OpenX: クラウド データベースの活用で 1 日あたり 1,500 億件を超える広告リクエストを処理
Google Cloud Japan Team
※この投稿は米国時間 2021 年 4 月 7 日に、Google Cloud blog に投稿されたものの抄訳です。
編集者注: 広告技術プロバイダの OpenX は Google Cloud に移行したことで、Bigtable と Memorystore for Memcached を組み合わせた、スケーラブルで信頼性が高く、費用対効果の高いソリューションを見い出しました。本稿では、同社がこの移行を決めた理由とその方法についてご説明します。
業界最大の独立系アド エクスチェンジを運営している OpenX は、広告サーバーのデータとリアルタイム入札エクスチェンジを標準のサプライサイド プラットフォームと組み合わせた統合プラットフォームを開発しました。これにより、広告バイヤーがあらゆる取引においてリアルタイムで最高値を獲得できるようにしています。OpenX は、30,000 を超えるブランド、1,200 を超えるウェブサイト、2,000 を超えるプレミアム モバイルアプリにサービスを提供しています。
Google Cloud に移行したのは、時間を節約し、スケーラビリティを向上させて、世界中のより多くの地域でサービスを提供できるようにするためです。Google Cloud への移行に伴い、サポートが終了した状態で残されていた既存のオープンソース データベースを置き換えることも検討しました。そしてこれが、クラウドベースのソリューションを模索するきっかけとなりました。Google Cloud の Cloud Bigtable と Memorystore for Memcached を組み合わせたことで、必要としていたパフォーマンス、スケーラビリティ、費用対効果を得られました。
サポート対象外となったデータベースからの移行
OpenX は以前、オンプレミスでホストされていました。インフラストラクチャには、メインのオープンソース Key-Value データベースがバックエンドに含まれていて、低レイテンシと高パフォーマンスを実現していました。しかし、ベンダーが市場から撤退したため、商業的サポートがないままテクノロジーだけが残っていました。このことが、クラウドに移行して、使いやすく安定性に優れ、予測しやすいデータ クラウド ソリューションを手に入れるための大きな一歩を踏み出すきっかけとなりました。
私たちにとって、パフォーマンスは非常に重要な考慮事項でした。アクティブなウェブユーザーの使用パターンを把握するために、従来の Key-Value データベースを使用していました。更新リクエストよりも GET リクエストの割合が高いため、主な要件は以前と同様に低レイテンシであることでした。たとえば、データベース リクエストは、P99(99 パーセンタイル)で 10 ミリ秒以内に処理される必要があります。予想中央値は 5 ミリ秒未満ですが、時間が短いほど収益は向上します。
スケーラビリティも重要な考慮事項でした。しかし、従来のデータベースでは十分なスケーラビリティを得られませんでした。クラスタはトラフィックの処理で上限に達してしまい、比較的大きな 2 つのクラスタ間での外部シャーディングが必要でした。ノード数が上限に達してしまったため、このデータベースの 1 つのインスタンスで 1 つのリージョンのトラフィックを処理することができませんでした。
クラウドベースのソリューションを求めて
データベースは OpenX にとってミッション クリティカルであるため、次のソリューションを選択することは非常に重要な決定でした。フルマネージドかつスケーラブルな NoSQL データベースである Cloud Bigtable は、今では当社のネイティブ インフラストラクチャとなった Google Cloud 上でホストされ使用できるサービスなので、非常に魅力的でした。また、移行後は可能な場合はマネージド サービスを活用することも方針としました。この場合、Google Kubernetes Engine(GKE)上で Key-Value ストアを運用すること(インストール、更新、最適化など)に価値を見出せませんでした。それは、私たちのプロダクトに直接価値を加える行為ではないからです。
