bigtable の方でこれらをミラーリングできないことから、チェックおよび変更のオペレーションが HBase のチェックおよび変更と異なるものになってしまいます。そのため、HBase のチェックおよび変更の結果に依拠し、HBase のチェックおよび変更が成功した場合にのみ変更を行うことにしました。
展開プラン
同期による変更を安全に展開するには、割合とリージョンの両面でこれを制御する必要がありました。たとえば、あるリージョンの展開プランは次のようなものでした。
1% リージョン 1
5% リージョン 1
25% リージョン 1
50% リージョン 1
100% リージョン 1
同期による変更により、Bigtable にすべての新しいデータが書き込まれるよう手配できました。ただし、まだ古いデータのバックフィルが残っています。同期による変更を 1 週間行い、不安定性がないことを確認した後、3 つの HBase スナップショットを取得してインポート フェーズに移る準備が整いました。
Bigtable インポート: データのバックフィル
私たちは、それぞれが 200 TB もある 3 つの HBase スナップショットを抱えていました。Google が提供する Dataproc Import Job を使用して、これらを Bigtable にインポートする必要がありました。私たちは Bigtable クラスタのパフォーマンスに全面的に依存していたので、このジョブは慎重に実行する必要がありました。Bigtable クラスタが過負荷になると、ユーザー トラフィックのレイテンシが増加するという顧客への悪影響がすぐに現れます。実際、スナップショットが非常に大きかったため、パフォーマンスの問題を回避するために、Bigtable クラスタを 500 ノードにスケールアップしました。そこから、各スナップショットを順番にインポートし始めました。このサイズのインポートはまったく経験したことがなかったので、Dataproc クラスタのサイズを徐々に増やし、Bigtable のユーザー トラフィックのレイテンシをモニタリングすることで、インポートの速度を調整しました。
検証
Bigtable からの読み取りに依拠する前に、一連の検証を行う必要がありました。いずれかの行が正しくない場合、顧客に悪影響を与える可能性があります。クラスタのサイズから、すべての行で逐一検証を行うことは不可能でした。代替案として、移行に対する信頼が得られるように、検証に 3 つの別々のアプローチを採用しました。
1. 非同期読み取り検証: オプティミスティックな顧客ダウンロード主導の検証
読み取りごとに、非同期で Bigtable から読み取り、ログと指標を追加して、差分があれば通知されるようにしました。このアプローチの 1 つの注意点は、多数の読み取りを行った直後に更新が行われることです。このアプローチでは、HBase の読み取りと Bigtable の読み取りの間に発生した変更によるすべての差分が表面化するため、多くのノイズが生み出されました。
この読み取り検証中に、Bigtable の正規表現スキャンが HBase の正規表現スキャンと異なることがわかりました。1 つは、Bigtable がサポートする正規表現の比較演算子は「等しい」のみだということです。また、HBase とは異なり、Bigtable の正規表現は「.」(別途指定されていない限り、改行を除く任意の文字)を扱う RE2 を使用します。そのため、Bigtable スキャン用に特定の正規表現を展開し、期待される結果が返されていることを検証する必要がありました。
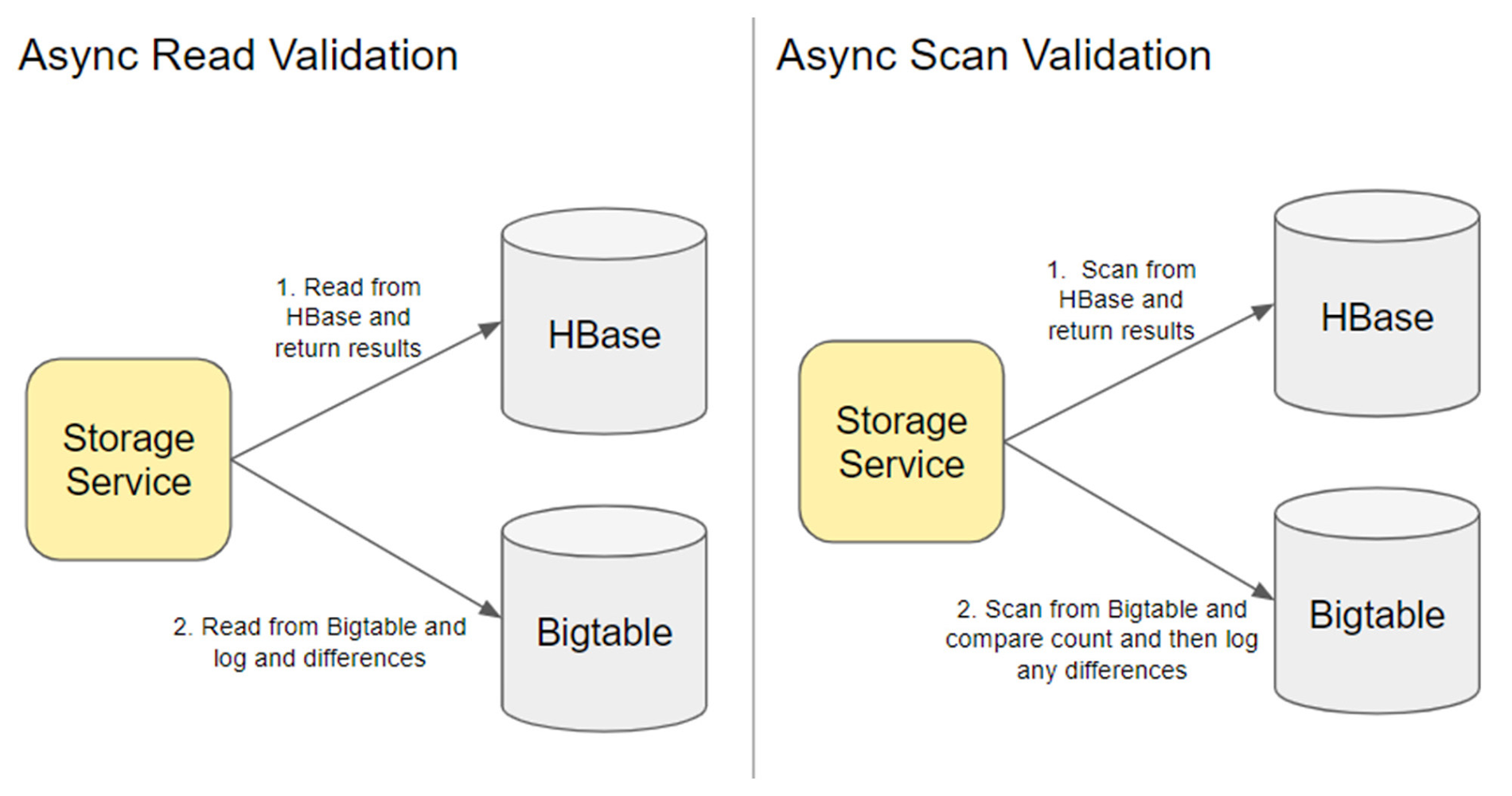
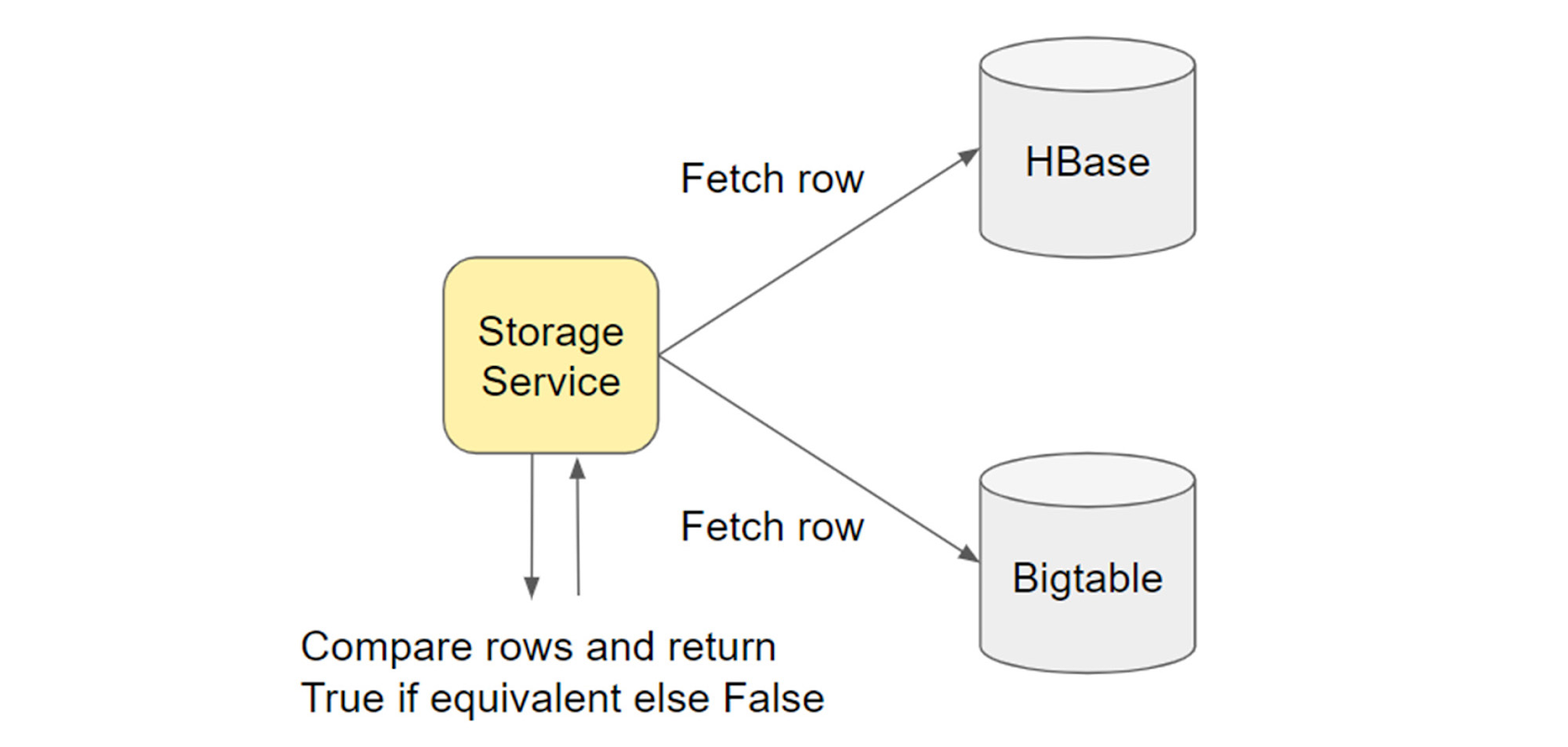
2. 同期の検証: Bigtable と HBase 間でハッシュを比較して Dataproc ジョブを実行する
この検証ジョブ(類似の例はこちら)では、Bigtable と HBase の行全体でハッシュを比較しました。行の 3% をサンプルとして比較したところ、0.1% の不一致が明らかになりました。この不一致を印刷して分析しました。この不一致のほとんどは、特定の列へのオプティミスティックな変更によるものであり、再インポートや修正は必要ないことがわかりました。
3. 顧客視点の検証
私たちは、データベース レベルの検証ではなく、アプリケーション レベルの検証を行って、顧客に表示される内容を確認したいと考えました。