そのため、新しい Key-Value ストアが必要でしたが、クラウド移行は非常にタイトなスケジュールで進んでいたため、すぐに見つける必要がありました。私たちは、コンピュータ サイエンスにおいて最も引用されている論文の一つである、Bigtable について書かれた基礎論文を読み感銘を受けていたので、Bigtable についてまったく知識がなかったわけではありません。また、Google 自体も検索やマップなどの独自のソリューションで Bigtable を活用していることを知り、OpenX でも大いに期待できると考えました。
OpenX で処理する広告リクエストは、1 日あたり 1,500 億件以上、1 秒あたりの平均は 100 万件です。そのため、私たちにとって、レスポンス タイムとスケーラビリティはどちらもビジネス クリティカルな要素です。手始めに、確かな概念実証を作成し、Bigtable をさまざまな側面からテストして、P99 と P50 が要件を満たすことを確認しました。さらに Bigtable では、スケーラビリティの心配はありません。
データのソース
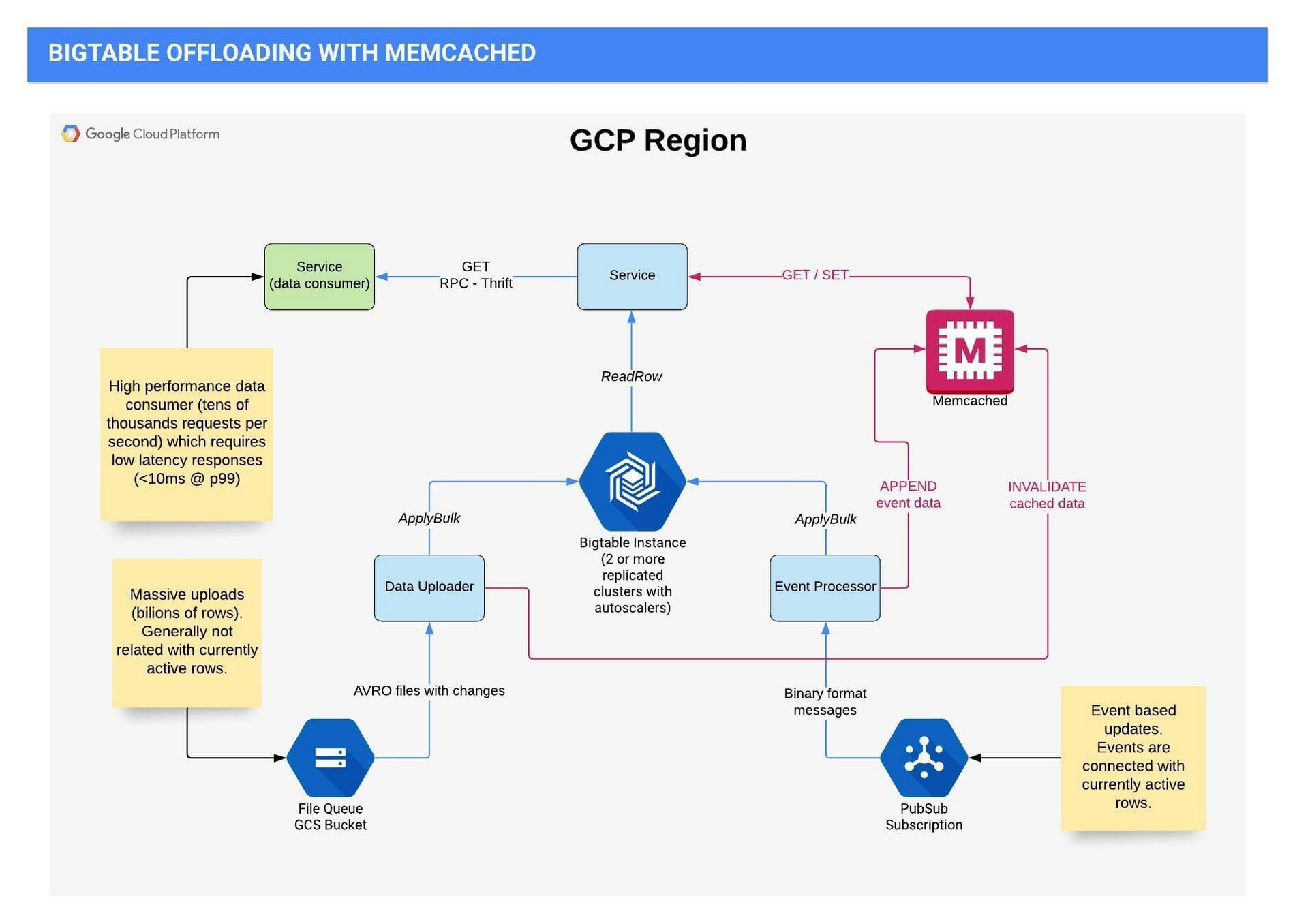
各リージョンには、サービスのための Bigtable インスタンスが 1 つあり、少なくとも 2 つの複製クラスタと独立したオートスケーラー(この両方のクラスタに書き込むため)が含まれています。データは、2 つの非常に異なるフローで Bigtable に入ります。
最初のフローでは、ユーザーベースのアクティビティ、ページビュー、Cookie の同期などのイベントベースの更新を処理します。これらのイベントは、現在アクティブな行に接続されます。Bigtable の更新は、更新された Cookie を使って行います。このプロセスでは更新に重点が置かれるため、通常このイベントの処理中は、Bigtable からデータを読み取る必要がありません。イベントは Pub/Sub に発行されて、GKE 上で処理されます。
2 つめのフローでは、Cloud Storage からの数十億行という大量のアップロードを管理します。これには、ほかの OpenX チームや外部ソースからのバッチ処理の結果が含まれます。
読み取りを実行するのは、広告リクエストを受け取ったときです。このブログの後半では、Memorystore for Memcached から提供されるさまざまな数値を見ていきますが、ここで説明するのは、Memcached を使用する以前のことで、読み取りの件数は書き込みの 15~20 倍でした。
次の図は、上で説明したフローの現在のアーキテクチャを示します。
すべてが自動的に行われる
各テーブルには、少なくとも 10 億行が含まれています。Bigtable を介して利用できる列ファミリーは、列ごとに異なる保持ポリシー、読み取る内容、管理方法を設定できるため、非常に柔軟で使いやすいものです。一部のファミリーでは、時間とバージョン番号に基づいて厳密な保持期間を定義しているため、値が更新されると古いデータが自動的に消えるように設定されています。
当社のトラフィック パターンは、この業界によくあるパターンです。つまり、日中は徐々に増加していき、夜に減少に転じます。これに対応するため、自動スケーリングを使用しています。私たちのユースケースでは、自動スケーリングの使用は簡単ではありません。第一に、私たちは広告ブローカーのためにデータを迅速に取得する必要があります。このため、データベースからデータを読み取るリクエストを処理することがビジネスの最優先事項となります。Bigtable への書き込みを行う GKE コンポーネントと、Bigtable の両方を使用していますが、GKE のスケーリングが速すぎると、Bigtable に送信される書き込みが多すぎて、読み取りのパフォーマンスに影響を及ぼす可能性があります。この問題は、GKE コンポーネントを少しずつゆっくりとスケールアップし、非同期メッセージ サービスである Pub/Sub からのメッセージを利用する速度を実質的に制限することで解決しました。これにより、Bigtable に使用しているオープンソースのオートスケーラーの起動と動作が可能になります。必然的に、このプロセスは GKE スケーリングよりもわずかに時間がかかります。これはいわば、ウォーターフォール式の自動スケーリングです。
この時点で、レスポンス タイムの中央値は約 5 ミリ秒でした。95 パーセンタイルは 10 ミリ秒未満で、99 パーセンタイルは概して 10~20 ミリ秒でした。これでも十分に良い結果でした。しかし Bigtable チームおよび GCP Professional Services Organization の協力を受けた後、Google Cloud ツールボックスの別のツールを活用することで、さらに優れたパフォーマンスを実現できる可能性を感じました。
Memorystore for Memcached の活用によりコストの 50% を節約
Cloud Memorystore は Google のインメモリ データストア サービスで、パフォーマンスの向上、レスポンス タイムの削減、コスト全体の最適化を行うために当社が選んだソリューションです。私たちは、Bigtable の前にキャッシュ レイヤを追加する手法を取りました。そこで Memorystore for Memcached を利用して別の POC を作成し、キャッシュ時間の調査とテストを行い、非常に有益な結果を得られました。
Memorystore をキャッシュ レイヤとして使用したことで、中央値と P75 を Memcached のレスポンス タイムに近い値である 1 ミリ秒未満にまで減らすことができました。P95 と P99 も減少しました。もちろん、レスポンス タイムはリージョンやワークロードで変わりますが、全体的に大幅な改善がみられました。
Memorystore を利用することで、Bigtable へのリクエスト数も最適化できました。今では、GET リクエストの 80% 以上が Memorystore からデータを取得し、Bigtable からは 20% 未満です。データベースへのトラフィックの減少は、Bigtable インスタンスのサイズの縮小にもつながりました。
Memorystore により、Bigtable のノード数を 50% 以上も減らすことができたのです。この結果、Bigtable と Memorystore の両方に対して支払う料金の合計は、以前 Bigtable だけに支払っていた料金よりも 50% 少なくなりました。Bigtable と Memorystore を組み合わせて利用することで、以前のデータベースの問題から脱し、低レイテンシと高パフォーマンスを実現するスケーラブルなマネージド ソリューションによって、当社を成長軌道に乗せることができました。
OpenX について詳しくは、ウェブサイトをご覧ください。Memorystore for Memcached について詳しくは、Memorystore for Memcached がキャッシュを強化する仕組みをご覧ください。
謝辞(敬称略): Grzegorz Łyczba、Mateusz Tapa、Dominik Walter、Jarosław Stropa、Maciej Wolny、Damian Majewski、Bartłomiej Szysz、Michał Ślusarczyk、そして OpenX エンジニアリング チームの他のメンバーの並々ならぬ努力がなければ、このソリューションを完成させることはできませんでした。また、私たちをサポートしてくれた Google の戦略的クラウド エンジニアである Radosław Stankiewicz 氏にも深くお礼を申し上げます。
-OpenX テクニカル リード Bogusław Gorczyca