そこで、オブジェクトをキューに入れるファイルシステム全体をスキャンするジョブを作成しました。Bigtable と HBase のエントリを比較する Storage Service のエンドポイントをそのオブジェクトで呼び出します。詳細については、こちらの Box ブログの投稿をご覧ください。
この検証は、同期検証ジョブの出力を支持し、上記で説明されていない差分は見つかりませんでした。
Bigtable への切り替え
以上のすべての検証により、HBase ではなく Bigtable から読み取りを返すことへの自信が得られました。なんらかのデータをロールバックする必要がある場合に備えて、HBase に対する同期による二重の変更をバックアップとして維持しました。Bigtable データのみを返した後、ようやく HBase への変更をオフにする準備が整いました。この時点で、Bigtable が信頼できる情報源になりました。
Bigtable のメリット
Bigtable への移行を完了して享受したメリットを次に示します。
開発スピード
Bigtable クラスタのスケールアップとスケールダウンを完全に制御できるようになったので、CPU とストレージの使用率パラメータに応じてクラスタを自動的に増減させる Bigtable 自動スケーリングを有効にしました。これまで、物理ハードウェアでこれを行うことはできませんでした。これにより、私たちのチームは顧客に影響を与えることなく迅速に開発できるようになりました。
私たちのチームでは、データベースの管理に関連するオーバーヘッドが大幅に削減されました。以前は、セキュリティ パッチを実行するために、定期的に HBase トラフィックを移動する必要がありました。今では、そうした管理について心配する必要がまったくなくなりました。
さらに、以前は数日かかっていた MapReduce ジョブが、24 時間以内に完了するようになりました。
コストの節約
Bigtable を導入する前は、完全に複製された 3 つのクラスタを実行していました。Bigtable を使用すれば、すべてのリクエストを受け入れる 1 つのプライマリ クラスタと、プライマリ クラスタに問題が発生した場合に使用できる複製された 1 つのセカンダリ クラスタを実行できます。さらに、障害復旧の場合、セカンダリ クラスタは、チームがデータ分析ジョブを実行するうえで非常に役立ちます。
また、自動スケーリングを使用すれば、ジョブの実行が必要になって初めてスケーリングが行われるため、その時点までセカンダリ クラスタをより軽く実行できます。セカンダリ クラスタは、プライマリ クラスタよりも 25% 少ないノードで実行されます。HBase を使用していたときは、3 つのクラスタのサイズはどれも均等でした。
新しい分析ツール
すべての HBase MapReduce ジョブを Bigtable に移行したところ、既存のジョブにわずかな構成変更を加えただけで、Bigtable が同等の機能を提供してくれることがわかりました。
Bigtable のおかげで、Google Cloud エコシステムも使用できるようになりました。
Bigtable を外部 BigQuery ソースとして追加できました。これにより、HBase では実現できなかったリアルタイムでのテーブルのクエリ実行が可能になりました。このアプリケーションは、当社の小さなテーブルに最適でした。CPU 使用率に影響があるため、本番環境の Bigtable クラスタでクエリを実行する場合は注意が必要ですが、アプリ プロファイルを使用して、トラフィックをセカンダリ クラスタに分離することができます。
大きなテーブルについては、Dataproc ジョブを介して BigQuery にインポートすることにしました。これにより、余分なジョブを実行することなく、アドホック分析データを取得できるようになりました。さらに、BigQuery へのクエリ実行は、MapReduce ジョブを実行するよりもはるかに高速です。
まとめると、Bigtable への移行は大仕事でしたが、得られたすべてのメリットを考えると、移行して本当によかったと思っています。
Bigtable への移行をお考えではありませんか?移行と Google Cloud でサポートされているツールについて詳しくは、以下をご覧ください。
HBase レプリケーションや HBase ミラーリング クライアントなどのライブ マイグレーション ツールを確認する
移行ガイドで詳細な手順を確認する
Box のプレゼンテーションを見る: Box が最小限の労力とダウンタイムで NoSQL データベースをどのようにモダナイズしたか
- Box、シニア ソフトウェア エンジニア Mindy Yang 氏
- Google Cloud、シニアスタッフ SWE Yamini Allu